Коэффициент вариации

Не путать с коэффициентом детерминации.
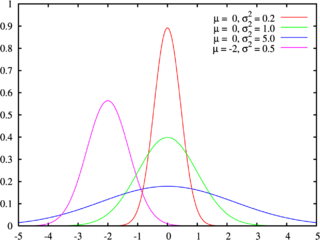
В теории вероятностей и статистике коэффициент вариации, также известный как относительное стандартное отклонение, — это стандартная мера дисперсии распределения вероятностей или частотного распределения. Она часто выражается в процентах и определяется как отношение стандартного отклонения σ к среднему μ. КВ или ОСО широко используются в аналитической химии для выражения точности и повторяемости анализа. Они также часто применяются в инженерии и физике, при проведении исследований по обеспечению качества. Кроме того, КВ используется экономистами и инвесторами в экономических моделях.
Определение
Коэффициент вариации определяется как отношение стандартного отклонения σ к среднему μ:

Он показывает степень изменчивости по отношению к среднему показателю выборки. Коэффициент вариации следует вычислять только для данных, измеренных на шкале отношений, то есть шкал, которые имеют значимый нуль и, следовательно, допускают относительное сравнение двух измерений. Коэффициент вариации может не иметь никакого значения для данных интервальной шкалы. Например, большинство температурных шкал (например, Цельсий, Фаренгейт и т. д.) являются интервальными шкалами с произвольными нулями, поэтому вычисленный коэффициент вариации будет отличаться в зависимости от используемой шкалы. С другой стороны, температура Кельвина имеет значимый нуль, полное отсутствие тепловой энергии, и, таким образом, является шкалой отношения. Говоря простым языком, имеет смысл сказать, что 20 кельвинов в два раза горячее, чем 10 кельвинов, но только в этой шкале с истинным абсолютным нулем. Хотя стандартное отклонение может быть измерено в Кельвинах, градусах Цельсия или Фаренгейта, вычисленное значение применимо только к этой шкале. Только шкала Кельвина может быть использована для вычисления действительного коэффициента вариации.
Измерения, которые распределены логнормально, демонстрируют стационарный КВ; напротив, КОО изменяется в зависимости от ожидаемого значения измерений.
Более надежной возможностью является квартильный коэффициент дисперсии, половина межквартильного диапазона делится на среднее значение квартилей . В большинстве случаев КВ вычисляется для одной независимой переменной (например, для одного фабричного продукта) с многочисленными повторяющимися измерениями зависимой переменной (например, ошибка в производственном процессе). Однако данные, которые являются линейными или даже логарифмически нелинейными и включают непрерывный диапазон для независимой переменной с разреженными измерениями по каждому значению (например, точечная диаграмма), могут поддаваться одиночному вычислению КВ с использованием подхода оценки максимального правдоподобия.
Примеры
Набор данных [100, 100, 100] имеет постоянные значения. Его выборочное стандартное отклонение равно 0, а среднее — 100, что дает коэффициент вариации:

Набор данных [90, 100, 110] имеет бóльшую вариабельность. Его выборочное стандартное отклонение равно 10, а среднее — 100, что дает коэффициент вариации:

Набор данных [1, 5, 6, 8, 10, 40, 65, 88] имеет еще бóльшую изменчивость. Его выборочное стандартное отклонение составляет 32,9, а среднее — 27,9, что дает коэффициент вариации:

Примеры неправильного использования
Сравнение коэффициентов вариации между параметрами с использованием относительных единиц может привести к различиям, которые могут быть нереальными. Если мы сравним один и тот же набор температур в градусах Цельсия и Фаренгейта (обе относительные единицы, где Кельвин и шкала Ранкина являются их соответствующими абсолютными значениями):
По Цельсию: [0, 10, 20, 30, 40]
По Фаренгейту: [32, 50, 68, 86, 104]
Стандартные отклонения составляют 15,81 и 28,46 соответственно. КВ первого набора составляет 15,81 / 20 = 79 %.
Для второго набора (при тех же температурах) он составляет 28,46/68 = 42 %.
Если, например, наборы данных — это показания температуры от двух разных датчиков (датчика со шкалой Цельсия и датчика со шкалой Фаренгейта), и вы хотите знать, какой датчик лучше, выбирая тот, который имеет наименьшее отклонение, то вы будете введены в заблуждение, если используете КВ. Проблема здесь в том, что вы разделили на относительную величину, а не на абсолютную.
Сравнение одного и того же набора данных, теперь в абсолютных единицах:
По Кельвину: [273.15, 283.15, 293.15, 303.15, 313.15]
По Ранкину: [491.67, 509.67, 527.67, 545.67, 563.67]
Стандартные отклонения выборок по-прежнему составляют 15,81 и 28,46 соответственно, поскольку на стандартное отклонение не влияет постоянное смещение. Однако, коэффициенты вариации теперь равны 5,39 %.
С математической точки зрения коэффициент вариации не является полностью линейным. То есть для случайной величины Х, коэффициент вариации aX + b равен коэффициенту вариации X только если b = 0. В приведенном выше примере градусы Цельсия могут быть преобразованы в градусы Фаренгейта только с помощью линейного преобразования формы ax + b с b ≠ 0, в то время как градусы Кельвина можно преобразовать в градусы Ранкина через линейное преобразование ax.
Оценка
Когда доступна только выборка данных из популяции, коэффициент вариации в популяции можно оценить, используя отношение стандартного отклонения выборки s к выборочному среднему значению x:

Но эта оценка, применяемая к небольшой или средней выборке, имеет тенденцию быть слишком не точной: это смещённая оценка. Для нормально распределенных данных несмещенной оценкой для выборки размером n является:

Логнормальные данные
Во многих приложениях можно предположить, что данные распределены логарифмически нормально (об этом свидетельствует наличие асимметрии в выборке данных). В таких случаях более точна оценка, полученная из свойств логнормального распределения, которая определяется как:

где — выборочное стандартное отклонение данных после преобразования натурального логарифма.

Сравнение со стандартным отклонением
Преимущества
Коэффициент вариации полезен, поскольку стандартное отклонение данных всегда должно пониматься в контексте среднего значения данных. В отличие от этого, фактическое значение КВ не зависит от единицы измерения, поэтому оно является безразмерным числом. Для сравнения наборов данных с различными единицами измерения или сильно отличающимися средними величинами следует использовать коэффициент вариации вместо стандартного отклонения.
Недостатки
- Когда среднее значение близко к нулю, коэффициент вариации приближается к бесконечности и поэтому чувствителен к небольшим изменениям среднего. Это часто происходит, если значения не исходят из шкалы отношений
- В отличие от стандартного отклонения, его нельзя использовать непосредственно для построения доверительных интервалов для среднего значения.
Приложения
Коэффициент вариации также распространен в прикладных областях вероятности, таких как теория обновления, теория массового обслуживания и теория надежности. В этих областях экспоненциальное распределение часто важнее нормального распределения. Стандартное отклонение экспоненциального распределения равно его среднему значению, поэтому коэффициент вариации равен 1. Распределения с КВ< 1 (например, распределение Эрланга) считаются с низкой дисперсией, в то время как распределения с КВ > 1 (например, гиперэкспоненциальное распределение) считаются с высокой дисперсией. Некоторые формулы в этих полях выражаются с помощью квадратного коэффициента вариации, часто сокращенного ККВ. По существу, КВ заменяет термин стандартного отклонения на среднеквадратичное отклонение. В то время как многие естественные процессы действительно показывают корреляцию между средним значением и величиной вариации вокруг него, точные сенсорные устройства должны быть сконструированы таким образом, чтобы коэффициент вариации был близок к нулю, то есть давал постоянную абсолютную ошибку в их рабочем диапазоне.
В актуарных расчётах КВ известен как унифицированный риск.
При промышленной переработке твердых частиц КВ особенно важен для измерения степени однородности порошковой смеси. Сравнение рассчитанного КВ со спецификацией позволит определить, достигнута ли достаточная степень смешивания.
Как мера экономического неравенства
Коэффициент вариации удовлетворяет требованиям для измерения экономического неравенства. Если x (с элементами xi) — это список значений экономического показателя (например, богатство), а xi -богатство агента i, то выполняются следующие требования:
1. Анонимность — cv не зависит от упорядоченности списка x. Это следует из того, что дисперсия и среднее значение не зависят от упорядоченности списка x.
2. cv(x)=cv(αx), где α-действительное число.
3. Если {x, x} является списком x, присоединенным к самому себе, то cv ({x, x})=cv (x).
4. Принцип переноса Пигу-Дальтона: когда богатство передается от более богатого агента i к более бедному агенту j (то есть xi > xj) без изменения их ранга, то cv уменьшается и наоборот.
cv принимает свое минимальное значение равное нулю для полного равенства (все xi равны). Наиболее заметным недостатком является то, что он не ограничен сверху, поэтому он не может быть нормализован, чтобы быть в пределах фиксированного диапазона (например, как коэффициент Джини, который ограничен между 0 и 1). Однако он лучше поддается анализу, в отличие от коэффициента Джини.
Распределение
При условии, что отрицательные и малые положительные значения выборочного среднего встречаются с пренебрежимо малой частотой, распределение вероятности коэффициента вариации для выборки размера n было показано Хендриксом и Роби:

где символ ∑ указывает, что суммирование закончено только четными значениями n −1- i, то есть, если n нечетное, сумма над четными значениями i, и если n является четным, сумма только над нечетными значениями i.
Это полезно при построении статистических гипотез или доверительных интервалов. Статистический вывод для коэффициента вариации в нормально распределенных данных часто основан на приближении хи-квадрат Маккея для коэффициента вариации.
Похожие показатели
Стандартизированные моменты представляют собой аналогичные соотношения, , где это k-е моменты относительно среднего, которые также безразмерны и масштабно инвариантны. Отношение дисперсии к среднему, , является еще одним аналогичным отношением, но которое не является безразмерным. Дополнительные соотношения см. в разделе нормализация.



Другие соответствующие коэффициенты включают:

2. Стандартизированный момент,

3. Индекс дисперсии,
4. Фактор Фано,

См. также
Примечания
- ↑ Brian Everitt. The Cambridge dictionary of statistics : [англ.]. — Cambridge University Press, 1988. — P. 67. — 360 p.