Суффиксный автомат
| Суффиксный автомат | |||||||
|---|---|---|---|---|---|---|---|
| англ. suffix automaton англ. directed acyclic word graph | |||||||
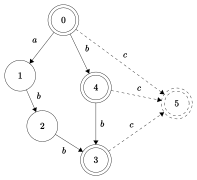
 Суффиксный автомат для abbcbc | |||||||
| Тип | Индекс подстрок | ||||||
| Год изобретения | 1983 | ||||||
| Автор | Ансельм Блумер, Джанет Блумер, Анджей Эренфехт[англ.], Дэвид Хаусслер[англ.], Росс Макконнелл | ||||||
| Сложность в О-символике | |||||||
| |||||||


Су́ффиксный автома́т (англ. suffix automaton, directed acyclic word graph) — структура данных, позволяющая хранить в сжатом виде и обрабатывать информацию, связанную с подстроками данной строки. Представляет собой детерминированный конечный автомат, принимающий все суффиксы слова и только их, и обладающий наименьшим возможным числом состояний среди всех таких автоматов. Менее формально, суффиксный автомат — это ориентированный ациклический граф с выделенной начальной вершиной и набором «финальных» вершин, дуги которого помечены символами, такой что у любой вершины символы на исходящих из неё дугах попарно различны и для любого суффикса слова существует путь из начальной вершины в некоторую финальную вершину, символы на котором при конкатенации образуют данный суффикс. Из всех графов, удовлетворяющих данному описанию, суффиксным автоматом называется тот, который обладает наименьшим возможным числом вершин.


Суффиксный автомат был впервые описан группой учёных из Денверского и Колорадского университетов в 1983 году, они же показали, что размер автомата линейно зависит от длины , а также предложили онлайн-алгоритм[англ.] для его построения с линейным временем работы. В дальнейших работах на эту тему была обнаружена тесная связь суффиксного автомата с суффиксными деревьями, а сама концепция суффиксного автомата получила различные обобщения. Так были введены сжатый суффиксный автомат, получаемый из исходного процедурой, аналогичной той, которая применяется к суффиксному бору для получения суффиксного дерева, а также обобщённый суффиксный автомат, который строится для набора слов и принимает слова, являющиеся суффиксами хотя бы одного из данных.

С помощью суффиксного автомата можно эффективно решать такие задачи как поиск подстроки в строке, определение наибольшей общей подстроки двух и более строк и другие.
История

Концепция суффиксного автомата была представлена группой учёных из Денверского и Колорадского университетов Ансельмом Блумером, Анджеем Эренфехтом[англ.], Дэвидом Хаусслером[англ.], Россом МакКоннеллом и Джанет Блумер в 1983 году, хотя связанные с ним структуры встречались ранее в работах Питера Вайнера[1], Вона Пратта[2] и Анатолия Олесьевича Слисенко[3], посвящённых алгоритмам построения суффиксных деревьев. В той же работе Блумер и другие показали, что построенный по слову длины больше автомат содержит не больше состояний и не больше переходов, а также привели линейный алгоритм построения автомата[4].



В 1983 году Му Тянь Чэнь и Джоэл Сейферас независимо разработали алгоритм построения суффиксного автомата, показывающий, что алгоритм Вайнера[1], предложенный в 1973 году для построения суффиксного дерева слова , также строит суффиксный автомат для обращённого слова в качестве вспомогательной структуры[5]. В 1987 году Блумер и другие, по аналогии с суффиксным деревом, описали сжатый суффикный автомат[6], получаемый из суффиксного автомата удалением нефинальных состояний с полустепенью исхода, равной единице, а в 1997 году Максим Крошемор[англ.] и Рено Верин разработали линейный алгоритм для его прямого построения[7]. В 2001 году Сюнсукэ Инэнага и другие разработали линейный онлайн-алгоритм для построения сжатого суффиксного автомата[8], а также линейный алгоритм для построения сжатого суффиксного автомата для набора слов, заданного префиксным деревом[9].

В своей исходной работе Блумер с коллегами определили описанную ими структуру как минимальный автомат, распознающий все подстроки (а не суффиксы) данного слова. Данную структуру они назвали ориентированным ациклическим графом слов (англ. directed acyclic word graph)[4]. Впоследствии данное название также использовалось как синоним детерминированного ациклического конечного автомата[англ.] — минимального автомата, распознающего произвольный конечный набор слов (не обязательно составляющих множество суффиксов или подстрок некоторой строки)[10][11].
Обозначения
При описании суффиксных автоматов и связанных с ними фактов и теорем часто используются обозначения из теории формальных языков в целом и теории автоматов в частности[12]:
- Алфавит — конечное множество , из которого могут состоять слова. Его элементы называются символами;
- Слово — конечная последовательность символов алфавита . Длина слова обозначается как ;
- Формальный язык — некоторое множество слов над заданным алфавитом;
- Язык всех слов обозначается как (здесь символ «*» несёт смысл звезды Клини), пустое слово (слово нулевой длины) — символом ;
- Конкатенация (произведение) слов и обозначается как или и равна слову, получаемому приписыванием к справа, то есть, ;
- Конкатенация языков и обозначается как или и равна множеству попарных конкатенаций ;
- Если слово представимо в виде , где , то слова , и называют префиксом, суффиксом и подсловом (подстрокой) слова соответственно;
- Если , то говорят, что слово входит (встречается) в как подслово. При этом и называются левой и правой позициями вхождения в соответственно.


























Структура автомата
Формально, детерминированный конечный автомат определяется набором из пяти элементов , где:

- — алфавит, из которого состоят слова, распознаваемые автоматом,
- — множество состояний автомата,
- — начальное состояние автомата,
- — множество финальных состояний автомата,
- — частично определённая[англ.] функция переходов автомата, такая что для и либо не определена, либо указывает на состояние, в которое может быть произведён переход из по .









