Выравнивание последовательностей
Выра́внивание после́довательностей — биоинформатический метод, основанный на размещении двух или более последовательностей мономеров ДНК, РНК или белков друг под другом таким образом, чтобы можно было легко увидеть сходные участки в этих последовательностях. Сходство первичных структур двух молекул может отражать их функциональные, структурные или эволюционные взаимосвязи[1]. Выровненные последовательности оснований нуклеотидов или аминокислот обычно представляются в виде строк матрицы. Добавляются разрывы между основаниями таким образом, чтобы одинаковые или похожие элементы были расположены в следующих друг за другом столбцах матрицы[2].
Алгоритмы выравнивания последовательностей также используются в NLP[3].
Графическое и текстовое представление
В большинстве представлений результата выравнивания последовательности располагаются в строчках матрицы таким образом, что совпадающие элементы (нуклеотиды или аминокислоты) находятся один под другим (в одной колонке). «Разрывы» заменяются знаком «-», именуемый гэпом (от англ. «gap»)[4], и обозначает индель[англ.], то есть место возможной вставки или делеции[5][2].
Текстовое представление
При текстовом отображении возможна просто запись в формате fasta, когда последовательности записываются с гэпами, и имеют одинаковую длину[6]. Такой вид записи часто используется программами, и удобен для машинной обработки[7].
Другой вид текстового представления служит для удобства пользователя (три разных примера представлены ниже). В нём последовательности записываются одна под другой, а в строчке между ними разными символами обозначены разные отношения между аминокислотами. Пробелом (отсутствием символа) обозначают отсутствие связи между аминокислотами, как по гомологии, так и по функции: символами «*», "|" или же буквой (BLAST) — одинаковые аминокислоты; «:» или «+» — близкие по свойствам; «.» — сходные по свойствам[8].
Blast:
Query 15 FQQAWANPKHAWAQVNGETRLTQNLIILERETR 47
F W PKHA +QVNG T ++Q+ IIL R R
Sbjct 14 FHHNWTRPKHASSQVNGHTEMSQHNIILRRVPR 46
CLUSTAL:
THE12851.1 MGKKGYKRNEYNNPFQQAWANPKHAWAQVNGETRLTQNLIILERETRKRS- 50
WP_104057486.1 MSTK-DQLDPQSQAFHHNWTRPKHASSQVNGHTEMSQHNIILRRVPRSGRR 50
*..* : : .: *:: *:.**** :****.*.::*: ***.* *.
EMBOSS Needle:
THE12851.1 1 MGKKGYKRNEYNNPFQQAWANPKHAWAQVNGETRLTQNLIILERETRKRS 50
|..|. :.:..:..|...|..||||.:||||.|.::|:.|||.|..|...
WP_104057486. 1 MSTKD-QLDPQSQAFHHNWTRPKHASSQVNGHTEMSQHNIILRRVPRSGR 49
Графическое представление
Графическое представление максимально ориентированно на визуальное восприятие. В нём также принято размещать последовательности одну под другой, но значение связи между аминокислотами из разных последовательностей обозначаются цветом. Есть окраски по свойствам аминокислот, такие как «Zappo», окрашивающая каждую аминокислоту, и «Clustal», окрашивающая столбцы с одинаковыми свойствами аминокислот. Часть окрасок, такие как «%Identity», позволяет увидеть идентичность и консервативность аминокислот в столбце. Есть и окраски, показывающие степень гидрофобности аминокислот[10].
Наиболее известные программы для просмотра выравниваний: Jalview[англ.][9], UGENE[11], MEGA[англ.][12]. Полный список представлен в статье «List of alignment visualization software» (англ).
Также существует способ представления консенсусной последовательности — Логотип последовательности[13].
Точечная матрица
Точечная матрица сходства[англ.] — способ визуального представления парного выравнивания. Обычно используется для больших последовательностей, например для геномов бактерий. По осям отложены координаты обеих последовательностей, а отрезками отображают их гомологию. Так, точечная матрица одинаковых последовательностей будет выглядеть как диагональ квадрата. Такой способ представления позволяет отслеживать инверсии, дупликации или делеции, а также транслокации[14].
Парное выравнивание
Парное выравнивание используется для нахождения сходных участков двух последовательностей. Различают глобальное и локальное выравнивание. Глобальное выравнивание предполагает, что последовательности гомологичны по всей длине. В глобальное выравнивание включаются обе входные последовательности целиком. Локальное выравнивание применяется, если последовательности содержат как родственные (гомологичные), так и неродственные участки. Результатом локального выравнивания является выбор участка в каждой из последовательностей и выравнивание между этими участками[15].
Для получения парного выравнивания используются разновидности метода динамического программирования. В частности, эти алгоритмы реализованы в сервисах европейской молекулярно-биологической лаборатории (Pairwise Sequence Alignment. EMBL-EBI.). Так, например, Needle., алгоритм глобального выравнивания, использует алгоритм Нидлмана — Вунша[16], а Water., алгоритм локального выравнивания — алгоритм Смита — Ватермана[16].
Сравнение глобального и локального выравниваний
Для демонстрации в чём отличие глобального и локального выравниваний, можно рассмотреть искусственный пример. Возьмём последовательности A и B, и сделаем для них глобальное и локальное выравнивание. В последовательности был заложен центральный гомологичный участок, и заметно отличающиеся края.

Глобальное выравнивание[15] использует полную длину обеих последовательностей, и может быть использовано для проверки последовательностей на гомологию (общность происхождения) по всей длине. Однако, если последовательности имеют мало участков гомологии (или просто схожести), то не всегда можно хорошо определить эти участки. В приведённом примере алгоритм зацепился за четыре совпадающий аминокислоты, так что длинный участок гомологии не виден. На основании этого можно предположить, что последовательности целиком не гомологичны между собой[17].
Локальное выравнивание[15] использует части последовательностей, на которых прогнозируется максимальная гомология. Оно отлично подходит, если лишь части последовательностей похожи, например в ходе рекомбинации или конвергентной эволюции. Всегда стоит аккуратно относиться к небольшим участкам имеющим низкое сходство, особенно при выравнивании больших последовательностей, так как повышается вероятность встречи случайного схожего участка. В примере на рисунке локальное выравнивание включило половину длины последовательностей. Выравнено 11 аминокислот сходных по функции, имеется 2 инделя. На основании этого, если дополнительно известно о схожей функции пептидов A и B, можно сказать, что центральные участки обоих пептидов выполняет функцию всего пептида, либо же важны для его функции[18].
Однако, не всегда в локальное выравнивание может попасть интересующий участок последовательности. Это можно обойти, если обрезать последовательность по границам интересующего участка. Также возможны и другие комбинации глобального и локального выравниваний[19].
Алгоритмы поиска
Применяются для поиска в больших базах данных последовательностей, схожих с некой заданной последовательностью по указанным критериям. Применяемое выравнивание — локальное. Для повышения скорости поиска используются различные эвристические методы. Наиболее известные программы: BLAST[20] и FASTA3x.[21].
Множественное выравнивание
Множественное выравнивание — это выравнивание трёх и более последовательностей. Применяется для нахождения консервативных участков в наборе гомологичных последовательностей. В большинстве случаев построение множественного выравнивания — необходимый этап реконструкции филогенетических деревьев. Нахождение оптимального множественного выравнивания методом динамического программирования имеет слишком большую временную сложность, поэтому множественные выравнивания строятся на базе различных эвристик. Наиболее известные программы, осуществляющие множественное выравнивание — Clustal (clustal.)[22], T-COFFEE[англ.] (tcoffee.), MUSCLE[англ.] (muscle.)[23] и MAFFT[англ.] (mafft.). Имеются также программы для просмотра и редактирования множественных выравниваний, например Jalview[англ.][9] или русскоязычный UGENE[11].
Структурное выравнивание
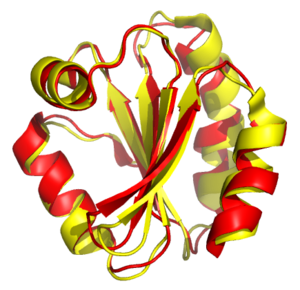
Может быть построено для белков или рибонуклеиновых кислот с использованием информации о вторичной и третичной пространственной структуре молекул. Целью является попытка установить гомологию двух или нескольких структур путём нахождения и сопоставления участков, одинаково уложенных в пространстве. Структурное выравнивание обычно сопровождается наложением структур, то есть нахождением движений пространства, применение которых к заданным молекулам наилучшим образом совмещает их. Но в отличие от простой пространственной суперпозиции с известным сопоставлением эквивалентных аминокислотных остатков двух структур, алгоритмы структурного выравнивания обычно не требуют априорного знания выравнивания последовательностей. Существует большое количество алгоритмов, на которых основаны различные программы структурного выравнивания[англ.]. Пространственные выравнивания особенно важны для анализа данных структурной геномики и протеомики, они также могут использоваться для оценки выравниваний, полученных путём сравнения последовательностей.[24].
Структурное выравнивание успешно используется для сравнения белков с низким уровнем гомологии последовательностей, когда эволюционные связи не могут быть установлены стандартными методами выравнивания последовательностей, но в этом случае необходимо принимать во внимание влияние конвергентной эволюции, основной эффект которой проявляется в сходстве третичных структур неродственных аминокислотных последовательностей[25].
Пространственное выравнивание позволяет сравнивать две и более молекулы с известными трёхмерными структурами, экспериментальное получение которых основано на использовании методов рентгеноструктурного анализа и ЯМР-спектроскопии. Для пространственного выравнивания можно также использовать структуры, полученные методами предсказания структуры белка. Более того, оценка качества таких предсказаний зачастую базируется на использовании пространственного выравнивания структуры создаваемой модели и белка, третичная структура которого получена непосредственно из эксперимента. Также есть данные об использовании метода малоуглового рентгеновского рассеяния для анализа трёхмерных структур различных белковых молекул[26].
Типы сравнений
Результатом работы программ структурного выравнивания, как правило, является совмещение наборов координат атомов. Чаще всего при поиске такого сопоставления оценка результату даётся исходя из значения функции наименьшего среднеквадратического отклонения (RMSD) между структурами, которое алгоритм построения выравнивания старается минимизировать.[27]
- ,

где — количество точек (атомов) в выборке (структуре), и — атомы соответствующей структуры, имеющие координаты , , и , , .









Значение RMSD выражается в единицах длины, наиболее часто используемой единицей в структурной биологии является Ангстрем (Å), который равен 10−10 м. Однако RMSD как степень пространственного расхождения выравниваемых структур имеет ряд недостатков: неустойчивость к выбросам и наличию нескольких доменов в структуре выравниваемых белков, так как изменения в относительном расположении этих доменов между двумя структурами могут искусственно изменять значение RMSD.
Кроме того, могут быть рассчитаны и более сложные параметры, оценивающие структурное сходство, например, тест глобальных расстояний[англ.][28].
Для создания структурного выравнивания и подсчёта соответствующих значений RMSD могут быть использованы как все атомы, входящие в молекулу белка, так и их подмножества. Например, атомы боковых радикалов аминокислотных остатков учитываются не всегда, и для выравнивания могут использоваться только атомы, входящие в пептидный остов молекулы. Такой вариант выбирают, если у выравниваемых структур очень разная аминокислотная последовательность и боковые радикалы различаются у большого числа остатков. По этой причине по умолчанию методы пространственного выравнивания используют только атомы остова, вовлечённые в пептидную связь. Для большего упрощения и увеличения эффективности часто используется положение только альфа-атомов углерода, так как их положение достаточно точно определяет положение атомов полипептидного остова. Только при выравнивании очень похожих или даже идентичных структур важно учитывать позиции атомов боковых цепей. В этом случае RMSD отражает не только схожесть конформации белкового остова, но и ротамерные состояния боковых цепей. Другие способы, позволяющие снизить шум и увеличить число правильных сопоставлений, используют разметку элементов вторичной структуры, карты нативных контактов[англ.] или паттерны взаимодействия остатков, меры степени упаковки боковых цепей и меры сохранения водородных связей[29].
