Алгоритм сортировки — это алгоритм для упорядочивания элементов в списке. В случае, когда элемент в списке имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки. На практике в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.

Быстрая сортировка, сортировка Хоара, часто называемая qsort — алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром во время его работы в МГУ в 1960 году.
Хеш-функция, или функция свёртки — функция, осуществляющая преобразование массива входных данных произвольной длины в выходную битовую строку установленной длины, выполняемое определённым алгоритмом. Преобразование, производимое хеш-функцией, называется хешированием. Исходные данные называются входным массивом, «ключом» или «сообщением». Результат преобразования называется «хешем», «хеш-кодом», «хеш-суммой», «сводкой сообщения».

Сортировка слиянием — алгоритм сортировки, который упорядочивает списки в определённом порядке. Эта сортировка — хороший пример использования принципа «разделяй и властвуй». Сначала задача разбивается на несколько подзадач меньшего размера. Затем эти задачи решаются с помощью рекурсивного вызова или непосредственно, если их размер достаточно мал. Наконец, их решения комбинируются, и получается решение исходной задачи.
Итератор — интерфейс, предоставляющий доступ к элементам коллекции и навигацию по ним. В различных системах итераторы могут иметь разные общепринятые названия. В терминах систем управления базами данных итераторы называются курсорами. В простейшем случае итератором в низкоуровневых языках является указатель.
Коллекция в программировании — программный объект, содержащий в себе, тем или иным образом, набор значений одного или различных типов, и позволяющий обращаться к этим значениям.

Двоичное дерево поиска — двоичное дерево, для которого выполняются следующие дополнительные условия :
- оба поддерева — левое и правое — являются двоичными деревьями поиска;
- у всех узлов левого поддерева произвольного узла X значения ключей данных меньше либо равны, нежели значение ключа данных самого узла X;
- у всех узлов правого поддерева произвольного узла X значения ключей данных больше, нежели значение ключа данных самого узла X.
Линейный, последовательный поиск — алгоритм нахождения заданного значения произвольной функции на некотором отрезке. Данный алгоритм является простейшим алгоритмом поиска и, в отличие, например, от двоичного поиска, не накладывает никаких ограничений на функцию и имеет простейшую реализацию. Поиск значения функции осуществляется простым сравнением очередного рассматриваемого значения и, если значения совпадают, то поиск считается завершённым.
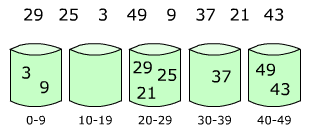
Блочная сортировка — алгоритм сортировки, в котором сортируемые элементы распределяются между конечным числом отдельных блоков так, чтобы все элементы в каждом следующем по порядку блоке были всегда больше, чем в предыдущем. Каждый блок затем сортируется отдельно, либо рекурсивно тем же методом, либо другим. Затем элементы помещаются обратно в массив. Этот тип сортировки может обладать линейным временем исполнения.

Ку́ча в программировании — специализированная структура данных типа дерева, которая удовлетворяет свойству кучи: если  является узлом-потомком узла
является узлом-потомком узла  , то
, то  , где
, где  — ключ (идентификатор) узла. Из этого следует, что элемент с наибольшим значением ключа всегда является корневым узлом кучи, поэтому иногда такие кучи называют max-кучами. Не существует никаких ограничений относительно того, сколько узлов-потомков имеет каждый узел кучи, хотя на практике их число обычно не более двух. Куча является максимально эффективной реализацией абстрактного типа данных, который называется очередью с приоритетом. Кучи имеют решающее значение в некоторых эффективных алгоритмах на графах, таких, как алгоритм Дейкстры на d-кучах и сортировка методом пирамиды.
— ключ (идентификатор) узла. Из этого следует, что элемент с наибольшим значением ключа всегда является корневым узлом кучи, поэтому иногда такие кучи называют max-кучами. Не существует никаких ограничений относительно того, сколько узлов-потомков имеет каждый узел кучи, хотя на практике их число обычно не более двух. Куча является максимально эффективной реализацией абстрактного типа данных, который называется очередью с приоритетом. Кучи имеют решающее значение в некоторых эффективных алгоритмах на графах, таких, как алгоритм Дейкстры на d-кучах и сортировка методом пирамиды.
В информатике временна́я сложность алгоритма определяется как функция от длины строки, представляющей входные данные, равная времени работы алгоритма на данном входе. Временная сложность алгоритма обычно выражается с использованием нотации «O» большое, которая учитывает только слагаемое самого высокого порядка, а также не учитывает константные множители, то есть коэффициенты. Если сложность выражена таким способом, говорят об асимптотическом описании временной сложности, то есть при стремлении размера входа к бесконечности. Например, если существует число  , такое, что время работы алгоритма для всех входов длины
, такое, что время работы алгоритма для всех входов длины  не превосходит
не превосходит  , то временную сложность данного алгоритма можно асимптотически оценить как
, то временную сложность данного алгоритма можно асимптотически оценить как  .
.