Чаще всего на практике конечные автоматы представляются в виде ориентированного графа (диаграммы) такого что[13]:
- Множество вершин графа соответствует множеству состояний ,
- В графе выделена некоторая вершина, соответствующая начальному состоянию ,
- В графе выделен набор вершин, соответствующих множеству финальных состояний ,
- Множество дуг в графе соответствует множеству переходов ,
- При этом переходу соответствует дуга из в , помеченная символом алфавита . Такой переход также обозначают как .






![{\textstyle q_{1}{\begin{smallmatrix}{\sigma }\\[-5pt]{\longrightarrow }\end{smallmatrix}}q_{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/16652b5477735b6587a69159e7dc29f9e349fe10)
В таком графе вершины и дуги отождествляются с состояниями и переходами автомата соответственно. Автомат принимает слово в том и только том случае, если существует путь из начального состояния в некоторое финальное состояние , такой что если сконкатенировать символы, встретившиеся на этом пути, то получится слово . Множество слов, которые принимает автомат, образуют язык этого автомата[12].


Состояния автомата
Правым контекстом слова относительно языка называют множество . То есть это множество слов , при приписывании которых к слову справа получается слово из языка . Правые контексты индуцируют естественное отношение эквивалентности на множестве всех слов. Если язык может быть задан некоторым детерминированным конечным автоматом, то для него существует единственный, с точностью до изоморфизма, автомат, обладающий при этом наименьшим возможным числом состояний. Такой автомат называется минимальным для данного языка , теорема Майхилла — Нероуда позволяет задать его в явном виде[14][15]:

![{\displaystyle [\omega ]_{R}=\{\alpha :\omega \alpha \in L\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0e11883b4ac05c6aecf539854d6b75c9ef741f92)
![{\displaystyle [\alpha ]_{R}=[\beta ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a98b44d0cd19b729ad56a393d0eaec1805c8e39b)
Минимальный автомат, распознающий язык над алфавитом , может быть задан следующим образом:
- Алфавит остаётся без изменений,
- Состояниям соответствуют правые контексты всех слов ,
- Начальному состоянию соответствует правый контекст пустого слова ,
- Финальным состояниям соответствуют правые контексты слов из языка ,
- Переходы имеют вид , где и .
![{\displaystyle [\omega ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9d0d285bcdf8a938d706449db49bf9412fa4d28c)
![{\displaystyle [\varepsilon ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0760f6b8f45135b6a59cd46f3e0fbaf6fe048e87)

![{\displaystyle [\omega ]_{R}{\begin{smallmatrix}{\sigma }\\[-5pt]{\longrightarrow }\end{smallmatrix}}[\omega \sigma ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/608b0d4e9d7dc30de4e7a50378e05b04f2c5a829)
В таких обозначениях, суффиксный автомат — это минимальный ДКА, принимающий язык суффиксов слова . Правый контекст слова относительно данного языка состоит из слов таких что — суффикс . Это позволяет сформулировать следующую лемму, определяющую взаимно-однозначное соответствие между правым контекстом слова и множеством позиций его вхождений в в качестве подслова[16][17]:

Пусть — множество правых позиций вхождений в .
Между элементами множеств и есть следующее взаимно-однозначное соответствие:
- Если , то ;
- Если , то .



![{\displaystyle s_{x+1}s_{x+2}\dots s_{n}\in [\omega ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7236e1094224b68350522b3c78e3b25c7d7590c7)
![{\displaystyle \alpha \in [\omega ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/43d734319905e4142a99b88b1a4ff78848e2db43)

Например, для слова и его подслова выполнено и . Неформально, состоит из слов, которые следуют за вхожениями до конца слова, а — из позиций этих вхождений. В этом примере, элементу соответствует слово . В то же время, слову соответствует элемент .



![{\displaystyle [ab]_{R}=\{a,acaba\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3f08d2df6474465c79e95062c1fb852ab40b5f9a)
![{\displaystyle [ab]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ed7efb19a8c1c679df529cc521396f5084dc6bc)



![{\displaystyle s_{3}s_{4}s_{5}s_{6}s_{7}=acaba\in [ab]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c276d63dd14d389a3bc61bd2ac4ec6dd79440d1c)
![{\displaystyle a\in [ab]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95e7352493337857728aadbf551c04e533d5e6db)

Из этого следует ряд структурных свойств состояний суффиксного автомата и слов, которые ими принимаются. Пусть , тогда[17]:

- Если у и есть хотя бы один общий элемент , то общий элемент также есть у и . Это, в свою очередь, значит, что — суффикс и потому и . В приведённом выше примере, и, как следствие, — суффикс , а также и ;
- Если , то , то есть встречается в только в качестве суффикса . Это видно на примере слов и , для которых и ;
- Если и — суффикс , такой что , то . В приведённом выше примере, , а «промежуточным» суффиксом является . И действительно, .
![{\displaystyle [\alpha ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/71085cf6f872adc3d86197ac113b94084f5345c9)
![{\displaystyle [\beta ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b458c8d348b152c8ce7c446dba72e2a9c06c739)




![{\displaystyle [\beta ]_{R}\subset [\alpha ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/120910cc963d194c5a2e72aaabeccd99762bb0cb)
![{\displaystyle a\in [ab]_{R}\cap [cab]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/290e157059e4c8570e934f79b954cbc33dad920d)

![{\displaystyle [cab]_{R}=\{a\}\subset \{a,acaba\}=[ab]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e09d83b6c56e7c9e8dfd2d011bf221f0fb43937d)




![{\displaystyle [b]_{R}=[ab]_{R}=\{a,acaba\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3b44e32ec0f0fc2800c6a07868a498acf9e7200b)


