Протеомика
Протео́мика (англ. proteomics) — область молекулярной биологии, посвящённая идентификации и количественному анализу белков (иными словами, высокопроизводительному исследованию белков). Термин «протеомика» был предложен в 1997 году[1]. Совокупность всех белков клетки называют протеомом[2].
Объектом изучения протеомики являются белки, которые экспрессируются в клетке, ткани или организме в данный момент времени (то есть протеом). Хотя первые методы протеомики, например, секвенирование белков по Эдману, появились задолго до геномных технологий, действительно высокопроизводительное изучение белков стало возможным только в постгеномную эпоху, то есть при наличии известных нуклеотидных последовательностей геномов разных организмов.
Задачи и значение
После геномики и транскриптомики, протеомика — следующий шаг в изучении биологических систем. Основная задача протеомики заключается в идентификации новых белков и их количественном анализе. Соответственно, протеомика объективно сложнее геномики, так как геном организма в большинстве случаев не меняется в ходе жизни, но совокупность всех его белков изменяется постоянно. Различаются даже протеомы клеток разных типов одного организма. Кроме того, изучение протеома осложняется и другими обстоятельствами, например, посттрансляционными модификациями, которым подвергаются многие белки (изучением посттрансляционных модификаций занимаются разделы протеомики — фосфопротеомика[англ.] и гликопротеомика[англ.]). Для активности многих белков критически необходимы взаимодействия с другими белками и с РНК, что также осложняет их идентификацию. Наконец, некоторые белки существуют так недолго и столь быстро разрушаются, что их очень сложно зафиксировать имеющимися методами[3].
Данные, полученные методом протеомики, могут быть использованы для формирования более глубокого понимания причин возникновения разнообразных заболеваний, например, нейродегенеративных, а также разработки методов лечения. С помощью протеомики осуществляется поиск антигенов, пригодных для создания новых вакцин. Идентификация белков, которые аномально экспрессируются при различных раковых заболеваниях, имеет огромное значение для диагностики с помощью биомаркеров, прогнозирования и лечения рака[4].
Методы
Традиционный подход к изучению белков подразумевает их выделение из тканей и клеток, последующую очистку, в результате чего становится возможным анализировать структуру и функции очищенного белка. Протеомика использует другой подход: всё белковое содержимое клетки можно увидеть и проанализировать в одну стадию. Это стало возможным благодаря появлению и развитию таких методов и технологий, как масс-спектрометрия и двумерный электрофорез. Однако методы протеомики не исчерпываются этими двумя примерами[2]. Ниже рассмотрены использующиеся на данный момент методы исследования белков, в том числе методы количественного анализа и секвенирования аминокислотной последовательности белка, которые на современном этапе используются редко.
Количественный анализ, не требующий информации о структурах белков
Количественный анализ белков с ферментативной активностью можно опосредованно проводить через определение активности[англ.] этих белков. Ещё в начале XX века подобный анализ можно было осуществить с помощью методов спектрофотометрии. При этом количество катализатора оценивается в условных единицах активности. Условные единицы активности до сих пор используют для описания концентрации в крови таких биомаркеров, как аланинаминотрансфераза и аспартатаминотрансфераза. В 1975 году был разработан способ получения моноклональных антител, и они быстро нашли применение в исследовании белков. Например, если известен антиген данного антитела, то с помощью этого антитела можно идентифицировать исследуемый антиген в экспериментальном образце. В медицине в качестве биомаркеров и в XXI веке широко используются антитела, антигены которых неизвестны, но которые связывают у больных людей гораздо больше антигена, чем у здоровых. Например, гликопротеин CA-125 использовали как биомаркер рака яичников с 1981 года, когда были получены антитела к нему. Значительно позднее идентифицировали сам белок — муцин 16[5].
Секвенирование последовательности белка
В 1953 году Фредерик Сенгер определил аминокислотную последовательность гормона инсулина. Для мечения и идентификации N-концевого остатка Сенгер предложил использовать 1-фтор-2,4-динитробензол[англ.]. После связывания с этим реагентом N-концевого остатка белка полипептидную цепь гидролизуют соляной кислотой до отдельных аминокислот и выявляют меченный остаток. Если белок состоит из нескольких полипептидных цепей, то пометятся оба N-концевых остатка, то есть будет установлено число отдельных полипептидных цепей в белке. Для секвенирования всей белковой последовательности чаще применяют метод секвенирования по Эдману[6].
В 1950-х годах шведский химик Пер Эдман[англ.] изобрёл метод определения аминокислотной последовательности белков (секвенирование). Первый этап секвенирования по Эдману — обработка исследуемого пептида изотиоцианатом фенила, который взаимодействует с аминогруппой, давая фенилтиокарбомоильный радикал. При умеренном закислении раствора он отщепляется, захватывая вместе с собой N-концевую аминокислоту. В результате в раствор выходит тиазолинон с радикалом, специфичным для данной аминокислоты. Это производное анализируют хроматографически, определяя, какая аминокислота была на N-конце, и цикл повторяется. Если исследуемый белок закреплён на твёрдой подложке, то после каждой обработки изотиоцианатом фенила его можно промывать, удаляя тиазолинон с N-концевой кислотой, и начинать новый цикл. Метод Эдмана позволяет с высокой точностью определять последовательность длиной до 30 аминокислотных остатков. Высокая чувствительность метода также позволяет секвенировать менее 0,1 нмоль пептида с 99 % точностью. Длина полипептидной цепи, которую можно секвенировать методом Эдмана, зависит от эффективности отдельных стадий, которая, в свою очередь, определяется аминокислотным составом полипептида[7].

В 1960-х годах был создан автоматический секвенатор, реализующий метод Эдмана. Первичную структуру инсулина, на определение которой у Сенгера ушло более 10 лет, в настоящее время можно получить за пару дней прямым секвенированием на белковом секвенаторе[7]. Метод Эдмана сейчас изредка используют при исследовании организмов, геномные последовательности которых неизвестны[8][9][10]. Традиционное секвенирование белков также применяют в тех случаях, когда многие их особенности (например, посттрансляционные модификации) нельзя узнать только лишь из последовательности гена[11].
Большинство белков перед секвенированием необходимо приготовить к нему особым образом. Сначала в белке́ разрушают дисульфидные связи, если они есть, при помощи окисления надмуравьиной кислотой или восстановления дитиотреитолом. Далее белковую цепь дробят на фрагменты протеазами, поскольку секвенирование длинных белков имеет невысокую точность. Обычно для гидролиза используют трипсин, который действует только на те пептидные связи, карбонильная группа которых принадлежит остатку лизина или аргинина. Поэтому, если при полном гидролизе определить число лизиновых и аргининовых остатков в белке, можно предсказать, на сколько фрагментов распадётся белок после обработки трипсином. Полученные фрагменты далее чистят с помощью электрофореза (см. ниже) или хроматографии и секвенируют по Эдману. Чтобы восстановить последовательность белка по фрагментам, его разрезают на куски ферментом, который распознаёт остатки, отличные от тех, которые распознаёт трипсин. На основании перекрытий двух полученных наборов фрагментов восстанавливают полную аминокислотную последовательность белка[12].
Для определения положения дисульфидных связей белок снова расщепляют трипсином, но не разрушая предварительно дисульфидные связи. Образующиеся фрагменты разделяют электрофорезом и сравнивают с набором фрагментов, полученных при первом расщеплении трипсином. Если между двумя фрагментами есть дисульфидная связь, то при разделении первого набора фрагментов они будут выглядеть на геле как две полосы, а при электрофорезе второго образуют единую полосу[13].
Двумерный гель-электрофорез
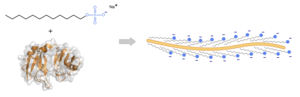

В 1970—1980-х годах достигли расцвета методы выделения и очистки белков. Эти методы сочетали принципы хроматографии, электрофореза и центрифугирования; многие из них давно вышли из употребления, но некоторые используются и в XXI веке. В 1970 году швейцарский учёный Ульрих Лэммли[англ.] предложил метод разделения белков при помощи электрофореза в денатурирующих условиях. Сначала белки подвергали жёсткой денатурации под действием додецилсульфата натрия (англ. sodium dodecyl sulphate, SDS), который в виде слоя покрывал каждую белковую молекулу. Чем больше был белок, тем больше SDS связывалось с ним и тем больший отрицательный заряд приобретал их комплекс. Поэтому при нанесении образцов на полиакриламидный гель они начинали двигаться под действием электрического поля; при этом скорость движения белковых молекул зависит от их массы (более лёгкие белки перемещаются по гелю быстрее). Метод хорошо подходит для разделения белков с массой от 5 до 250 кДа[14].

Метод Лэммли получил дальнейшее развитие. В 1975 году Патрик О’Фарелл и Йоахим Клозе независимо друг от друга предложили принцип так называемого двумерного электрофореза[англ.]: перед разделением по массе с помощью SDS белки предварительно разделяются согласно их изоэлектрической точке. Сначала белки вносят в стеклянную трубку, заполненную особыми полимерами, которые создают в ней неподвижный градиент pH. Белки распределяются по трубке, занимая места, pH которых равен их изоэлектрической точке. Далее содержимое трубки выдавливают и приплавляют к гелю для обычного электрофореза по Лэммли. Таким образом, сначала белки делятся по изоэлектрической точке, а потом по массе. В результате двумерного электрофореза каждому белку соответствует не полоса, как при обычном электрофорезе, а сфокусированное округлое пятно, размер и интенсивность окрашивания которого соответствуют концентрации белка. С помощью двумерного электрофореза можно разделять не только различные белки, но и изоформы одного и того же белка, а также формы белка с разными посттрансляционными модификациями. Были предложены различные усовершенствования методики двумерного электрофореза, некоторые его этапы, а также обработка отсканированных гелей, были автоматизированы. По сути, двумерный электрофорез — единственный способ наглядного представления протеома[15][16][17].
Вестерн-блоттинг

В ряде случаев необходимо установить, с какими клеточными белками взаимодействуют выделенные антитела. Нередко стоит и обратная задача: определить выделенный белок можно с помощью антител, специфически с ним связывающихся. Для этого существует метод вестерн-блоттинга, или иммуноблоттинга. При его применении вначале белки из исследуемого лизата разделяют при помощи гель-электрофореза, а из геля переносят на пористую мембрану. Далее мембрану последовательно обрабатывают антителами, специфичными к искомому белку, и радиоактивно-меченными антителами, связывающимися с первыми антителами. Иногда вместо вторых антител производят ферментативную реакцию с первыми антителами. В результате молекулы искомого белка, распознанные антителами, выявляются как полосы на авторадиограмме или пятна на мембране, по которым можно идентифицировать белок[18][19].
Масс-спектрометрия

Масс-спектрометрия включает ряд методов, которые направлены на определение молекулярной массы исследуемых соединений. Она нашла широкое применение и в биологии, в особенности в протеомике. При применении масс-спектрометрии сначала белки, находящиеся в образце, ионизируют, потом в условиях вакуума ионы сортируются и детектируются, давая на выходе спектр, который дальше анализируется специальными вычислительными методами. В конечном итоге для каждого иона определяется значение отношения массы к заряду. Если заряд иона равен единице, то отношение численно равно его молекулярной массе. Поначалу использование масс-спектрометрии в биологии было ограничено из-за того, что ионизация была очень жёсткой и приводила к разрушению молекул. В 1980-х годах был разработан метод ионизации молекул лазером при их сокристаллизации со светочувствительным органическим веществом (его называют матрицей). Матрица окружает молекулы исследуемого вещества и под действием лазера ионизирует соседние молекулы. В некоторых условиях ионизацию можно провести без разрушения исследуемых молекул. Этот метод получил название опосредованная матрицей лазерная десорбция-ионизация (англ. matrix-assisted laser desorption ionization, MALDI). Новый метод ионизации совместили с обычным масс-спектрометрометрическим детектором (времяпролётным, англ. time-of-flight, TOF). В этом детекторе ионы движутся в вакуумной трубке и достигают чувствительной пластины (фотоэлектронного умножителя), которая и является детектором. Время, за которое ион преодолевает длину трубки, обратно пропорционально его массе. В 1990-е и в начале 2000-х годов метод MALDI-TOF очень активно использовался для исследований белков[20][21].

Из-за особенностей изотопного разделения пики в спектрах больших белков чрезвычайно сложно анализировать. По этой причине перед исследованием их с помощью фермента трипсина разрушают на пептиды массой 500—2500 Да, и затем по данным для пептидов восстанавливают информацию об исходном белке подобно тому, как при секвенировании нуклеиновых кислот нового поколения исходные последовательности собираются из коротких прочтений[англ.]. Этот подход называется «протеомикой снизу вверх[англ.]» (англ. bottom-up). Процесс сборки небезошибочен и приводит к большим потерям информации, поэтому в некоторых случаях исследуются целые белки без расщепления с помощью мощных детекторов сверхвысокого разрешения («протеомика сверху вниз[англ.]», англ. top-down)[22].
Набор молекулярных масс пептидов, которые были получены при обработке белка трипсином, уникален для каждого белка. Это связано в основном с высокой специфичностью трипсина, который вносит разрез только по остаткам лизина и аргинина. Сравнивая полученную картину молекулярных масс пептидов для исследуемого белка с пептидными картами белков из баз данных, можно установить, какой именно белок исследовался. Этот подход получил название пептидной дактилоскопии[23]. Поскольку полного соответствия экспериментального распределения масс пептидов и эталонных пептидных карт достичь невозможно, была введена количественная оценка (англ. score) вероятности того, что экспериментальная пептидная карта соответствует данной теоретической. Для пептидной дактилоскопии были разработаны специальные программы, например, MOWSE[24].
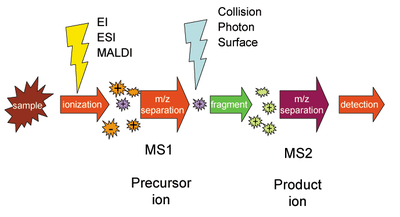
Вместо фрагментации трипсином перед установкой образцов в масс-спектрометр фрагментацию белков на фрагменты можно осуществлять в самом масс-спектрометре, например, при помощи столкновения с молекулами инертных газов. При этом каждый пептид характеризуется массой иона-предшественника и набором масс ионов-фрагментов. Массы фрагментов можно измерить и по ним восстановить информацию об исходном белке, так как молекулярные массы фрагментов можно найти исходя из последовательности пептида. Такой подход получил название тандемной масс-спектрометрии[англ.] (MS-MS). Как и при пептидной дактилоскопии, в тандемной масс-спектрометрии имеет место вероятностная оценка того, что пептидная карта исследуемого белка соответствует одной из теоретических. В 2007 году для анализа данных тандемной масс-спектрометрии был предложен подход target-decoy. Суть этого подхода заключается в том, что при анализе данных к целевым теоретическим пептидам (англ. target — цель) стали добавлять равное количество бессмысленных, фальшивых (англ. decoy — ложная цель) пептидов. Этот подход позволяет оценить качество анализа. Если анализ в качестве лучших соответствий выдаёт соответствие экспериментального белка с заведомо фальшивым, то он даёт ложноположительный результат[англ.], а подход target-decoy позволяет оценить долю ложноположительных результатов[25].

В качестве альтернативы MALDI ионизацию пептидов перед масс-спектрометрией можно осуществлять с помощью метода ионизации электрораспылением, или ионизации электроспреем (англ. electrospray ionisation, ESI). Жидкость, содержащая исследуемые белки, помещается в конический капилляр, а когда она выходит из капилляра, к ней прилагается сильное напряжение. В результате жидкость превращается в аэрозоль, и при испарении частиц аэрозоля в потоке инертного газа заряд может переходить на растворённые в аэрозоле биомолекулы, в том числе белки. При таком способе ионизации биомолекулы не разрушаются. Ионизацию электроспреем можно легко совместить с высокоэффективной жидкостной хроматографией: поток хроматографической фазы с колонки можно направить прямо в капилляр для электрораспыления. Таким образом, масс-спектрометр будет определять массы разделяемых в аналитической колонке молекул. Этот метод обозначают аббревиатурой LC-MS (от англ. англ. liquid chromatography – mass spectrometry)[26]. Идентификация белков в сложном растворе при помощи комбинации масс-спектрометрии и высокоэффективной жидкостной хроматографии получила название протеомики-дробовика, или скорострельной протеомики (англ. shotgun proteomics)[27].
Методы масс-спектрометрии могут быть использованы для направленного обнаружения искомых белков, то есть масс-спектрометр можно настроить таким образом, чтобы он видел только нужный пептид. Для этой цели используют прибор с детектором типа тройного квадруполя[англ.], то есть три одинаковых масс-спектрометра, последовательно передающие друг другу ионы. Первый масс-спектрометр отфильтровывает интересующий пептид, во втором он фрагментируется, а третий регистрирует от 3 до 5 заранее выбранных фрагментов. Количественный анализ производится на основе интенсивности фрагментов. Этот метод известен как мониторинг множественных реакций (англ. multiple reaction monitoring, MRM), или мониторинг выбранных реакций[англ.] (англ. selected reaction monitoring, SRM)[28].
Белок-белковые взаимодействия
Один из наиболее популярных методов изучения белок-белковых взаимодействий — использование дрожжевой двугибридной системы. Для этой цели получают два штамма гаплоидных дрожжей, один из которых исследуемый белок (приманка), а второй — белок, который необходимо проверить на предмет взаимодействия с первым (добыча). Далее гаплоидные клетки сливают с образованием диплоидных клеток дрожжей, экспрессирующих оба белка. Если белки взаимодействуют, то они оба составят транскрипционный фактор, запускающий экспрессию репортёрного гена. Если же взаимодействия между белками нет, то и экспрессия репортёрного гена не запускается. С помощью такого подхода у дрожжей S. cerevisiae при скрининге 6000 клонов добычи против 6000 клонов приманки удалось идентифицировать 691 белок-белковое взаимодействие, из которых только 88 были известны ранее[29]. В XXI веке для исследования белок-белковых взаимодействий применяются и другие методы, такие как плазмонный резонанс[30][31].
На основании данных о белок-белковых взаимодействиях в ряде случаев можно судить о функциях белка. Например, если известно, что белок взаимодействует с несколькими белками одного метаболического пути, вполне вероятно, что он тоже в нём задействован. Карты белковых взаимодействий называют интерактом. Существуют базы данных, хранящие информацию о взаимодействиях белков[32].
Данные о белок-белковых взаимодействий чрезвычайно важны для биологических сетей и системной биологии: они, например, используются при реконструкции сигнальных каскадов[33][34].
Белковые микрочипы
Белковые микрочипы разрабатываются для идентификации определённых белков в образце. По аналогии с ДНК-микрочипами, на твёрдую подложку наносятся очень маленькие капли, содержащие антитела. В каждой капле находятся меченые антитела к одному определённому белку, который добавляется на чип в виде флуоресцентно-меченной[англ.] пробы. После промывки флуоресценция детектируется только в тех каплях, в которых антитела связали исследуемый белок. Вместо антител можно использовать другие молекулы, специфически взаимодействующие с конкретными белками, например, олигонуклеотиды[35]. Белковые микрочипы также можно использовать для обнаружения белок-белковых взаимодействий и определения функций белков. В 2000-е годы белковые микрочипы автоматизированы. Они обладают высокой чувствительностью и требуют совсем небольшого количества исследуемого белка, благодаря чему отличаются экономичностью[36].
Биоинформатика в протеомике
С помощью масс-спектрометрии и чипов можно получить информацию о фрагментах белка, но не о белке целиком. В связи с этим созданы программы, которые из фрагментарных данных масс-спектрометрии и чипов выдают данные о почти полностью собранных из этих фрагментов белков. Эти программы основаны на построении выравниваний фрагментов с известными белками из баз данных UniProt[37] и PROSITE[англ.][38].
В большинстве программ, анализирующих белки, не учитываются их посттрансляционные модификации[39]. Существующие инструменты, определяющие посттрансляционные модификации, имеют лишь предсказательный характер[40].
Вычислительные методы биоинформатики активно используются для изучения белков-биомаркеров. Так, с помощью компьютерных моделей удалось показать интенсивный обмен белками между организмом матери и плодом при беременности, причём для анализа требовался лишь неинвазивный забор крови у матери[41].
Развивается такое направление, как протеогеномика, которая использует методы протеомики для подтверждения данных, полученных из геномных последовательностей[42][43]. Существует также структурная протеомика, которая занимается широкомасштабным исследованием структур белков на основе данных рентгеноструктурного анализа и ЯМР-спектроскопии[44].
Протеомика и системная биология
Последние достижения в количественной протеомике позволяют использовать её для глубокого анализа клеточных систем[33][34]. Описание поведения биологических систем в ответ на разнообразные воздействия (действия внешних факторов, изменения клеточной физиологии в связи с разными фазами клеточного цикла и тому подобные) на уровне изменения белкового состава позволяют глубже понять суть многих биологических процессов. Благодаря этому протеомику, наряду с геномикой, транскриптомикой, эпигеномикой, метаболомикой и другими «-омиками»[англ.], включают в состав нового научного направления — системной биологии. Так, Атлас протеома раковых клеток (англ. The Cancer Proteome Atlas) содержит количественные данные об экспрессии около 200 белков в более чем 4000 проанализированных опухолевых образцах, дополняя Атлас ракового генома (англ. The Cancer Genome Atlas), содержащий геномные и транскриптомные данные для этих белков[45].
Практическое применение
С помощью MALDI-TOF можно определять патогенные микроорганизмы с точностью до родов и видов. Интактные бактериальные клетки наносят на металлическую мишень масс-спектрометра, покрывают матрицей, облучают лазером и получают специфичные профили, которые обученный алгоритм распознаёт по характерным массам[46].
Исследуется возможность использования протеомики для диагностики раковых заболеваний с помощью анализа белковых биомаркеров, а также определения степени злокачественности опухоли. В этом направлении уже достигнуты некоторые успехи. Например, в США разрешено использование разработанного в 2015 году теста Xpresys Lung, который использует таргетную масс-спектрометрию нескольких белков плазмы крови и оценивает степень злокачественности опухолевых узелков в лёгких[47].
Новейшие достижения протеомики — в области масс-спектрометрии, разделении белков органелл и мембранных белков — могут сделать возможными исследование протеома сердца и идентификацию модифицированных белков (а также определять характер их модификации). Данные по протеому сердца помогут понять механизмы разнообразных сердечно-сосудистых заболеваний[48].
Многие лекарственные препараты или сами являются белками, или действуют на определённые белки. Поэтому протеомику взяли на вооружение специалисты, занимающиеся разработкой лекарственных препаратов[англ.]. У большинства фармацевтических компаний есть подразделение, занимающееся протеомикой, или компания-партнёр, специализирующаяся на протеомике. Методы протеомики используют для подтверждения валидности мишеней разрабатываемых препаратов, определения эффективности биомаркеров, изучения механизма действия препарата и его токсичности. Методы протеомики используют, в частности, для поиска противомалярийных препаратов[англ.], которые связываются с пурин-связывающими белками на этапе размножения плазмодия в эритроцитах и выхода из них в кровь[48].
Сравнение протеомов двух организмов (необязательно близкородственных) позволяет выявить как общие для этих двух организмов белки, так и белки, которые обусловливают различия их фенотипов. Такой анализ может давать информацию, полезную для понимания эволюционного процесса[49], а иногда позволяет определить ранее неизвестные функции белков. Например, при помощи сравнительной протеомики были выявлены белки насекомого Nilaparvata lugens[англ.], вовлечённые в процессы, связанные с размножением, чья экспрессия изменяется в ответ на обработку инсектицидами[50].
История
История протеомики начинается с 1950 года, когда Эдман предложил метод секвенирования белков. В 1958 году исследовательская группа Фредерика Сенгера определила аминокислотную последовательность инсулина. В 1959 году зародился метод иммуноанализа[англ.]*, который имеет огромное значение для изучения белков. В 1967 году был создан первый автоматический секвенатор, определяющий аминокислотные последовательности белков по методу Эдмана. В 1970 году Лэммли предложил метод разделения белков с помощью электрофореза в денатурирующем полиакриламидном геле, а в 1975 году на его основе была предложена методика двумерного электрофореза. В 1984 году был изобретён метод ионизации электроспреем, что позволило изучать белки с помощью масс-спектрометрии без их разрушения, а в 1985 году был предложен метод ионизации MALDI. В 1994 году появились первые пептидные карты для масс-спектрометрии. В 1996 году аспирант Марк Уилкинс ввёл в употребление термин «протеом», и уже в следующем году появился термин «протеомика». В 1999 году появились первые программы для предсказания фрагментов, массы которых будут определены с помощью масс-спектрометрии, по последовательности белка. В 2001 году зародилась скорострельная (англ. shotgun) протеомика, и к 2014 году с помощью этого метода стало возможным идентифицировать 20 тысяч белков человека в одном образце[51]. В настоящее время происходит не только развитие и усовершенствование методов протеомики, таких как различные разновидности масс-спектрометрии, но и новых программ для интерпретации протеомных данных[52].
Примечания
- ↑ James P. Protein identification in the post-genome era: the rapid rise of proteomics. (англ.) // Quarterly Reviews Of Biophysics. — 1997. — November (vol. 30, no. 4). — P. 279—331. — PMID 9634650.
- ↑ 1 2 Уилсон и Уолкер, 2015, с. 438.
- ↑ Belle A., Tanay A., Bitincka L., Shamir R., O'Shea E. K. Quantification of protein half-lives in the budding yeast proteome. (англ.) // Proceedings Of The National Academy Of Sciences Of The United States Of America. — 2006. — 29 August (vol. 103, no. 35). — P. 13004—13009. — doi:10.1073/pnas.0605420103. — PMID 16916930.
- ↑ Нолтинг Б. Новейшие методы исследования биосистем. — М.: ТЕХНОСФЕРА, 2005. — С. 185. — 256 с. — ISBN 94836-044-X.
- ↑ Bast R C, Feeney M, Lazarus H, Nadler L M, Colvin R B, Knapp R C. Reactivity of a monoclonal antibody with human ovarian carcinoma. (англ.) // Journal of Clinical Investigation. — 1981. — 1 November (vol. 68, no. 5). — P. 1331—1337. — ISSN 0021-9738. — doi:10.1172/JCI110380.
- ↑ Нельсон и Кокс, 2017, с. 143—145.
- ↑ 1 2 Нельсон и Кокс, 2017, с. 145.
- ↑ Edman Pehr, Högfeldt Erik, Sillén Lars Gunnar, Kinell Per-Olof. Method for Determination of the Amino Acid Sequence in Peptides. (англ.) // Acta Chemica Scandinavica. — 1950. — Vol. 4. — P. 283—293. — ISSN 0904-213X. — doi:10.3891/acta.chem.scand.04-0283.
- ↑ Edman P., Begg G. A protein sequenator. (англ.) // European Journal Of Biochemistry. — 1967. — March (vol. 1, no. 1). — P. 80—91. — PMID 6059350.
- ↑ Niall Hugh D. [36 Automated edman degradation: The protein sequenator] (англ.) // Methods in Enzymology. — 1973. — P. 942—1010. — ISBN 9780121818906. — ISSN 0076-6879. — doi:10.1016/S0076-6879(73)27039-8.
- ↑ Нельсон и Кокс, 2017, с. 143.
- ↑ Нельсон и Кокс, 2017, с. 145—147.
- ↑ Нельсон и Кокс, 2017, с. 147.
- ↑ LAEMMLI U. K. Cleavage of Structural Proteins during the Assembly of the Head of Bacteriophage T4 (англ.) // Nature. — 1970. — August (vol. 227, no. 5259). — P. 680—685. — ISSN 0028-0836. — doi:10.1038/227680a0.
- ↑ O'Farrell P. H. High resolution two-dimensional electrophoresis of proteins. (англ.) // The Journal Of Biological Chemistry. — 1975. — 25 May (vol. 250, no. 10). — P. 4007—4021. — PMID 236308.
- ↑ Klose J. Protein mapping by combined isoelectric focusing and electrophoresis of mouse tissues. A novel approach to testing for induced point mutations in mammals. (англ.) // Humangenetik. — 1975. — Vol. 26, no. 3. — P. 231—243. — PMID 1093965.
- ↑ Bandow J. E., Baker J. D., Berth M., Painter C., Sepulveda O. J., Clark K. A., Kilty I., VanBogelen R. A. Improved image analysis workflow for 2-D gels enables large-scale 2-D gel-based proteomics studies--COPD biomarker discovery study. (англ.) // Proteomics. — 2008. — August (vol. 8, no. 15). — P. 3030—3041. — doi:10.1002/pmic.200701184. — PMID 18618493.
- ↑ Renart J., Reiser J., Stark G. R. Transfer of proteins from gels to diazobenzyloxymethyl-paper and detection with antisera: a method for studying antibody specificity and antigen structure. (англ.) // Proceedings Of The National Academy Of Sciences Of The United States Of America. — 1979. — July (vol. 76, no. 7). — P. 3116—3120. — PMID 91164.
- ↑ Уилсон и Уолкер, 2015, с. 368—369.
- ↑ Hillenkamp F., Karas M., Beavis R. C., Chait B. T. Matrix-assisted laser desorption/ionization mass spectrometry of biopolymers. (англ.) // Analytical Chemistry. — 1991. — 15 December (vol. 63, no. 24). — P. 1193—1203. — PMID 1789447.
- ↑ McEwen Charles N., Larsen Barbara S. Fifty years of desorption ionization of nonvolatile compounds (англ.) // International Journal of Mass Spectrometry. — 2015. — February (vol. 377). — P. 515—531. — ISSN 1387-3806. — doi:10.1016/j.ijms.2014.07.018.
- ↑ Durbin K. R., Fornelli L., Fellers R. T., Doubleday P. F., Narita M., Kelleher N. L. Quantitation and Identification of Thousands of Human Proteoforms below 30 kDa. (англ.) // Journal Of Proteome Research. — 2016. — 4 March (vol. 15, no. 3). — P. 976—982. — doi:10.1021/acs.jproteome.5b00997. — PMID 26795204.
- ↑ Shevchenko A., Jensen O. N., Podtelejnikov A. V., Sagliocco F., Wilm M., Vorm O., Mortensen P., Shevchenko A., Boucherie H., Mann M. Linking genome and proteome by mass spectrometry: large-scale identification of yeast proteins from two dimensional gels. (англ.) // Proceedings Of The National Academy Of Sciences Of The United States Of America. — 1996. — 10 December (vol. 93, no. 25). — P. 14440—14445. — PMID 8962070.
- ↑ Pappin D. J., Hojrup P., Bleasby A. J. Rapid identification of proteins by peptide-mass fingerprinting. (англ.) // Current Biology : CB. — 1993. — 1 June (vol. 3, no. 6). — P. 327—332. — PMID 15335725.
- ↑ Elias Joshua E, Gygi Steven P. Target-decoy search strategy for increased confidence in large-scale protein identifications by mass spectrometry (англ.) // Nature Methods. — 2007. — March (vol. 4, no. 3). — P. 207—214. — ISSN 1548-7091. — doi:10.1038/nmeth1019.
- ↑ Pitt J. J. Principles and applications of liquid chromatography-mass spectrometry in clinical biochemistry. (англ.) // The Clinical Biochemist. Reviews. — 2009. — February (vol. 30, no. 1). — P. 19—34. — PMID 19224008.
- ↑ Alves P., Arnold R. J., Novotny M. V., Radivojac P., Reilly J. P., Tang H. Advancement in protein inference from shotgun proteomics using peptide detectability. (англ.) // Pacific Symposium On Biocomputing. Pacific Symposium On Biocomputing. — 2007. — P. 409—420. — PMID 17990506.
- ↑ Anderson Leigh, Hunter Christie L. Quantitative Mass Spectrometric Multiple Reaction Monitoring Assays for Major Plasma Proteins (англ.) // Molecular & Cellular Proteomics. — 2005. — 6 December (vol. 5, no. 4). — P. 573—588. — ISSN 1535-9476. — doi:10.1074/mcp.M500331-MCP200.
- ↑ Уилсон и Уолкер, 2015, с. 446—447.
- ↑ de Mol N. J. Surface plasmon resonance for proteomics. (англ.) // Methods In Molecular Biology (Clifton, N.J.). — 2012. — Vol. 800. — P. 33—53. — doi:10.1007/978-1-61779-349-3_4. — PMID 21964781.
- ↑ Visser N. F., Heck A. J. Surface plasmon resonance mass spectrometry in proteomics. (англ.) // Expert Review Of Proteomics. — 2008. — June (vol. 5, no. 3). — P. 425—433. — doi:10.1586/14789450.5.3.425. — PMID 18532910.
- ↑ Уилсон и Уолкер, 2015, с. 446.
- ↑ 1 2 Bensimon A., Heck A. J., Aebersold R. Mass spectrometry-based proteomics and network biology. (англ.) // Annual Review Of Biochemistry. — 2012. — Vol. 81. — P. 379—405. — doi:10.1146/annurev-biochem-072909-100424. — PMID 22439968.
- ↑ 1 2 Sabidó E., Selevsek N., Aebersold R. Mass spectrometry-based proteomics for systems biology. (англ.) // Current Opinion In Biotechnology. — 2012. — August (vol. 23, no. 4). — P. 591—597. — doi:10.1016/j.copbio.2011.11.014. — PMID 22169889.
- ↑ Weston A. D., Hood L. Systems biology, proteomics, and the future of health care: toward predictive, preventative, and personalized medicine. (англ.) // Journal Of Proteome Research. — 2004. — March (vol. 3, no. 2). — P. 179—196. — PMID 15113093.
- ↑ Mitchell Peter. A perspective on protein microarrays (англ.) // Nature Biotechnology. — 2002. — March (vol. 20, no. 3). — P. 225—229. — ISSN 1087-0156. — doi:10.1038/nbt0302-225.
- ↑ UniProt. www.uniprot.org. Дата обращения: 6 ноября 2018. Архивировано 15 декабря 2020 года.
- ↑ ExPASy — PROSITE. prosite.expasy.org.
- ↑ Petrov D., Margreitter C., Grandits M., Oostenbrink C., Zagrovic B. A systematic framework for molecular dynamics simulations of protein post-translational modifications. (англ.) // PLoS Computational Biology. — 2013. — Vol. 9, no. 7. — P. e1003154—1003154. — doi:10.1371/journal.pcbi.1003154. — PMID 23874192.
- ↑ Margreitter C., Petrov D., Zagrovic B. Vienna-PTM web server: a toolkit for MD simulations of protein post-translational modifications. (англ.) // Nucleic Acids Research. — 2013. — July (vol. 41). — P. 422—426. — doi:10.1093/nar/gkt416. — PMID 23703210.
- ↑ Maron J. L., Alterovitz G., Ramoni M., Johnson K. L., Bianchi D. W. High-throughput discovery and characterization of fetal protein trafficking in the blood of pregnant women. (англ.) // Proteomics. Clinical Applications. — 2009. — December (vol. 3, no. 12). — P. 1389—1396. — doi:10.1002/prca.200900109. — PMID 20186258.
- ↑ Gupta N., Tanner S., Jaitly N., Adkins J. N., Lipton M., Edwards R., Romine M., Osterman A., Bafna V., Smith R. D., Pevzner P. A. Whole proteome analysis of post-translational modifications: applications of mass-spectrometry for proteogenomic annotation. (англ.) // Genome Research. — 2007. — September (vol. 17, no. 9). — P. 1362—1377. — doi:10.1101/gr.6427907. — PMID 17690205.
- ↑ Gupta N., Benhamida J., Bhargava V., Goodman D., Kain E., Kerman I., Nguyen N., Ollikainen N., Rodriguez J., Wang J., Lipton M. S., Romine M., Bafna V., Smith R. D., Pevzner P. A. Comparative proteogenomics: combining mass spectrometry and comparative genomics to analyze multiple genomes. (англ.) // Genome Research. — 2008. — July (vol. 18, no. 7). — P. 1133—1142. — doi:10.1101/gr.074344.107. — PMID 18426904.
- ↑ What is Proteomics? ProteoConsult. Дата обращения: 6 ноября 2018. Архивировано 29 апреля 2021 года.
- ↑ Li J., Lu Y., Akbani R., Ju Z., Roebuck P. L., Liu W., Yang J. Y., Broom B. M., Verhaak R. G., Kane D. W., Wakefield C., Weinstein J. N., Mills G. B., Liang H. TCPA: a resource for cancer functional proteomics data. (англ.) // Nature Methods. — 2013. — November (vol. 10, no. 11). — P. 1046—1047. — doi:10.1038/nmeth.2650. — PMID 24037243.
- ↑ Ilina E. N., Borovskaya A. D., Malakhova M. M., Vereshchagin V. A., Kubanova A. A., Kruglov A. N., Svistunova T. S., Gazarian A. O., Maier T., Kostrzewa M., Govorun V. M. Direct bacterial profiling by matrix-assisted laser desorption-ionization time-of-flight mass spectrometry for identification of pathogenic Neisseria. (англ.) // The Journal Of Molecular Diagnostics : JMD. — 2009. — January (vol. 11, no. 1). — P. 75—86. — doi:10.2353/jmoldx.2009.080079. — PMID 19095774.
- ↑ Vachani A., Hammoud Z., Springmeyer S., Cohen N., Nguyen D., Williamson C., Starnes S., Hunsucker S., Law S., Li X. J., Porter A., Kearney P. Clinical Utility of a Plasma Protein Classifier for Indeterminate Lung Nodules. (англ.) // Lung. — 2015. — December (vol. 193, no. 6). — P. 1023—1027. — doi:10.1007/s00408-015-9800-0. — PMID 26376647.
- ↑ 1 2 Tomislav Meštrović. Proteomics uses. Дата обращения: 30 ноября 2018. Архивировано 1 декабря 2018 года.
- ↑ Gagneux P., Amess B., Diaz S., Moore S., Patel T., Dillmann W., Parekh R., Varki A. Proteomic comparison of human and great ape blood plasma reveals conserved glycosylation and differences in thyroid hormone metabolism. (англ.) // American Journal Of Physical Anthropology. — 2001. — June (vol. 115, no. 2). — P. 99—109. — doi:10.1002/ajpa.1061. — PMID 11385598.
- ↑ Ge L. Q., Cheng Y., Wu J. C., Jahn G. C. Proteomic analysis of insecticide triazophos-induced mating-responsive proteins of Nilaparvata lugens Stål (Hemiptera: Delphacidae). (англ.) // Journal Of Proteome Research. — 2011. — 7 October (vol. 10, no. 10). — P. 4597—4612. — doi:10.1021/pr200414g. — PMID 21800909.
- ↑ Сергей Мошковский. 12 методов в картинках: протеомика. Биомолекула. Дата обращения: 30 августа 2018. Архивировано 31 августа 2018 года.
- ↑ Carnielli Carolina M., Winck Flavia V., Paes Leme Adriana F. Functional annotation and biological interpretation of proteomics data (англ.) // Biochimica et Biophysica Acta (BBA) - Proteins and Proteomics. — 2015. — January (vol. 1854, no. 1). — P. 46—54. — ISSN 1570-9639. — doi:10.1016/j.bbapap.2014.10.019.
Литература
- Принципы и методы биохимии и молекулярной биологии / К. Уилсон и Дж. Уолкер. — М.: БИНОМ. Лаборатория знаний, 2015. — 848 с. — ISBN 978-5-9963-1895-7.
- Нельсон Дэвид, Кокс Майкл. Основы биохимии Ленинджера. В 3 т. — М.: Лаборатория знаний, 2017. — Т. 1. — ISBN 978-5-00101-014-2.








