Apache Kafka
| Apache Kafka | |
|---|---|
| | |
| Тип | промежуточное программное обеспечение, ориентированное на обработку сообщений |
| Автор | Ния Нархид[вд] |
| Разработчики | Apache Software Foundation и LinkedIn |
| Написана на | Java[3] и Scala[4] |
| Операционная система | кроссплатформенность |
| Первый выпуск | 7 ноября 2010[1] |
| Последняя версия | |
| Репозиторий | github.com/apache/kafka gitbox.apache.org/repos/… |
| Лицензия | Apache License 2.0 и лицензия Apache |
| Сайт | kafka.apache.org (англ.) |
Apache Kafka — распределённый программный брокер сообщений с открытым исходным кодом, разрабатываемый в рамках фонда Apache на языках Java и Scala. Цель проекта — создание горизонтально масштабируемой платформы для обработки потоковых данных в реальном времени с высокой пропускной способностью и низкой задержкой. Kafka может подключаться к внешним системам (для импорта и экспорта данных) через Kafka Connect, а также может использоваться в задачах больших данных при помощи библиотеки Kafka Streams. Использует собственный двоичный протокол передачи данных на основе TCP, группирующий сообщения для снижения накладных расходов на сеть.
История
Изначально разработан в LinkedIn Джеем Крепсом, Нией Нархид[англ.] и Цзюнь Жао[5][6] для внутреннего использования; наименование было дано Крепсом в честь писателя Франца Кафки. В начале 2011 года разработчики открыли исходный код системы под лицензией Apache и проект был принят в Apache Incubator. 23 октября 2012 года стал проектом верхнего уровня[7]. В 2014 году основные авторы покинули LinkedIn и основали компанию Confluent[англ.] для коммерциализации проекта. В 2021 году Confluent провела первичное размещение, достигнув по его результатам капитализации в $10 млрд.
Архитектура
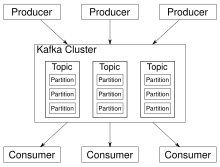
Kafka хранит сообщения, которые поступают от других процессов, называемых «производителями» (producers), в формате «ключ — значение». Данные могут быть разбиты на разделы (англ. partitions) в рамках разных тем (topics). Внутри раздела сообщения строго упорядочены по своим смещениям (offset), то есть по положению сообщения внутри раздела, а также индексируются и сохраняются вместе с временем создания. Другие процессы, называемые «потребителями» (consumers), могут считывать сообщения из разделов. Для потоковой обработки Kafka предлагает Streams API, позволяющий разрабатывать Java-приложения, которые получают из Kafka и записывают данные в Kafka. Система также работает с внешними системами обработки потоков, такими как Apache Apex, Apache Beam, Apache Flink, Apache Spark, Apache Storm и Apache NiFi.
Система работает в кластере из одного или нескольких узлов-брокеров, где разделы всех тем распределены по узлам кластера. Для обеспечения отказоустойчивости разделы реплицируются на несколько брокеров. Начиная с версии 0.11.0.0 система позволяет использовать транзакционную модель, близкую к используемым моделям в базах данных, которая обеспечивает обработку потока ровно один раз с использованием Streams API.
Kafka поддерживает два типа тем: обычные и компактные. Обычные темы можно настроить с указанием срока хранения или ограничения по максимальному занимаемому пространству. Система удаляет самые старые записи, если лимит занимаемого пространства превышен. Записи, срок хранения которых истёк, подлежат удалению вне зависимости от лимитов памяти. Значения в компактных темах не содержат срока хранения и не зависят ограничений памяти, вместо этого Kafka хранит и обрабатывает только самые новые значения для каждого ключа и гарантирует, что никогда не удалит последнее сообщение для каждого ключа[8]. Пользователи могут самостоятельно удалять сообщения, написав сообщение с пустым значением для удаления значения по ключу.
В Kafka есть пять основных API-интерфейсов:
- Producer API — для отправки сообщений в брокер;
- Consumer API — подписка на темы и получение сообщений из брокера;
- Connector API — подключение к системе и многократное использование Producer API и Consumer API;
- Streams API — преобразование входных потоков данных в выходные;
- Admin API — управление темами, брокерами и другими объектами.
Producer API и Consumer API имеют слабую связность, обеспечивая взаимодействие с ядром системы посредством обмена сообщениями; благодаря этому реализации этих API возможна на любом языке программирования без потери эффективности в сравнении с официальным Java API.