![{\displaystyle [\alpha ]_{R}=[\gamma ]_{R}=[\beta ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3ff07aea00a27624cd9ee051aed79421a3e707c8)
![{\displaystyle [c]_{R}=[bac]_{R}=\{aba\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3211d738bcd0308264c98a087e9538bb5c9fbc76)

![{\displaystyle [ac]_{R}=\{aba\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7121eb2486dab490f0f2f0fce9c4738d130c4979)
Таким образом, любое состояние суффиксного автомата принимает некоторую непрерывную цепочку вложенных друг в друга суффиксов наибольшей строки из этого состояния[17].
![{\displaystyle q=[\alpha ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b41dd70277955f02fec50f8fb0f15aac98944de2)
Левым расширением строки называют самую длинную строку , имеющую тот же правый контекст, что и . Длину самой длинной строки, принимаемой состоянием , обозначают как . Для него верно, что[18]:


![{\displaystyle q=[\gamma ]_{R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fa3035b4f3dae96f18646d8eb7ffad7443c84355)

Левое расширение строки может быть представлено в виде , где — самое длинное слово, такое что любому вхождению слова в предшествует слово .

Суффиксной ссылкой от состояния называют указатель на состояние , содержащее наибольший суффикс , который не принимается состоянием .


В таких обозначениях можно сказать, что состояние принимает в точности все суффиксы , которые длиннее и не длиннее . Кроме того, верно следующее[18]:


Суффиксные ссылки образуют дерево , которое можно задать явно следующим образом:
- Вершинам соответствуют левые расширения всех подстрок ,
- Рёбра соединяют вершины , такие что и .







Связь с суффиксным деревом

Префиксным деревом (или бором) называют корневое ориентированное дерево, дуги которого помечены символами таким образом, что из любой вершины этого дерева исходит не больше одной дуги, помеченной данным символом. Некоторые вершины в префиксном дереве помечены. Говорят, что префиксное дерево задаёт множество слов, определяемое путями из корня дерева в помеченные вершины. Таким образом, префиксные деревья представляют собой особую разновидность конечных автоматов, если рассматривать корень как начальное состояние, а помеченные вершины — как финальные состояния[19]. Суффиксным бором слова называют префиксное дерево, задающее язык суффиксов этого слова. Суффиксным деревом называют дерево, получаемое из суффиксного бора процедурой сжатия, при которой последовательно идущие рёбра склеиваются если между ними находится нефинальная вершина, степень которой равна 2[18].

По определению, суффиксный автомат может быть получен минимизацией суффиксного бора. Кроме того, сжатый суффиксный автомат может быть получен как минимизацией суффиксного дерева (если считать, что символы алфавита — это слова на рёбрах дерева), так и сжатием обычного автомата[8]. Однако, помимо очевидной связи между суффиксным автоматом и суффиксным деревом одной и той же строки, можно также установить некоторое соответствие между суффиксным автоматом строки и суффиксным деревом обращённой строки [20].

Аналогично правым контекстам можно ввести левые контексты и правые расширения , соответствующие самым длинным строкам, имеющим заданный левый контекст, а также отношение эквивалентности . Если рассматривать правые расширения относительно языка префиксов строки , то можно получить, что[18]:
![{\displaystyle [\omega ]_{L}=\{\beta \in \Sigma ^{*}:\beta \omega \in L\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5e52cedfd75f0212d1e994dd4e26244482923cff)

![{\displaystyle [\alpha ]_{L}=[\beta ]_{L}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f0476adeb02a48c9623b9a037d45d9e7cc104594)
Суффиксное дерево строки может быть задано в явном виде следующим образом:
- Вершинам соответствуют правые расширения всех подстрок ,
- Рёбрам соответствуют тройки такие что и .
Здесь тройка значит, что на ребре из в записана строка .







Из чего следует, что дерево суффиксных ссылок для автомата строки и суффиксное дерево строки изоморфны[20]:

| Суффиксные структуры слов abbcbc и cbcbba |
|---|
|



Аналогично левым расширениям, для правых расширений также может быть сформулирована структурная лемма[18]:
Правое расширение строки может быть представлено в виде , где — самое длинное слово, такое что за любым вхождением в сразу следует слово .

Размер
В суффиксном автомате строки длины не больше состояний и не больше переходов, причём данные оценки достигаются на строках и соответственно[16]. Можно также сформулировать более сильное утверждение о связи числа состояний и переходов в автомате: , где и — это число переходов и состояний соответственно[17].








| Максимальные суффиксные автоматы |
|---|
|




Построение
Суффиксный автомат строки строится последовательным наращиванием слова, для которого он построен. Изначально имеется тривиальный автомат, построенный для пустого слова, а затем на каждом шаге к текущему слову добавляется один символ, что влечёт за собой перестройку состояний и переходов автомата[21].
Изменение состояний
После приписывания нового символа к слову, некоторые классы эквивалентности изменятся. Пусть — правый контекст слова относительно языка суффиксов слова . Тогда переход от к при приписывании символа к слову описывается следующей леммой[17]:
![{\displaystyle [\alpha ]_{R_{\omega }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bf5092b4d6aa56f342180faa815e616310a766a1)
![{\displaystyle [\alpha ]_{R_{\omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5bc63f277d664c127ea435f4ec937f065812790c)
Пусть — некоторые слова над алфавитом и — некоторый символ этого алфавита. Тогда между правыми контекстами и слова относительно языков суффиксов слов и соответственно имеет место следующая связь:
- если — суффикс ;
- в противном случае.


