
RSS — семейство XML-форматов, предназначенных для описания лент новостей, анонсов статей, изменений в блогах и т. п. Информация из различных источников, представленная в формате RSS, может быть собрана, обработана и представлена пользователю в удобном для него виде специальными программами-агрегаторами или-сервисами, такими как: NewsAlloy, FeedBucket и другими.
Семанти́ческая паути́на — общедоступная глобальная семантическая сеть, формируемая на базе Всемирной паутины путём стандартизации представления информации в виде, пригодном для машинной обработки.
Пространство имён — некоторое множество, под которым подразумевается модель, абстрактное хранилище или окружение, созданное для логической группировки уникальных идентификаторов.

Resource Description Framework — это разработанная консорциумом Всемирной паутины модель для представления данных, в особенности — метаданных.
Нотация 3 — широко распространённый краткий способ записи моделей RDF не в XML. Разработан с целью быть понятным человеку: N3 намного компактнее и удобнее для чтения, чем XML-запись RDF. Формат разработан Тимом Бернерсом-Ли и другими из сообщества Семантической паутины.
SPARQL — язык запросов к данным, представленным по модели RDF, а также протокол для передачи этих запросов и ответов на них. SPARQL является рекомендацией консорциума W3C и одной из технологий семантической паутины. Предоставление SPARQL-точек доступа является рекомендованной практикой при публикации данных во всемирной паутине.
Versa — язык запросов к данным в Resource Description Framework. Это компактный функциональный язык программирования, синтаксис которого напоминает Lisp, когда альтернативные языки запросов к RDF используют SQL основу, или специальные XML словари. Разработка Versa была вдохновлена XPath. На 2005, существует только реализация Versa на ЯП Python, в open-source 4Suite XML framework.
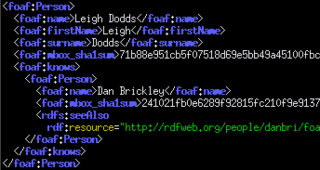
Друг друга, FOAF — проект по созданию модели машинно-читаемых домашних страниц и социальных сетей, основанный Либби Миллер и Дэном Брикли. Сердцем проекта является спецификация, которая определяет некоторые выражения, используемые в высказываниях о ком-либо, например: имя, пол и другие характеристики. Чтобы сослаться на эти данные используется идентификатор, включающий уникальные свойства друга.
Apache Maven — фреймворк для автоматизации сборки проектов на основе описания их структуры в файлах POM, на языке XML. Проект Maven издаётся сообществом Apache Software Foundation, где формально является частью Jakarta Project.

SIOC — семантическая технология соединённых онлайн-сообществ.

Do What The Fuck You Want To Public License (WTFPL) — простая и крайне пермиссивная лицензия для свободного программного обеспечения, произведений культуры и научных работ. Не накладывает на пользователя никаких ограничений. Отличается использованием в ней нецензурного выражения.
Turtle — формат для сериализации графов RDF. Является подмножеством формата Notation 3 (N3), разработанного Тимом Бернерсом-Ли и Дэном Конноли. Разработан Дэйвом Бэкеттом. Является расширением минималистичного формата N-Triples. Поддерживает только модели RDF. В протоколе SPARQL и языке запросов RDF для описания шаблонов графов используется подмножество формата N3, аналогичное Triple, но отличающееся использованием скобок для обозначения границ подграфов.
RELAX NG — один из языков описания структуры XML-документа. Являясь сам по себе XML-документом, схема в этом формате может быть записана с использованием альтернативного, более компактного синтаксиса. В сравнении с другими языками схем, RELAX NG относительно прост. RELAX NG был разработан в OASIS и впервые опубликован в 2003. Файлы, содержащие схемы RELAX NG, обычно имеют расширение ".rng", а в компактном синтаксисе — ".rnc".
GeoRSS — развивающийся стандарт для встраивания информации о местоположении в новостные ленты. Название стандарта происходит от распространенного и узнаваемого формата лент новостей — RSS.
GRDDL — формат надстройки для описания ресурсов различных диалектов и языков, рекомендация W3C, которая позволяет пользователям получать RDF триплеты из документов XML, включая XHTML. GRDDL спецификация показывает примеры использования XSLT, обычно этого вполне достаточно, чтобы получить необходимые знания и работы с дополнениями. Вышеуказанный текст одобрен в качестве рекомендации от 11 сентября 2007 года.
Adobe XMP — это технология, созданная Adobe и позволяющая пользователю добавлять дополнительную информацию в файлы, сохраняемые в форматах PNG, GIF, JPEG, PSD, TIFF и многих других. Технология XMP обеспечивает обмен метаданными между различными приложениями. Например, можно сохранить метаданные из одного файла в качестве шаблона, а затем экспортировать эти метаданные в другие файлы.
Web Application Description Language (WADL) — машинно-читаемое XML-описание для web-приложений HTTP (как правило, веб-сервисы REST). Аналог WSDL для REST.

JSON-LD — один из методов передачи связанных данных с использованием текстового формата JSON. Формат имеет целью упростить усилия разработчиков по преобразованию существующих JSON-данных в JSON-LD. JSON-LD является рекомендацией W3C и разрабатывался Linking Data Community Group, а затем — RDF Working Group.
Семанти́ческий механи́зм рассужде́ний, семанти́ческая машина формирования рассуждений или движо́к пра́вил — это часть программного обеспечения, способная вывести логические умозаключения из набора адекватно формализованных базовых знаний или аксиом. Понятие семантического механизма рассуждений обобщает понятие машины вывода, предоставляя более богатый набор механизмов для работы. Правила вывода обычно определяются с помощью языка онтологий и часто языков описательной логики. Многие семантические механизмы рассуждений используют логику первого порядка для выполнения рассуждений; вывод обычно происходит путём прямой и обратной цепочек рассуждений. Существуют также примеры вероятностных механизмов рассуждений, включая неаксиоматическую систему рассуждений Пей Ванга и вероятностные логические сети.
Извлечение знаний — создание знаний из структурированных и неструктурированных источников. Полученное знание должно иметь формат, позволяющий компьютерный ввод, и должно представлять знания так, чтобы облегчить логические выводы. Хотя по методике процесс подобен извлечению информации и процессу «Извлечения, Преобразования, Загрузки», главный критерий результата — создание структурированной информации или преобразование в реляционную схему. Это требует либо преобразования существующего формального знания, либо генерацией схемы, основанной на исходных данных.