diff
В вычислительной технике diff — утилита сравнения файлов, выводящая разницу между содержанием двух файлов. Эта программа выводит построчно изменения, сделанные в файле (для текстовых файлов). Современные реализации поддерживают также двоичные файлы. Вывод утилиты называется «diff», или, что более распространено, патч, так как он может быть применён с программой patch. Вывод других утилит сравнения файлов также часто называют «diff».
История
Утилита diff была разработана в начале 1970-х годов для операционной системы Unix, плода работы AT&T Bell Labs, в Мюррей-Хилл (Нью-Джерси). Финальная версия, распространяемая с 5-й версией Unix в 1974, была полностью написана Дугласом Макилроем.
Работе Макилроя предшествовала и повлияла программа сравнения Стива Джонсона на GECOS и программа доказательства Майка Леска. Доказательство также возникло в Unix и, как и diff, производило построчные изменения и даже использовало угловые скобки («>» и «<») для представления вставок и удалений строк в выводе программы. Однако эвристика, использовавшаяся в этих ранних приложениях, была сочтена ненадежной. Потенциальная полезность инструмента сравнения спровоцировала Макилроя на исследование и разработку более надежного инструмента, который можно было бы использовать в различных задачах, но который хорошо работал бы с ограничениями по обработке и размеру аппаратного обеспечения PDP-11. Его подход к проблеме стал результатом сотрудничества с людьми из Bell Labs, включая Альфреда Ахо, Эллиота Пинсона, Джеффри Ульмана и Гарольда С. Стоуна.
Алгоритм
Работа diff основана на нахождении наибольшей общей подпоследовательности (англ. longest common subsequence, проблема LCS). Например, имеются две последовательности элементов:
a b c d f g h j q z
a b c d e f g i j k r x y z
и надо найти наиболее длинную последовательность элементов, которая представлена в обеих последовательностях в одинаковом порядке. Это означает, что необходимо найти новую последовательность, которая может быть получена из первой последовательности удалением некоторых элементов или из второй последовательности удалением других элементов. В данном случае такой последовательностью будет являться
a b c d f g j z
После получения наибольшей общей последовательности остаётся только небольшой шаг до получения похожего на diff вывода:
e h i k q r x y
+ - + + - + + +
Использование
diff вызывается из командной строки с именами двух файлов в качестве аргументов: diff original new. Вывод команды представляет собой изменения, которые нужно произвести в исходном файле original, чтобы получить новый файл new. Если original и new — каталоги, то diff автоматически будет применён к каждому файлу, который существует в обоих каталогах. Все примеры в этой статье используют следующие два файла, original и new:
original: Эта часть документа
оставалась неизменной
от версии к версии. Если
в ней нет изменений, она
не должна отображаться.
Иначе это не способствует
выводу оптимального
объёма произведённых
изменений.
Этот абзац содержит
устаревший текст.
Он будет удалён
в ближайшем будущем.
В этом документе
необходима провести
проверку правописания.
С другой стороны, ошибка
в слове - не конец света.
Остальная часть абзаца
не требует изменений.
Новый текст можно
добавлять в конец документа.
| new: Это важное замечание!
Поэтому оно должно
быть расположено
в начале этого
документа!
Эта часть документа
оставалась неизменной
от версии к версии. Если
в ней нет изменений, она
не должна отображаться.
Иначе это не способствует
выводу оптимального
объёма информации.
В этом документе
необходимо провести
проверку правописания.
С другой стороны, ошибка
в слове - не конец света.
Остальная часть абзаца
не требует изменений.
Новый текст можно
добавлять в конец документа.
Этот абзац содержит
важные дополнения
для данного документа.
| Команда diff original new производит следующий нормальный дифф-вывод: 0a1,6
> Это важное замечание!
> Поэтому оно должно
> быть расположено
> в начале этого
> документа!
>
8,14c14
< объёма произведённых
< изменений.
<
< Этот абзац содержит
< устаревший текст.
< Он будет удалён
< в ближайшем будущем.
---
> объёма информации.
17c17
< необходима провести
---
> необходимо провести
24a25,28
>
> Этот абзац содержит
> важные дополнения
> для данного документа.
|
В этом традиционном формате вывода a означает добавлено (от англ. add), d — удалено, с — изменено. Перед буквами a, d или c стоят номера строк исходного файла, после них — номера строк конечного файла. Каждая строка, которая была добавлена, удалена или изменена, предваряется угловыми скобками.