![{\displaystyle [\alpha ]_{R_{\omega x}}=[\alpha ]_{R_{\omega }}x\cup \{\varepsilon \}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/62af9ba620fb1df6646ec322efe363af38d33047)
![{\displaystyle [\alpha ]_{R_{\omega x}}=[\alpha ]_{R_{\omega }}x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aea54945b739d0e96a6ed3769826a24a6bca469b)
То есть при добавлении одного символа к текущему слову правый контекст слова может измениться только в том случае, если является суффиксом слова . Из этого следует, что разбиение всех слов на классы эквивалентности по является измельчением разбиения на классы эквивалентности по . Другими словами, если , то . Кроме того, при добавлении очередного символа к слову расщепление произойдёт у не более чем двух состояний. В первую очередь будет расщеплено состояние, которому соответствует пустой правый контекст (то есть то, которое принимает язык слов, не входящих в в качестве подслова). Из этого состояния будет выделено новое состояние, содержащее всё слово , а также все его суффиксы, которые встречаются в , но не встречались в . Соответственно, правый контекст этих слов, который ранее был пустым, теперь будет состоять только из пустого слова[17].


![{\displaystyle [\alpha ]_{R_{\omega x}}=[\beta ]_{R_{\omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8720b747c926636d4f25ae02fd22c02e6cee6f2a)
![{\displaystyle [\alpha ]_{R_{\omega }}=[\beta ]_{R_{\omega }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/35041a5b568ed31c1c4bafcf28d5dc300a2bdd4d)
Учитывая связь между состояниями суффиксного автомата и вершинами суффиксного дерева, можно отследить и второе состояние, которое может расщепиться при добавлении очередного символа. Так как переход от слова к соответствует переходу от к для обращённой строки, приписывание символа к строке соответствует внесению одного нового (самого длинного) суффикса в суффиксное дерево строки . При этом появляется не более двух вершин: одна из них будет соответствовать всему слову , а другая может появиться в том месте, где происходит ответвление от дерева. Таким образом, одно новое состояние соответствует правому контексту всей строки , а другое (если оно есть) может соответствовать только суффиксной ссылке этого состояния. Данные наблюдения можно обобщить теоремой[17]:


Пусть и . Пусть также является самым длинным суффиксом , который встречается в , а — его левое расширение относительно , то есть самое длинное подслово слова такое что . Тогда для любых подслов слова верно следующее:
- Если и , то ;
- Если и , то ;
- Если и , то .


![{\displaystyle [u]_{R_{\omega }}=[v]_{R_{\omega }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/432b8eb68fefcd343856cd77b50e1a6da1bf7226)
![{\displaystyle [u]_{R_{\omega }}\neq [\alpha ]_{R_{\omega }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4c5d2ddc8543be4dee9f0dd9607f27ca70d1b93)
![{\displaystyle [u]_{R_{\omega x}}=[v]_{R_{\omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d507f1de166b155876cfde9762eaa827a4d147fe)
![{\displaystyle [u]_{R_{\omega }}=[\alpha ]_{R_{\omega }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d49bd348b535edf97e44b2ee3ff525eb717a44f)

![{\displaystyle [u]_{R_{\omega x}}=[\alpha ]_{R_{\omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dc2ae2510aa9e9ee2d0f6ec623fdb4bf70ffacdd)

![{\displaystyle [u]_{R_{\omega x}}=[\beta ]_{R_{\omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2e6d5e324fa555ebe1942df7367ebadc6c1f9353)
В частности, если (например, когда вообще не встречается в и ), расщепления второго состояния не происходит[17].


Помимо суффиксных ссылок, в новом автомате также нужно определить финальные состояния. Из структурных свойств автомата следует, что суффиксы любого слова расположены таким образом, что если , то суффиксы , чья длина превышает , лежат в , суффиксы, чья длина больше , но не больше , лежат в и так далее. Иными словами, для любого суффикса найдётся вершина в суффиксном пути состояния , который задаётся последовательностью . Соответственно если обозначить состояние, принимающее в текущий момент всю строку , как , то терминальными (принимающими суффиксы ) состояниями будут те и только те состояния, которые входят в суффиксный путь [21].




Изменение переходов и суффиксных ссылок
Какие-либо изменения при добавлении очередного символа затрагивают не более чем два новых состояния, поэтому изменения в переходах автомата тоже будут затрагивать только эти состояния. После приписывания к слову образуется новое состояние , а также, возможно, состояние . Суффиксная ссылка из будет вести в , а из — в . Слова из встречаются в только в виде суффиксов, поэтому из не должно быть переходов, а ведущие в него переходы должны вести по символу из суффиксов с длиной хотя бы . Состояние отщепляется от , поэтому переходы из этого состояния будут дублировать таковые у . А ведущие в него переходы будут вести по символу из состояний, соответствующим суффиксам длины меньше и не меньше , так как ранее эти переходы вели в и соответствовали отделившейся части состояния. Состояния, принимающие данные слова, можно определить по суффиксному пути состояния [21].
![{\displaystyle [\omega x]_{R_{\omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fc3ec8722532016ceae828eeaf081202ac42b05)
![{\displaystyle link([\alpha ]_{R_{\omega }})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/91d45b00112aebf52e311e9255240351d52531c2)

![{\displaystyle len(link([\alpha ]_{R_{\omega }}))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ddac98ddeaf4716b89cf8092632952e5ae753e5)
![{\displaystyle [\omega ]_{R_{\omega }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3af043acf29d9539fa3e1c72adfb971594474df)
| Построение суффиксного автомата для слова abbcbc | |||||||||
|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||
|
| ||||||||
|
| ||||||||









