Задача классифика́ции — задача, в которой множество объектов (ситуаций) необходимо разделить некоторым образом на классы, при этом задано конечное множество объектов, для которых известно, к каким классам они относятся (выборка), но классовая принадлежность остальных объектов неизвестна. Для решения задачи требуется построить алгоритм, способный классифицировать произвольный объект из исходного множества, то есть указать, к какому классу он относится.

IBM Watson — суперкомпьютер фирмы IBM, оснащённый системой искусственного интеллекта, созданный группой исследователей под руководством Дэвида Феруччи. Его создание — часть проекта DeepQA. Основная задача Уотсона — понимать вопросы, сформулированные на естественном языке, и находить на них ответы с помощью ИИ. Назван в честь первого президента IBM Томаса Уотсона.
Синхронный автоматический перевод — «моментальный» машинный перевод речи, с одного естественного языка на другой, с помощью специальных программных и технических средств. Так же называется направление научных исследований, связанных с построением подобных систем.

Ян Лекун — французский и американский учёный в области информатики, основные сферы деятельности — машинное обучение, компьютерное зрение, мобильная робототехника и вычислительная нейробиология. Известен работами по применению нейросетей к задачам оптического распознавания символов и машинного зрения. Один из основных создателей технологии сжатия изображений DjVu. Вместе с Леоном Боту создал язык программирования Lush.
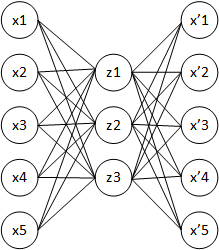
Автокодировщик — специальная архитектура искусственных нейронных сетей, позволяющая применять обучение без учителя при использовании метода обратного распространения ошибки. Простейшая архитектура автокодировщика — сеть прямого распространения, без обратных связей, наиболее схожая с перцептроном и содержащая входной слой, промежуточный слой и выходной слой. В отличие от перцептрона, выходной слой автокодировщика должен содержать столько же нейронов, сколько и входной слой.
Глубокое обучение — совокупность методов машинного обучения, основанных на обучении представлениям, а не специализированных алгоритмах под конкретные задачи. Многие методы глубокого обучения были известны ещё в 1980-е, но результаты не впечатляли, пока продвижения в теории искусственных нейронных сетей и вычислительные мощности середины 2000-х годов не позволили создавать сложные технологические архитектуры нейронных сетей, обладающие достаточной производительностью и позволяющие решать широкий спектр задач, не поддававшихся эффективному решению ранее, например, в компьютерном зрении, машинном переводе, распознавании речи, причём качество решения во многих случаях теперь сопоставимо, а в некоторых превосходит эффективность человека.
Нейро́нный проце́ссор — это специализированный класс микропроцессоров и сопроцессоров, используемый для аппаратного ускорения работы алгоритмов искусственных нейронных сетей, компьютерного зрения, распознавания по голосу, машинного обучения и других методов искусственного интеллекта.
Отбор признаков — процесс отбора подмножества значимых признаков для построения модели в машинном обучении. Отбор признаков используется по четырём причинам:
- упрощение модели для повышения интерпретируемости
- для сокращения времени обучения
- во избежание проклятия размерности
- улучшение обобщающей способности модели и борьба с переобучением.
PyTorch — фреймворк машинного обучения для языка Python с открытым исходным кодом, созданный на базе Torch. Используется для решения различных задач: компьютерное зрение, обработка естественного языка. Разрабатывается преимущественно группой искусственного интеллекта Facebook. Также вокруг этого фреймворка выстроена экосистема, состоящая из различных библиотек, разрабатываемых сторонними командами: PyTorch Lightning и Fast.ai, упрощающие процесс обучения моделей, Pyro, модуль для вероятностного программирования, от Uber, Flair, для обработки естественного языка и Catalyst, для обучения DL и RL моделей.
Снижение размерности в задачах статистики, машинного обучения и теории информации — набор техник преобразования данных, направленных на уменьшение числа переменных путём выявления главных переменных; в общем случае может быть разделено на отбор признаков и выделение признаков. Снижение размерности наборов данных позволяет снизить требуемое время и требуемую память для обработки набора, улучшить скорость моделей машинного обучения за счёт удаления мультиколлинеарности, проще представить данные визуально.
Обучение признакам или обучение представлениям — это набор техник, которые позволяют системе автоматически обнаружить представления, необходимые для выявления признаков или классификации исходных (сырых) данных. Это заменяет ручное конструирование признаков и позволяет машине как изучать признаки, так и использовать их для решения специфичных задач.
Автоматическое машинное обучение (AutoML) — процесс автоматизации сквозного процесса применения машинного обучения к задачам реального мира. В типичном приложении машинного обучения пользователь должен применить подходящие методы предварительной обработки данных, конструирования признаков, выделения признаков и выбора признаков, которые делают набор данных пригодным для машинного обучения. После этих шагов работник должен осуществить выбор алгоритма и оптимизацию гиперпараметров для максимизации прогнозируемой производительности конечной модели. Поскольку многие из этих шагов не могут осуществить люди, не будучи экспертами, был предложен подход AutoML как основанное на искусственном интеллекте решение для всё возрастающей необходимости применения машинного обучения. Автоматизация сквозного процесса применения машинного обучения даёт преимущество получения более простых решений, более быстрого создания таких решений и моделей, которые часто превосходят модели, построенные вручную.
Оптимизация гиперпараметров — задача машинного обучения по выбору набора оптимальных гиперпараметров для обучающего алгоритма.
Признак в машинном обучении — индивидуальное измеримое свойство или характеристика наблюдаемого явления. Выбор информативных, отличительных и независимых признаков является критическим шагом для эффективных алгоритмов в распознавании образов, классификации и регрессии. Признаки обычно являются числовыми, но структурные признаки, такие как строки и графы, используются в синтаксическом распознавании образов. Понятие «признака» связано с объясняющими переменными, используемыми в статистических техниках, таких как линейная регрессия.
Выделение признаков — это разновидность абстрагирования, процесс снижения размерности, в котором исходный набор исходных переменных сокращается до более управляемых групп (признаков) для дальнейшей обработки, оставаясь при этом достаточным набором для точного и полного описания исходного набора данных. Выделение признаков используется в машинном обучении, распознавании образов и при обработке изображений. Выделение признаков начинает с исходного набора данных, выводит вторичные значения (признаки), для которых предполагается, что они должны быть информативными и не быть избыточными, что способствует последующему процессу машинного обучения и обобщению шагов, а в некоторых случаях ведёт и к лучшей человеческой интерпретацией данных.
Бустинг — ансамблевый метаалгоритм машинного обучения, применяется главным образом для уменьшения смещения, а также дисперсии в обучении с учителем. Также определяется как семейство алгоритмов машинного обучения, преобразующих слабые обучающие алгоритмы в сильные.
Ансамблевое обучение — техника машинного обучения, использующая несколько обученных алгоритмов с целью получения лучшей предсказательной эффективности, чем можно было бы получить от каждого алгоритма по отдельности. В отличие от статистического ансамбля в статистической механике, который обычно бесконечен, ансамбль моделей в машинном обучении состоит из конкретного конечного множества альтернативных моделей, но обычно позволяет существовать гораздо более гибким структурам.
ONNX — открытая библиотека программного обеспечения для построения нейронных сетей глубокого обучения. С помощью ONNX ИИ-разработчики могут обмениваться моделями между различными инструментами и выбирать наилучшую комбинацию этих инструментов. ONNX разрабатывается и поддерживается совместно компаниями Microsoft, Facebook, Amazon и другими партнерами как проект с открытым исходным кодом.