По умолчанию, общие для исходного и конечного файлов номера строк не указываются. Строки, которые перемещены, показываются как добавленные на своём новом месте и удалённые из своего прошлого расположения.[1]
Варианты
В большинстве реализаций diff остаётся внешне неизменным с 1975 года. Модификации включают в себя улучшения основного алгоритма, добавление новых ключей команды, новых форматов вывода. Базовый алгоритм изложен в книгах An O(ND) Difference Algorithm and its Variations Юджина В. Майерса[2] и в A File Comparison Program Вебба Миллера и Майерса[3]. Алгоритм был независимо открыт и описан в Algorithms for Approximate String Matching Е. Укконеном[4]. Первые версии программы diff были разработаны для сравнения строк текстовых файлов, использующих символ новой строки как разделитель строк. В 1980-х поддержка двоичных файлов привела к изменениям в схеме работы и реализации программы.
Edit script
Edit script можно сгенерировать современными версиями diff с помощью опции -e. Результат для нашего примера будет выглядеть так:
24a Этот абзац содержит важные дополнения для данного документа. . 17c необходимо провести . 8,14c объёма информации. . 0a Это важное замечание! Поэтому оно должно быть расположено в начале этого документа! .
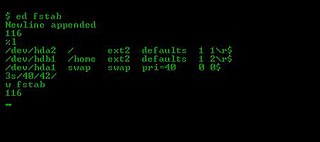
Чтобы использовать полученный скрипт для преобразования файла original к состоянию файла new, нам нужно добавить в конец скрипта две строки: одна содержит команду w (write), другая - q (quit). Например, так printf "w\nq\n" >> mydiff. Здесь мы дали diff-файлу имя mydiff. Преобразование произойдёт, когда мы дадим команду ed -s original < mydiff.
Контекстный формат
В BSD версии 2.8 (выпущенной в июле 1981 года) появился контекстный формат (-c) и возможность рекурсивного обхода дерева каталогов файловой системы (-r).
В контекстном формате изменённые строки показываются вместе с незатронутыми строками до и после изменённого фрагмента. Вставка любого количества незатронутых строк предоставляет контекст для патча. Контекст, состоящий из незатронутых строк, служит ссылкой для определения положения изменяемого фрагмента в целевом файле, даже если номера изменяемых строк в исходном и целевом файлах не совпадают. Контекстный формат представляет большую читабельность для людей и бо́льшую надёжность при применении патча, а вывод принимается в качестве входа для программы patch.
Число незатронутых строк до и после изменённого фрагмента может задаваться пользователем и быть даже нулём, но обычно по умолчанию равно трём строкам. Если контекст незатронутых строк во фрагменте пересекается с соседним фрагментом, то diff избежит копирования незатронутых строк и объединит смежные фрагменты в один.
Вывод команды diff -c original new:
*** /path/to/original ''timestamp''
--- /path/to/new ''timestamp''
***************
*** 1,3 ****
--- 1,9 ----
+ Это важное замечание!
+ Поэтому оно должно
+ быть расположено
+ в начале этого
+ документа!
+
Эта часть документа
оставалась неизменной
от версии к версии. Если
***************
*** 5,20 ****
не должна отображаться.
Иначе это не способствует
выводу оптимального
! объёма произведённых
! изменений.
!
! Этот абзац содержит
! устаревший текст.
! Он будет удалён
! в ближайшем будущем.
В этом документе
! необходима провести
проверку правописания.
С другой стороны, ошибка
в слове - не конец света.
--- 11,20 ----
не должна отображаться.
Иначе это не способствует
выводу оптимального
! объёма информации.
В этом документе
! необходимо провести
проверку правописания.
С другой стороны, ошибка
в слове - не конец света.
***************
*** 22,24 ****
--- 22,28 ----
не требует изменений.
Новый текст можно
добавлять в конец документа.
+
+ Этот абзац содержит
+ важные дополнения
+ для данного документа.
Универсальный формат
Универсальный формат (или unidiff) включает в себя технические улучшения, сделанные в контекстном формате, но разницу между старым и новым текстом выдаёт в более компактном виде. Универсальный формат обычно вызывается использованием «-u» опции командной строки. Этот вывод часто используется как patch для программ. Многие проекты специально просят присылать им «diffs» в универсальном формате, делая, тем самым, универсальный формат самым распространённым для обмена между разработчиками программного обеспечения.
Универсальные контекстные diff’ы впервые были разработаны en:Wayne Davison в августе 1990 (unidiff появляется в главе 14 comp.sources.misc). Столлман добавил поддержку универсального формата в утилиту GNU Project's diff одним месяцем позже и эта функциональность дебютировала в GNU diff 1.15, выпущенной в январе 1991. С тех пор GNU diff обобщил форматы контекстов, чтобы позволить произвольное форматирование diff'ов.