Алгоритм построения автомата
Теоретические результаты выше приводят к следующему алгоритму, который принимает символ и перестраивает суффиксный автомат слова в суффиксный автомат слова [21]:
- Поддерживается номер состояния , соответствующего всей строке ;
- При добавлении символа , номер запоминается в переменной , а в записывается номер нового состояния, соответствующего слову ;
- Из состояний, соответствующих суффиксам , проставляются переходы в . Для этого идёт обход суффиксного пути , пока не встретится состояние, из которого уже есть переход по ;
- Дальнейшие действия соответствуют одному из трёх случаев:
- Если на всём суффиксном пути ни из одного состояния нет перехода по , то раньше не встречался в и суффиксная ссылка из ведёт в ;
- Если переход по нашёлся и ведёт из состояния в состояние , такое что , то необходимости расщеплять нет и достаточно провести суффиксную ссылку из в ;
- Если же , то слова из состояния , чья длина не превосходит должны быть выделены в отдельное состояние ;
- Если на прошлом шаге было выделено отдельное состояние , то переходы и суффиксная ссылка из него должны дублировать оные в , при этом станет общей суффиксной ссылкой состояний и ;
- Переходы, которые вели в , но соответствовали словам длины не больше , перенаправляются в . Для этого можно продолжать идти по суффиксному пути , пока не найдётся состояние, переход из которого ведёт не в .





Процедура, реализующая этот алгоритм, может быть описана следующим псевдокодом:
функция add_letter(x): определить p = last присвоить last = new_state() присвоить len(last) = len(p) + 1 пока δ(p, x) не определено: присвоить δ(p, x) = last, p = link(p) определить q = δ(p, x) если q = last: присвоить link(last) = q0 иначе если len(q) = len(p) + 1: присвоить link(last) = q иначе: определить cl = new_state() присвоить len(cl) = len(p) + 1 присвоить δ(cl) = δ(q), link(cl) = link(q) присвоить link(last) = link(q) = cl пока δ(p, x) = q: присвоить δ(p, x) = cl, p = link(p)
Здесь — начальное состояние автомата, — функция, добавляющая в автомат новое состояние. Предполагается, что , , и хранятся в виде глобальных переменных.



Вычислительная сложность
В зависимости от используемых структур, детерминированная версия описанного выше алгоритма может быть реализована за время с памяти или за время с памяти, если считать, что выделение памяти происходит за . При этом для получения такой оценки времени работы необходимо провести амортизационный анализ внутренних циклов алгоритма. Если рассмотреть, как меняется параметр после первой итерации первого цикла, то можно увидеть, что с каждой итерацией цикла он строго уменьшается. При этом если на последней итерации предыдущего шага эта величина была равна , то на второй итерации на следующем шаге эта величина будет равна . То, что ни в какой момент времени не превосходит и что между циклами эта величина увеличивается только на единицу, даёт требуемое утверждение. Аналогичным анализом может быть показана линейность суммарного времени исполнения второго цикла алгоритма[21].








Вариации и обобщения
Суффиксный автомат тесно связан с другими суффиксными структурами и индексами подстрок. Имея суффиксный автомат некоторой строки, возможно сжатием и рекурсивным обходом данного автомата построить суффиксное дерево этой строки за линейное время[22]. Аналогичные преобразования в обе стороны возможны между суффиксным автоматом строки и суффиксным деревом обращённой строки [20]. Помимо этого был разработан ряд модификаций алгоритма, позволяющих строить автомат для множества строк, заданных префиксным деревом[9], применять к нему сжатие[6], поддерживать его структуру в режиме скользящего окна[23], а также перестраивать при добавлении символов как с конца, так и с начала строки[24].
Сжатый суффиксный автомат
Как было сказано выше, сжатый суффиксный автомат может быть получен из обычного суффиксного автомата сжатием (удалением состояний, которые не являются финальными и из которых ведёт ровно один переход), а также минимизацией суффиксного дерева, если считать, что алфавит образуют слова, записанные на рёбрах дерева. Кроме того, состояния сжатого автомата могут быть описаны явно, аналогично тому, как это было сделано для несжатого автомата. Двусторонним расширением слова называют самое длинное слово , такое что любому вхождение в предшествует слово , а сразу за ним следует слово . В терминах левых и правых расширений это значит, что двустороннее расширение является левым расширением от правого расширения или, что эквивалентно, правым расширением от левого расширения: . В терминах двусторонних расширений сжатый суффиксный автомат можно описать следующим образом[18]:



Сжатый суффиксный автомат слова может быть задан парой , где:
- — множество состояний автомата;
- — множество переходов автомата.



Двусторонние расширения порождают отношение эквивалентности , описывающее слова, принимаемые одним и тем же состоянием сжатого автомата. Это отношение является транзитивным замыканием отношения , что подчёркивает тот факт, что состояния сжатого суффиксного автомата могут быть получены как склеиванием вершин суффиксного дерева, эквивалентных по (минимизация суффиксного дерева), так и склеиванием состояний суффиксного автомата, эквивалентных по (сжатие суффиксного автомата)[25]. Если у слов и совпадают правые расширения, а у слов и — левые, то в совокупности у слов , и совпадает двустороннее расширение. При этом может оказаться, что у слов и не совпадают ни левые, ни правые расширения. В случае , и левые и правые расширения таковы: , но и . В случае односторонних контекстов и расширений слова из одного и того же класса эквивалентности образовывали непрерывную цепочку вложенных друг в друга префиксов или суффиксов и могли быть однозначно определены длинами самого короткого и самого длинного слов в классе. В случае же двусторонних расширений наверняка можно сказать только то, что слова из одного и того же класса являются подсловами самого длинного слова из этого класса, а в остальном классы могут иметь достаточно сложную структуру. Общее число таких классов эквивалентности не превосходит , из чего следует, что у сжатого суффиксного автомата строки длины будет не больше состояний. Количество переходов в таком автомате не превосходит [18].