В информатике под произвольным доступом понимают возможность обратиться к любому элементу последовательности за равные промежутки времени, не зависящие от размеров последовательности.
Внешняя сортировка — сортировка данных, расположенных на периферийных устройствах и не вмещающихся в оперативную память, то есть когда применить одну из внутренних сортировок невозможно. Стоит отметить, что внутренняя сортировка значительно эффективней внешней, так как на обращение к оперативной памяти затрачивается намного меньше времени, чем к магнитным дискам, лентам и т. п.
Случайная перестановка — это случайное упорядочение множества объектов, то есть случайная величина, элементарными событиями которой являются перестановки. Использование случайных перестановок зачастую является базой в областях, использующих рандомизированные алгоритмы. К таким областям относятся теория кодирования, криптография и моделирование. Хорошим примером случайной перестановки является тасование колоды карт.
Тасование Фишера — Йетса (названо в честь Рональда Фишера и Фрэнка Йейтса, известно также под именем Тасование Кнута , — это алгоритм создания случайных перестановок конечного множества, попросту говоря, для случайного тасования множества. Вариант тасования Фишера — Йетса, известный как алгоритм Саттоло , может быть использован для генерации случайного цикла перестановок длины n. Правильно реализованный алгоритм тасования Фишера — Йетса несмещённый, так что каждая перестановка генерируется с одинаковой вероятностью. Современная версия алгоритма очень эффективна и требует время, пропорциональное числу элементов множества, и не требует дополнительной памяти.

Битонная сортировка — параллельный алгоритм сортировки данных, метод для создания сортировочной сети. Разработан американским информатиком Кеннетом Бэтчером в 1968 году. В основе алгоритма лежит понятие «битонной последовательности». Название было выбрано по аналогии с монотонной последовательностью.
Эффективность алгоритма — это свойство алгоритма, которое связано с вычислительными ресурсами, используемыми алгоритмом. Алгоритм должен быть проанализирован с целью определения необходимых алгоритму ресурсов. Эффективность алгоритма можно рассматривать как аналог производственной производительности повторяющихся или непрерывных процессов.
В информатике префиксная сумма, кумулятивная сумма, инклюзивное сканирование или просто сканирование последовательности чисел x0, x1, x2, … называется последовательность чисел y0, y1, y2, …, являющаяся префиксной суммой от входной последовательности:
- y0 = x0
- y1 = x0 + x1
- y2 = x0 + x1+ x2
- …
Самоорганизующийся список это список, который упорядочивает элементы, основанные на некоторой самоорганизующейся эвристики для улучшения среднего времени доступа. Целью самоорганизующегося списка является повышение эффективности линейного поиска за счет перемещения наиболее часто используемых элементов в начало списка. Самоорганизующийся список в лучшем случае обеспечивает почти постоянное время доступа к элементам. В самоорганизующемся списке используется алгоритм реорганизации для адаптации к различным распределениям запросов во время выполнения.