Методы
DALI
Одним из популярных методов структурного выравнивания является DALI (англ. distance alignment matrix method — метод с использованием матрицы дистанционных выравниваний). Исходные структуры белков разбиваются на гексапептиды и через оценку паттернов контактов между фрагментами рассчитывается матрица расстояний. Элементы вторичной структуры, остатки которых являются соседними в последовательности, оказываются на главной диагонали матрицы; остальные диагонали матрицы отражают пространственные контакты между остатками, которые в последовательности не находятся рядом друг с другом. Когда матрицы расстояний двух белков имеют одинаковые или похожие элементы примерно на одинаковых позициях, можно сказать, что белки имеют схожую укладку и их элементы вторичной структуры соединены петлями примерно одинаковой длины. Непосредственный процесс выравнивания DALI заключается в поиске схожестей матриц, построенных для двух белков, которые потом пересобираются в конечное выравнивание с помощью стандартного алгоритма максимизации счёта[30].
Метод DALI был использован для создания базы данных FSSP[англ.] (англ. Families of Structurally Similar Proteins), в которой все известные структуры белков были попарно выровнены для определения их пространственного родства и классификации укладок[31].
DaliLite является скачиваемой программой, использующей алгоритм DALI[32].
Комбинаторное расширение (combinatorial extension)
Метод комбинаторного расширения (англ. Combinational extension (СЕ)) похож на DALI тем, что тоже разбивает каждую структуру на ряд фрагментов, которые затем пытается заново собрать в полное выравнивание. Серия попарных сочетаний фрагментов, называемых AFP (англ. aligned fragment pairs — пары выровненных фрагментов), используется для задания матрицы сходства, через которую прокладывается оптимальный путь для определения конечного выравнивания. Путь, соответствующий выравниванию, рассчитывается как оптимальный путь через матрицу сходства с помощью линейного прохода через последовательности, расширяя выравнивание следующей возможной AFP с высоким счётом. Только те AFP, которые удовлетворяют заданным критериям локального сходства, включаются в матрицу, что сокращает необходимое пространство поиска и увеличивает эффективность[33].
Подобно DALI или SSAP, CE использовался для создания базы данных классификации укладок на основе известных пространственных структур белков из PDB[34].
Примечания
- ↑ Mount DM. Bioinformatics: Sequence and Genome Analysis (англ.). — 2nd. — Cold Spring Harbor Laboratory Press: Cold Spring Harbor, NY., 2004. — ISBN 0-87969-608-7.
- ↑ 1 2 Basic Local Alignment Search Tool (BLAST) // Bioinformatics and Functional Genomics. — Hoboken, NJ, USA: John Wiley & Sons, Inc.. — С. 100—138. — ISBN 9780470451496, 9780470085851.
- ↑ Bill MacCartney, Michel Galley, Christopher D. Manning. A phrase-based alignment model for natural language inference // Proceedings of the Conference on Empirical Methods in Natural Language Processing - EMNLP '08. — Morristown, NJ, USA: Association for Computational Linguistics, 2008. — doi:10.3115/1613715.1613817.
- ↑ Julie D. Thompson, Desmond G. Higgins, Toby J. Gibson. CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice // Nucleic Acids Research. — 1994. — Т. 22, вып. 22. — С. 4673—4680. — ISSN 1362-4962 0305-1048, 1362-4962. — doi:10.1093/nar/22.22.4673.
- ↑ INDEL Mutation - MeSH - NCBI. www.ncbi.nlm.nih.gov. Дата обращения: 29 апреля 2019.
- ↑ Aligned FASTA Format. www.cgl.ucsf.edu. Дата обращения: 29 апреля 2019. Архивировано 24 января 2021 года.
- ↑ Alignment Formats. emboss.sourceforge.net. Дата обращения: 30 апреля 2019. Архивировано 24 июня 2018 года.
- ↑ Bioinformatics Tools FAQ - Job Dispatcher Sequence Analysis Tools - EMBL-EBI. www.ebi.ac.uk. Дата обращения: 23 апреля 2019. Архивировано 23 апреля 2019 года.
- ↑ 1 2 3 4 A. M. Waterhouse, J. B. Procter, D. M. A. Martin, M. Clamp, G. J. Barton. Jalview Version 2--a multiple sequence alignment editor and analysis workbench (англ.) // Bioinformatics. — 2009-05-01. — Vol. 25, iss. 9. — P. 1189—1191. — ISSN 1460-2059 1367-4803, 1460-2059. — doi:10.1093/bioinformatics/btp033. Архивировано 24 октября 2017 года.
- ↑ Colour Schemes. www.jalview.org. Дата обращения: 23 апреля 2019. Архивировано 26 апреля 2019 года.
- ↑ 1 2 Mikhail Fursov, Olga Golosova, Konstantin Okonechnikov. Unipro UGENE: a unified bioinformatics toolkit (англ.) // Bioinformatics. — 2012-04-15. — Vol. 28, iss. 8. — P. 1166—1167. — ISSN 1367-4803. — doi:10.1093/bioinformatics/bts091. Архивировано 30 апреля 2019 года.
- ↑ Koichiro Tamura, Joel Dudley, Masatoshi Nei, Sudhir Kumar. MEGA: A biologist-centric software for evolutionary analysis of DNA and protein sequences (англ.) // Briefings in Bioinformatics. — 2008-07-01. — Vol. 9, iss. 4. — P. 299—306. — ISSN 1467-5463. — doi:10.1093/bib/bbn017. Архивировано 30 апреля 2019 года.
- ↑ Thomas D. Schneider, R.Michael Stephens. Sequence logos: a new way to display consensus sequences // Nucleic Acids Research. — 1990. — Т. 18, вып. 20. — С. 6097—6100. — ISSN 1362-4962 0305-1048, 1362-4962. — doi:10.1093/nar/18.20.6097.
- ↑ Erik L.L. Sonnhammer, Richard Durbin. A dot-matrix program with dynamic threshold control suited for genomic DNA and protein sequence analysis (англ.) // Gene[англ.]. — Elsevier, 1995-12. — Vol. 167, iss. 1—2. — P. GC1—GC10. — ISSN 0378-1119. — doi:10.1016/0378-1119(95)00714-8. Архивировано 2 декабря 2008 года.
- ↑ 1 2 3 Valery O Polyanovsky, Mikhail A Roytberg, Vladimir G Tumanyan. Comparative analysis of the quality of a global algorithm and a local algorithm for alignment of two sequences (англ.) // Algorithms for Molecular Biology. — 2011. — Vol. 6, iss. 1. — P. 25. — ISSN 1748-7188. — doi:10.1186/1748-7188-6-25. Архивировано 23 апреля 2019 года.
- ↑ 1 2 Pairwise Sequence Alignment Tools < EMBL-EBI. www.ebi.ac.uk. Дата обращения: 23 апреля 2019. Архивировано 12 апреля 2019 года.
- ↑ Aloysius J. Phillips. Homology assessment and molecular sequence alignment // Journal of Biomedical Informatics. — 2006-02. — Т. 39, вып. 1. — С. 18—33. — ISSN 1532-0464. — doi:10.1016/j.jbi.2005.11.005.
- ↑ M. C. Frith. Finding functional sequence elements by multiple local alignment (англ.) // Nucleic Acids Research. — 2004-01-02. — Vol. 32, iss. 1. — P. 189—200. — ISSN 1362-4962. — doi:10.1093/nar/gkh169. Архивировано 22 июля 2017 года.
- ↑ M. Brudno, S. Malde, A. Poliakov, C. B. Do, O. Couronne. Glocal alignment: finding rearrangements during alignment // Bioinformatics. — 2003-07-03. — Т. 19, вып. Suppl 1. — С. i54—i62. — ISSN 1460-2059 1367-4803, 1460-2059. — doi:10.1093/bioinformatics/btg1005.
- ↑ BLAST: Basic Local Alignment Search Tool. blast.ncbi.nlm.nih.gov. Дата обращения: 23 апреля 2019. Архивировано 21 августа 2020 года.