Суффиксный автомат для набора строк
Пусть задан набор слов . Аналогично автомату, построенному по единственному слову можно рассмотреть обобщённый суффиксный автомат, который принимает язык слов, являющихся суффиксом хотя бы одного слова из . При этом для числа состояний и переходов данного автомата будут выполняться все те же ограничения, которые были указаны выше, если положить [25]. Сам алгоритм построения по своей сути похож на алгоритм построения автомата для одной строки, но вместо указателя на состояние соответствующее слову при переходе к слову функция add_letter будет принимать указатель на состояние, принимающее слово , подразумевая, что переход происходит от текущего набора слов к набору . Помимо основных действий, которые уже заложены в алгоритм нужно будет отдельно разобрать случай когда строка уже присутствует в автомате — в таком случае, возможно, придётся расщепить состояние, которое её принимает, аналогично тому, как это происходило при формировании суффиксной ссылки в алгоритме для единичного слова[26][27].






Дальнейшим развитием этой идеи стало построение суффиксного автомата для случая когда набор задан не в явном виде, а префиксным деревом на вершинах. Мохри и другие показали, что такой автомат содержит не более состояний и может быть построен за линейное от своего размера время. При этом количество переходов в таком автомате может достигать — например, если рассмотреть множество слов над алфавитом , то суммарная длина слов из этого множества будет порядка , число вершин в соответствующем префиксном дереве будет равна , а в суффиксном автомате будет порядка состояний и переходов. Сам алгоритм, предложенный Мохри, во многом повторяет общий алгоритм построения автомата по набору строк, но вместо того, чтобы каждый раз дописывать символы слова из набора от начала до конца, алгоритм обходит префиксное дерево в порядке обхода в ширину и приписывает очередные символы в том порядке, в котором встречает их при обходе, что гарантирует амортизированно линейное время работы алгоритма[28].







Скользящее окно
В некоторых алгоритмах сжатия, таких как LZ77 и RLE может быть полезным хранить суффиксный автомат или подобную структуру не для всего считанного слова, а только для последних символов. В первую очередь, такая необходимость всплывает из-за специфики задач сжатия данных, где сжимаемые строки обычно достаточно велики и использование памяти нежелательно. В 1985 году Джанет Блумер разработала алгоритм, поддерживающий суффиксный автомат на скользящем окне размера и работающий за в худшем случае и в среднем, в предположении, что символы в сжимаемом слове распределены независимо и равномерно. В той же работе было показано, что оценка является неулучшаемой — если рассмотреть слова, полученные конкатенацией нескольких слов вида , где , то число состояний автомата, который соответствует подсловам длины чередовалось бы с резкими прыжками порядка по величине, что делает существование даже теоретического алгоритма, улучшающего оценку в для суффиксного автомата невозможным[29].




Казалось бы, то же самое должно быть верно и для суффиксного дерева, так как вершины суффиксного дерева соответствуют состояниям суффиксного автомата развёрнутой строки. Однако, если в суффиксном дереве не выделять отдельную вершину для каждого суффикса, то таких резких скачков уже не будет и построение амортизированного алгоритма, поддерживающего суффиксное дерево на скользящем окне возможно. Соответствующий алгоритм для суффиксного дерева, основанный на алгоритме Маккрейта и поддерживающий добавление нового символа справа и удаление символа слева, был предложен в 1989 году Эдвардом Фиала и Дэниелом Грином[30], а в 1996 году изложен в терминах алгоритма Укконена Джеспером Ларссоном[31][32]. В связи с этим долгое время оставался открытым вопрос о том, возможно ли поддержание быстрого скользящего окна для сжатого автомата, который объединяет в себе некоторые свойства как обычного суффиксного автомата, так и суффиксного дерева. Отрицательный ответ на этот вопрос был получен в 2008 Мартином Сенфтом и Томашем Двораком, показавшим, что если алфавит состоит из двух и более символов, то амортизированное время, требуемое для сдвига окна на один символ в худшем случае имеет порядок [33].

В то же время, если точная ширина окна не важна и задача заключается лишь в том, чтобы поддерживать окно, чья ширина по порядку величины не превосходит , это можно сделать приближённым алгоритмом, предложенным Иненагой и другими в 2004 году. Особенностью алгоритма является то, что «окно», которое двигается по слову, имеет переменную длину, которая при этом в любой момент не меньше и не больше , при этом суммарное время работы остаётся линейным[34].

Применения
Суффиксный автомат строки может использоваться для решения таких задач, как[35][36]:
- Подсчёт количества различных подстрок за время в режиме онлайн,
- Поиск самой длинной подстроки , которая входит в неё хотя бы два раза, за время ,
- Поиск наибольшей общей подстроки строк и за время ,
- Подсчёт числа вхождений строки в в качестве подстроки за время ,
- Поиск всех вхождений в за время , где — количество вхождений.