ML.NET — бесплатная открытая библиотека со средствами машинного обучения для языков программирования C# и F#. Она также поддерживает модели на Python при использовании совместно с NimbusML. Предварительный выпуск ML.NET включал в себя решения для конструирования признаков, двоичной и мультиклассовой классификаций, регрессионного анализа. Позже были добавлены дополнительные задачи машинного обучения: выявление аномалий и рекомендательные системы. Глубокое обучение и прочие подходы ожидаются в предстоящих версиях.

MLOps или ML Ops — набор практик, нацеленных на надежное и эффективное развертывание и поддержание моделей машинного обучения на производстве. Слово является смесью слов "машинное обучение" (ML) и практик непрерывной разработки — DevOps в области программного обеспечения. Модели машинного обучения тестируются и разрабатываются в изолированных экспериментальных системах. Когда алгоритм готов к запуску, MLOps используется учеными в области данных, DevOps, и инженерами машинного обучения для его доставки в производственные системы. Также как при использовании DevOps или DataOps подходах, MLOps нацелен на рост автоматизации и улучшения качества производственных моделей, в то же время фокусируясь на бизнес и нормативных требованиях. Хотя MLOps начинался как набор самых лучших практик, он медленно эволюционировал в независимый подход к управлению жизненного цикла машинного обучения. Практики MLOps применяются к целому жизненному циклу — от интеграции c генерацией модели, непрерывной интеграцией/непрерывной доставкой, оркестровкой, и развертыванием, до метрик состояния, диагностики, управления и бизнеса. Согласно компании Gartner, MLOps является подмножеством ModelOps. Он сфокусирован на операционализации моделей машинного обучения, в то время как ModelOps охватывает операционализацию всех типов моделей искусственного интеллекта (AI).