- ↑ W. R. Pearson, D. J. Lipman. Improved tools for biological sequence comparison (англ.) // Proceedings of the National Academy of Sciences. — National Academy of Sciences, 1988-04-01. — Vol. 85, iss. 8. — P. 2444—2448. — ISSN 1091-6490 0027-8424, 1091-6490. — doi:10.1073/pnas.85.8.2444.
- ↑ J. Thompson. The CLUSTAL_X windows interface: flexible strategies for multiple sequence alignment aided by quality analysis tools // Nucleic Acids Research. — 1997-12-15. — Т. 25, вып. 24. — С. 4876—4882. — ISSN 1362-4962. — doi:10.1093/nar/25.24.4876.
- ↑ R. C. Edgar. MUSCLE: multiple sequence alignment with high accuracy and high throughput // Nucleic Acids Research. — 2004-03-08. — Т. 32, вып. 5. — С. 1792—1797. — ISSN 1362-4962. — doi:10.1093/nar/gkh340.
- ↑ Zhang Y., Skolnick J. The protein structure prediction problem could be solved using the current PDB library. (англ.) // Proceedings of the National Academy of Sciences of the United States of America. — 2005. — Vol. 102, no. 4. — P. 1029—1034. — doi:10.1073/pnas.0407152101. — PMID 15653774.
- ↑ Zhang, Y.; Skolnick, J. Automated structure prediction of weakly homologous proteins on a genomic scale (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 2004. — May. — doi:10.1073/pnas.0305695101. — PMID 15126668. — PMC 419651.
- ↑ GL Hura; AL Menon. Robust, high-throughput solution structural analyses by small angle X-ray scattering (SAXS) (англ.) // Nature Methods : journal. — 2009. — July. — doi:10.1038/nmeth.1353. — PMID 19620974. — PMC 3094553.
- ↑ Cohen, F.E; Sternberg, M.J. On the prediction of protein structure: the significance of the root-mean-square deviation (англ.) // Journal of molecular biology[англ.] : journal. — 1980. — doi:10.1016/0022-2836(80)90289-2. — PMID 7411610.
- ↑ Zemla A. LGA: A method for finding 3D similarities in protein structures. (англ.) // Nucleic acids research. — 2003. — Vol. 31, no. 13. — P. 3370—3374. — PMID 12824330.
- ↑ Godzik A. The structural alignment between two proteins: is there a unique answer? (англ.) // Protein science : a publication of the Protein Society. — 1996. — Vol. 5, no. 7. — P. 1325—1338. — doi:10.1002/pro.5560050711. — PMID 8819165.
- ↑ Liisa Holm; Laura M. Laakso. Dali server update (англ.) // Nature Methods : journal. — 2016. — 29 April. — doi:10.1093/nar/gkw357. — PMID 27131377. — PMC 4987910.
- ↑ Holm L., Sander C. Dali/FSSP classification of three-dimensional protein folds. (англ.) // Nucleic acids research. — 1997. — Vol. 25, no. 1. — P. 231—234. — PMID 9016542.
- ↑ Holm L., Park J. DaliLite workbench for protein structure comparison. (англ.) // Bioinformatics. — 2000. — Vol. 16, no. 6. — P. 566—567. — PMID 10980157.
- ↑ Shindyalov I. N., Bourne P. E. Protein structure alignment by incremental combinatorial extension (CE) of the optimal path. (англ.) // Protein engineering. — 1998. — Vol. 11, no. 9. — P. 739—747. — PMID 9796821.
- ↑ Prlic A., Bliven S., Rose P. W., Bluhm W. F., Bizon C., Godzik A., Bourne P. E. Pre-calculated protein structure alignments at the RCSB PDB website. (англ.) // Bioinformatics. — 2010. — Vol. 26, no. 23. — P. 2983—2985. — doi:10.1093/bioinformatics/btq572. — PMID 20937596.
| Меры схожести строк | |
|---|---|
| Поиск подстроки | |
| Палиндромы | |
| Выравнивание последовательностей | |
| Суффиксные структуры | |
| Другое | |