Здесь стоит считать, что некоторая строка подаётся на вход, когда автомат уже построен и готов к использованию.
Суффиксные автоматы также нашли своё применение в таких прикладных задачах, как сжатие данных[37], идентификация музыки по записанным фрагментам[38][39] и сопоставление геномных последовательностей[40].
Примечания
- ↑ 1 2 Weiner, 1973
- ↑ Pratt, 1973
- ↑ Slisenko, 1983
- ↑ 1 2 Blumer et al., 1984, p. 109—110
- ↑ Chen, Seiferas, 1985, p. 97
- ↑ 1 2 Blumer et al., 1987, p. 578
- ↑ Crochemore, Vérin, 1997, p. 192
- ↑ 1 2 Inenaga et al., 2005, pp. 156—158
- ↑ 1 2 Inenaga et al., 2001, p. 1
- ↑ Perrin, 1990, p. 10
- ↑ Sgarbas et al., 2003, p. 2
- ↑ 1 2 Crochemore, Hancart, 1997, pp. 3—6
- ↑ Серебряков и др., 2006, с. 50—54
- ↑ Рубцов, 2019, с. 89—94
- ↑ Hopcroft, Ullman, 1979, pp. 65—68
- ↑ 1 2 Blumer et al., 1984, pp. 111—114
- ↑ 1 2 3 4 5 6 7 8 Crochemore, Hancart, 1997, pp. 27—31
- ↑ 1 2 3 4 5 6 7 Inenaga et al., 2005, pp. 159—162
- ↑ Rubinchik, Shur, 2018, pp. 1—2
- ↑ 1 2 3 Fujishige et al., 2016, pp. 1—3
- ↑ 1 2 3 4 5 Crochemore, Hancart, 1997, pp. 31—36
- ↑ Паращенко, 2007, с. 19—22
- ↑ Blumer, 1987, p. 451
- ↑ Inenaga, 2003, p. 1
- ↑ 1 2 Blumer et al., 1987, pp. 585—588
- ↑ Blumer et al., 1987, pp. 588—589
- ↑ Blumer et al., 1987, p. 593
- ↑ Mohri et al., 2009, pp. 3558—3560
- ↑ Blumer, 1987, pp. 461—465
- ↑ Fiala, Greene, 1989, p. 490
- ↑ Larsson, 1996
- ↑ Brodnik, Jekovec, 2018, p. 1
- ↑ Senft, Dvořák, 2008, p. 109
- ↑ Inenaga et al., 2004
- ↑ Crochemore, Hancart, 1997, pp. 39—41
- ↑ Crochemore, Hancart, 1997, pp. 36—39
- ↑ Yamamoto et al., 2014, p. 675
- ↑ Crochemore et al., 2003, p. 211
- ↑ Mohri et al., 2009, p. 3553
- ↑ Faro, 2016, p. 145
Литература
- Sgarbas K. N., Fakotakis N. D., Kokkinakis G. K. Optimal insertion in deterministic DAWGs (англ.) // Theoretical Computer Science — Elsevier BV, 2003. — Vol. 301, Iss. 1-3. — P. 103—117. — ISSN 0304-3975; 1879-2294 — doi:10.1016/S0304-3975(02)00571-6
- Perrin D. Finite Automata (англ.) // Formal Models and Semantics: Handbook of Theoretical Computer Science / J. v. Leeuwen — Elsevier BV, 1990. — Vol. B. — P. 1—57. — ISBN 978-0-444-88074-1 — doi:10.1016/B978-0-444-88074-1.50006-8
- Weiner P. Linear pattern matching algorithms (англ.) // Symposium on Foundations of Computer Science — 1973. — P. 1—11. — 213 p. — doi:10.1109/SWAT.1973.13
- Pratt V. R. Improvements and applications for the Weiner repetition finder (англ.) — 1973.
- Slisenko A. O. Detection of periodicities and string-matching in real time (англ.) // Journal of Soviet mathematics — Springer Science+Business Media, 1983. — Vol. 22, Iss. 3. — P. 1316—1387. — ISSN 1072-3374; 1573-8795 — doi:10.1007/BF01084395
- Blumer A. C., Blumer J., Ehrenfeucht A., Haussler D., McConnell R. Building the minimal DFA for the set of all subwords of a word on-line in linear time (англ.) // Automata, Languages and Programming — 1984. — P. 109—118. — 526 p. — ISBN 978-3-540-13345-2 — doi:10.1007/3-540-13345-3_9
- Blumer A. C., Blumer J., Ehrenfeucht A., Haussler D., McConnell R. Complete inverted files for efficient text retrieval and analysis (англ.) // Journal of the ACM / D. J. Rosenkrantz — New York City: Association for Computing Machinery, 1987. — Vol. 34, Iss. 3. — P. 578—595. — ISSN 0004-5411 — doi:10.1145/28869.28873
- Blumer J. How much is that DAWG in the window? A moving window algorithm for the directed acyclic word graph (англ.) // Journal of Algorithms — Academic Press, 1987. — Vol. 8, Iss. 4. — P. 451—469. — ISSN 0196-6774; 1090-2678 — doi:10.1016/0196-6774(87)90045-9
- Chen M., Seiferas J. Efficient and Elegant Subword-Tree Construction (англ.) // (unknown type) / A. Apostolico, Z. Galil — Springer Berlin Heidelberg, 1985. — P. 97—107. — ISBN 978-3-642-82456-2 — doi:10.1007/978-3-642-82456-2_7
- Inenaga S. Bidirectional Construction of Suffix Trees (англ.) // Nordic Journal of Computing — 2003. — Vol. 10, Iss. 1. — P. 52—67. — ISSN 1236-6064
- Inenaga S., Hoshino H., Shinohara A., Takeda M., Arikawa S., Mauri G., Pavesi G. On-line construction of compact directed acyclic word graphs (англ.) // Discrete Applied Mathematics — Elsevier BV, 2005. — Vol. 146, Iss. 2. — P. 156—179. — ISSN 0166-218X; 1872-6771 — doi:10.1016/J.DAM.2004.04.012
- Inenaga S., Hoshino H., Shinohara A., Takeda M., Arikawa S. Construction of the CDAWG for a trie (англ.) // Prague Stringology Conference — Czech Technical University in Prague: 2001. — P. 37—48.