Файл в универсальном формате начинается с тех же самых двух строк, что и контекстный формат, за исключением того, что оригинальный файл начинается с «---», а новый файл начинается с «+++». Следом за ними следует один или больше измененных фрагментов, которые содержат построчные изменения в файлах. Строки без изменений начинаются с пробела, добавленные строки начинаются со знака плюс, удалённые строки начинаются со знака минус.
Фрагмент начинается с информации о диапазоне и сразу за ним следуют добавленные строки, удалённые строки и любое количество контекстных строк. Информация о диапазоне окружена двойными знаками @ и объединена в одну строку, в отличие от двух строк в (контекстном формате). Информация о диапазоне имеет следующий формат:
@@ -l,s +l,s @@ optional section heading
Информация о диапазоне состоит из двух частей. Часть для оригинального файла начинается с минуса, а часть для нового файла начинается с плюса. Каждая часть в формате l, s, где l — номер строки, с которой начинаем, а s — количество строк, которые были изменены в текущем фрагменте для каждого из файлов, соответственно (то есть, в первом случае, это сумма выведенных строк, начинающихся с пробела и с минуса, во втором — строк, начинающихся с пробела и с плюса). Во многих версиях GNU diff в каждом диапазоне запятая и замыкающая s могут быть опущены. В этом случае s по умолчанию равна 1. Обратите внимание, что единственное полезное значение только у l — номер строки первого диапазона, остальные значения могут быть вычислены из diff’а.
Фрагмент диапазона для оригинального файла должен быть суммой всех контекстных и удалённых (включая изменённые) строк фрагмента. Фрагмент диапазона для нового файла должен включать в себя сумму всех контекстных и добавленных (включая изменённые) строк фрагмента.
Фрагмент диапазона может быть предварён заголовком секции или функции, частью которой является фрагмент. Это обычно полезно для чтения самого фрагмента. Когда создается diff с использованием GNU, diff заголовок определяется регулярным выражением[5].
Если строка была изменена, она показывается и как удалённая, и как добавленная. Так как удалённая и добавленная строки находятся в смежных фрагментах, то эти строки показываются рядом друг с другом[6]. Например:
-check this document. On +check this document. On
Команда diff -u original new создаст следующий вывод:
--- /path/to/original ''timestamp''
+++ /path/to/new ''timestamp''
@@ -1,3 +1,9 @@
+Это важное замечание!
+Поэтому оно должно
+быть расположено
+в начале этого
+документа!
+
Эта часть документа
оставалась неизменной
от версии к версии. Если
@@ -5,16 +11,10 @@
не должна отображаться.
Иначе это не способствует
выводу оптимального
-объёма произведённых
-изменений.
-
-Этот абзац содержит
-устаревший текст.
-Он будет удалён
-в ближайшем будущем.
+объёма информации.
В этом документе
-необходима провести
+необходимо провести
проверку правописания.
С другой стороны, ошибка
в слове - не конец света.
@@ -22,3 +22,7 @@
не требует изменений.
Новый текст можно
добавлять в конец документа.
+
+Этот абзац содержит
+важные дополнения
+для данного документа.
Обратите внимание, чтобы нормально отделить имена файлов от временных меток, используется табуляция. Это незаметно на экране и может быть утеряно при копировании/вставке из консоли.
Есть несколько изменений и расширений для diff форматов, которые используют и понимают различные программы. Например, некоторые системы управления версиями, такие как Subversion, указывают номер версии, «рабочую копию» или любой другой комментарий в дополнение к временной метке в заголовке diff’a.
Некоторые программы позволяют создавать diff’ы для нескольких разных файлов и сливают их в один, используя заголовок для каждого изменённого файла, который может выглядеть примерно так:
Index: path/to/file.cpp
Специальный вид файлов, которые не заканчиваются новой строкой, не поддерживается. Ни unidiff утилита, ни POSIX diff стандарт не определяют способ обработки таких файлов (более того, файлы такого типа не являются «текстовыми» в определении POSIX[7]).
Программа patch ничего не знает о реализации специального вывода команды diff.
См. также
- cmp
- comm
- diff3
- kdiff3 Архивная копия от 29 декабря 2020 на Wayback Machine
- Meld
- Microsoft File Compare
- rsync
- tkdiff
- wdiff — обёртка для diff для сравнения файлов по словам
- WinMerge
- xdelta — diff для двоичных файлов
- Дельта-кодирование
- Наибольшая общая подпоследовательность
- Расстояние Левенштейна
- