Вероя́тность — степень возможности наступления некоторого события. Когда основания для того, чтобы какое-нибудь возможное событие произошло в действительности, перевешивают противоположные основания, то это событие называют вероятным, в противном случае — маловероятным или невероятным. Перевес положительных оснований над отрицательными, и наоборот, может быть в различной степени, вследствие чего вероятность бывает большей либо меньшей. Поэтому часто вероятность оценивается на качественном уровне, особенно в тех случаях, когда более или менее точная количественная оценка невозможна или крайне затруднена. Возможны различные градации «уровней» вероятности.
t-критерий Стьюдента — общее название для класса методов статистической проверки гипотез, основанных на распределении Стьюдента. Наиболее частые случаи применения t-критерия связаны с проверкой равенства средних значений в двух выборках.

Метод наименьших квадратов (МНК) — математический метод, применяемый для решения различных задач, основанный на минимизации суммы квадратов отклонений некоторых функций от искомых переменных. Он может использоваться для «решения» переопределенных систем уравнений, для поиска решения в случае обычных нелинейных систем уравнений, для аппроксимации точечных значений некоторой функции. МНК является одним из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным.
Статистический критерий — математическое правило, в соответствии с которым принимается или отвергается та или иная статистическая гипотеза с заданным уровнем значимости. Построение критерия представляет собой выбор подходящей функции от результатов наблюдений, которая служит для выявления меры расхождения между эмпирическими значениями и гипотетическими.

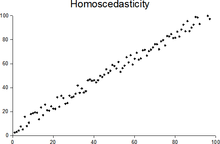
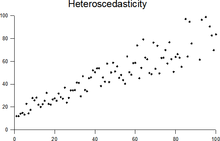
Гетероскедасти́чность — понятие, используемое в прикладной статистике, означающее неоднородность наблюдений, выражающуюся в неодинаковой (непостоянной) дисперсии случайной ошибки регрессионной (эконометрической) модели. Гетероскедастичность противоположна гомоскедастичности, означающей однородность наблюдений, то есть постоянство дисперсии случайных ошибок модели.
Фа́кторный анализ — многомерный метод, применяемый для изучения взаимосвязей между значениями переменных. Предполагается, что известные переменные зависят от меньшего количества неизвестных переменных и случайной ошибки.
Линейная регрессия — используемая в статистике регрессионная модель зависимости одной переменной  от другой или нескольких других переменных
от другой или нескольких других переменных  с линейной функцией зависимости.
с линейной функцией зависимости.
Авторегрессионная условная гетероскедастичность — применяемая в эконометрике модель для анализа временных рядов, у которых условная дисперсия ряда зависит от прошлых значений ряда, прошлых значений этих дисперсий и иных факторов. Данные модели предназначены для «объяснения» кластеризации волатильности на финансовых рынках, когда периоды высокой волатильности длятся некоторое время, сменяясь затем периодами низкой волатильности, причём среднюю волатильность можно считать относительно стабильной.
Стандартные ошибки в форме Уайта или состоятельные при гетероскедастичности стандартные ошибки — применяемая в эконометрике оценка ковариационной матрицы МНК-оценок параметров линейной модели регрессии, которая состоятельна при гетероскедастичности случайных ошибок модели, альтернативная стандартной (классической) оценке, которая в данном случае является несостоятельной.
Стандартные ошибки в форме Ньюи-Уеста или состоятельные при гетероскедастичности и автокорреляции стандартные ошибки — применяемая в эконометрике оценка ковариационной матрицы МНК-оценок параметров линейной модели регрессии, альтернативная стандартной (классической) оценке, которая состоятельна при гетероскедастичности и автокорреляции случайных ошибок модели.
Тест Уайта — универсальная процедура тестирования гетероскедастичности случайных ошибок линейной регрессионной модели, не налагающая особых ограничений на структуру гетероскедастичности, предложенная Уайтом в 1980 г. Тест является асимптотическим.
Тест Голдфелда — Квандта — процедура тестирования гетероскедастичности случайных ошибок регрессионной модели, применяемая в случае, когда есть основания полагать, что стандартное отклонение ошибок может быть пропорционально некоторой переменной. Тест также основывается на предположении нормальности распределения случайных ошибок регрессионной модели. Фактически это F-тест, поскольку статистика теста имеет распределение Фишера.
Тест Бройша — Пагана или Бреуша — Пагана — один из статистических тестов для проверки наличия гетероскедастичности случайных ошибок регрессионной модели. Применяется, если есть основания полагать, что дисперсия случайных ошибок может зависеть от некоторой совокупности переменных. При этом в данном тесте проверяется линейная зависимость дисперсии случайных ошибок от некоторого набора переменных.
Вне́шне несвя́занные уравне́ния — система эконометрических уравнений, каждое из которых является самостоятельным уравнением со своей зависимой и объясняющими экзогенными переменными. Модель предложена Зельнером в 1968 году. Важной особенностью данных уравнений является то, что несмотря на кажущуюся несвязанность уравнений их случайные ошибки предполагаются коррелированными между собой.
Тест ранговой корреляции Спирмена — непараметрический статистический тест, позволяющий проверить гетероскедастичность случайных ошибок регрессионной (эконометрической) модели. Особенность теста заключается в том, что не конкретизируется форма возможной зависимости дисперсии случайных ошибок модели от той или иной переменной.

Преобразование данных — это применение детерминированной математической функции к каждой точке множества данных, то есть каждая точка данных zi заменяется преобразованным значением  , где f — функция. Преобразования обычно применяются так, что данные больше подходят для процедуры статистического вывода, которую хотят применять, для улучшения интерпретируемости или для графического представления.
, где f — функция. Преобразования обычно применяются так, что данные больше подходят для процедуры статистического вывода, которую хотят применять, для улучшения интерпретируемости или для графического представления.

Компромисс отклонение-дисперсия в статистике и в машинном обучении — это свойство набора моделей предсказания, когда модели с меньшим отклонением от имеющихся данных имеют более высокую дисперсию на новых данных, и наоборот. Компромисс отклонение-дисперсия — конфликт при попытке одновременно минимизировать эти два источника ошибки, которые мешают алгоритмам обучения с учителем делать обобщение за пределами тренировочного набора.
- Смещение — это погрешность оценки, возникающая в результате ошибочного предположения в алгоритме обучения. В результате большого смещения алгоритм может пропустить связь между признаками и выводом (недообучение).
- Дисперсия — это ошибка чувствительности к малым отклонениям в тренировочном наборе. При высокой дисперсии алгоритм может как-то трактовать случайный шум в тренировочном наборе, а не желаемый результат (переобучение).