- Inenaga S., Shinohara A., Takeda M., Arikawa S. Compact directed acyclic word graphs for a sliding window (англ.) // Journal of Discrete Algorithms — Elsevier BV, 2004. — Vol. 2, Iss. 1. — P. 33—51. — ISSN 1570-8667; 1570-8675 — doi:10.1016/S1570-8667(03)00064-9
- Yamamoto J., I T., Bannai H., Inenaga S., Takeda M. Faster Compact On-Line Lempel-Ziv Factorization (англ.) // Symposium on Theoretical Aspects of Computer Science / E. Mayr, N. Portier — 2014. — Vol. 25. — P. 675—686. — ISBN 978-3-939897-65-1 — ISSN 1868-8969 — doi:10.4230/LIPICS.STACS.2014.675
- Fujishige Y., Tsujimaru Y., Inenaga S., Bannai H., Takeda M. Computing DAWGs and Minimal Absent Words in Linear Time for Integer Alphabets (англ.) // Mathematical Foundations of Computer Science / P. Faliszewski, A. Muscholl, R. Niedermeier — 2016. — Vol. 58. — P. 38:1–38:14. — ISBN 978-3-95977-016-3 — ISSN 1868-8969 — doi:10.4230/LIPICS.MFCS.2016.38
- Mohri M., Moreno P., Weinstein E. General suffix automaton construction algorithm and space bounds (англ.) // Theoretical Computer Science — Elsevier BV, 2009. — Vol. 410, Iss. 37. — P. 3553—3562. — ISSN 0304-3975; 1879-2294 — doi:10.1016/J.TCS.2009.03.034
- Faro S. Evaluation and Improvement of Fast Algorithms for Exact Matching on Genome Sequences (англ.) // Algorithms for Computational Biology / M. Botón-Fernández, C. M. Vide, M. A. Vega-Rodríguez — Springer Nature Switzerland AG, 2016. — P. 145—157. — ISBN 978-3-319-38827-4 — doi:10.1007/978-3-319-38827-4_12
- Crochemore M., Hancart C. Automata for Matching Patterns (англ.) // (unknown type) / G. Rozenberg, A. Salomaa — Springer Berlin Heidelberg, 1997. — Vol. 2. — P. 399—462. — ISBN 978-3-642-59136-5 — doi:10.1007/978-3-662-07675-0_9
- Crochemore M., Vérin R. On compact directed acyclic word graphs (англ.) // Structures in Logic and Computer Science: A Selection of Essays in Honor of A. Ehrenfeucht / J. Mycielski, G. Rozenberg, A. Salomaa — Springer Berlin Heidelberg, 1997. — P. 192—211. — ISBN 978-3-540-69242-3 — doi:10.1007/3-540-63246-8_12
- Crochemore M., Iliopoulos C. S., Navarro G., Pinzon Y. J. A Bit-Parallel Suffix Automaton Approach for (δ,γ)-Matching in Music Retrieval (англ.) // String Processing and Information Retrieval / M. A. Nascimento, E. S. de Moura, A. L. Oliveira — Springer Berlin Heidelberg, 2003. — P. 211—223. — ISBN 978-3-540-39984-1 — doi:10.1007/978-3-540-39984-1_16
- Hopcroft J. E., Ullman J. D. Introduction to Automata Theory, Languages, and Computation (англ.) — 1 — Massachusetts: Addison-Wesley, 1979. — 418 p. — ISBN 978-81-7808-347-6
- Fiala E. R., Greene D. H. Data compression with finite windows (англ.) // Communications of the ACM — New York City: Association for Computing Machinery, 1989. — Vol. 32, Iss. 4. — P. 490—505. — ISSN 0001-0782; 1557-7317 — doi:10.1145/63334.63341
- Senft M., Dvořák T. Sliding CDAWG Perfection (англ.) // String Processing and Information Retrieval / A. Turpin, A. Moffat, A. Amir — Springer Berlin Heidelberg, 2008. — P. 109—120. — ISBN 978-3-540-89097-3 — doi:10.1007/978-3-540-89097-3_12
- Larsson N. J. Extended application of suffix trees to data compression (англ.) // Proceedings. Data Compression Conference — IEEE, 1996. — P. 190—199. — ISBN 0-8186-7358-3 — ISSN 2375-0383; 2375-0391; 1068-0314; 2375-0359 — doi:10.1109/DCC.1996.488324
- Brodnik A., Jekovec M. Sliding Suffix Tree (англ.) // Algorithms — MDPI, 2018. — Vol. 11, Iss. 8. — P. 118. — ISSN 1999-4893 — doi:10.3390/A11080118
- Rubinchik M., Shur A. M. Eertree (англ.): An efficient data structure for processing palindromes in strings // European Journal of Combinatorics / P. O. de Mendez, P. Rosenstiehl, É. C. de Verdière, A. Björner, F. Brenti, A. Brouwer, P. Cameron, R. Cordovil, D. Foata, P. Frankl et al. — Elsevier BV, 2018. — Vol. 68. — P. 249—265. — ISSN 0195-6698; 1095-9971 — doi:10.1016/J.EJC.2017.07.021 — arXiv:1506.04862
- Серебряков В. А., Галочкин М. П., Фуругян М. Г., Гончар Д. Р. Теория и реализация языков программирования: Учебное пособие — М.: МЗ Пресс, 2006. — 352 с. — ISBN 5-94073-094-9
- Рубцов А. А. Заметки и задачи о регулярных языках и конечных автоматах — М.: МФТИ, 2019. — 112 с. — ISBN 978-5-7417-0702-9
- Паращенко Д. А. Обработка строк на основе суффиксных автоматов — СПб.: ИТМО, 2007. — 35 с.
Ссылки
- Суффиксный автомат. Построение за O(N) и применения. MAXimal.
- Суффиксный автомат. Викиконспекты ИТМО.
| Меры схожести строк | |
|---|---|
| Поиск подстроки | |
| Палиндромы | |
| Выравнивание последовательностей | |
| Суффиксные структуры | |
| Другое | |
| Общие понятия | |
|---|---|
| Тип 0 |
|
| Тип 1 |
|
| Тип 2 |
|
| Тип 3 | |
| Синтаксический анализ | |