Kafka Connect
Kafka Connect (или Connect API) — фреймворк для импорта данных из других систем и для экспортирования данных в другие системы. Его добавили в версии Kafka 0.9.0.0. Фреймворк Connect создаёт «коннекторы», которые реализуют логику чтения и записи данных во внешние системы. Connect API определяет программный интерфейс, для реализации отдельных библиотек под различные языки программирования. На большинство крупнейших языков программирования уже есть реализации API. При этом, компания Apache Kafka не занимается разработкой таких библиотек.
Kafka Streams
Kafka Streams (Streams API) — библиотека потоковой обработки данных, написанная на Java, добавлена в версии Kafka 0.10.0.0. Позволяет создавать в функциональном стиле приложения потоковой обработки данных с поддержкой агрегации, преобразования и анализа данных, получаемых из Kafka-тем.
Kafka Streams содержит предметно-ориентированный язык, включающий операторы, обеспечивающие фильтрацию, отображение, группировку, управление окнами, агрегацию и объединение данных. Кроме того, Processor API можно использовать для реализации пользовательских операторов для более низкоуровневого подхода к разработке. DSL и Processor API можно использовать совместно. Для потоковой обработки для сохранения состояния Kafka Streams использует RocksDB[англ.]. Поскольку RocksDB может сохранять часть данных на диск, количество обрабатываемых данных может быть больше, чем доступная основная память. Для обеспечения отказоустойчивости все обновления локальных хранилищ также записываются в раздел в кластере Kafka. Это позволяет воссоздать состояние, прочитав эти разделы, и передать все данные в RocksDB.
Совместимость версий
До версии 0.9.x брокеры Kafka были обратно совместимы только с клиентами версии брокера и всех предыдущих версий. Начиная с Kafka 0.10.0.0 брокеры поддерживают совместимость с новыми клиентами. Если новый клиент подключается к более старой версии брокера, он может использовать только те функции, которые поддерживает этот брокер. Для Streams API полная совместимость начинается с версии 0.10.1.0: приложение Kafka Streams версии 0.10.1.0 несовместимо с брокерами версии 0.10.0.0 и старше.
Kafka осуществляет мониторинг брокеров, потребителей и производителей в дополнение к мониторингу ZooKeeper, который Kafka использует для координации между потребителями[9][10]. Существует несколько сторонних систем мониторинга для отслеживания производительности Kafka; также собирать метрики из Kafka можно с помощью инструментов платформы Java с визуализацией в JConsole[англ.][11].
Примечания
- ↑ https://github.com/kafka-dev/kafka/commit/e8540b6b090fad4cbe5bfc9b78be35bc3b1ad2b6
- ↑ Release 3.8.0 — 2024.
- ↑ https://projects.apache.org/json/projects/kafka.json
- ↑ The apache-kafka Open Source Project on Open Hub: Languages Page — 2006.
- ↑ Li, S. (2020). He Left His High-Paying Job At LinkedIn And Then Built A $4.5 Billion Business In A Niche You’ve Never Heard Of. Forbes. Retrieved 8 June 2021, from Forbes_Kreps Архивная копия от 31 января 2023 на Wayback Machine
- ↑ В переводах фигурирует также как «Чжан Рао»
- ↑ Apache Incubator: Kafka Incubation Status. Дата обращения: 4 марта 2023. Архивировано 17 октября 2022 года.
- ↑ Part 1: Apache Kafka for beginners - What is Apache Kafka? - CloudKarafka, Apache Kafka Message streaming as a Service (англ.). CloudKarafka. Дата обращения: 6 марта 2023. Архивировано 6 марта 2023 года.
- ↑ Monitoring Kafka performance metrics (амер. англ.) (6 апреля 2016). Дата обращения: 5 октября 2016. Архивировано 8 ноября 2020 года.
- ↑ Mouzakitis. Monitoring Kafka performance metrics (амер. англ.). datadoghq.com (6 апреля 2016). Дата обращения: 5 октября 2016. Архивировано 8 ноября 2020 года.
- ↑ Collecting Kafka performance metrics - Datadog (амер. англ.) (6 апреля 2016). Дата обращения: 5 октября 2016. Архивировано 27 ноября 2020 года.
Литература
- Нархид Ния, Шапира Гвен, Палино Тодд. Apache Kafka. Потоковая обработка и анализ данных. — СПб.: Питер, 2019. — 320 с. — ISBN 978-5-4461-0575-5.
Ссылки
- kafka.apache.org (англ.) — официальный сайт Apache Kafka
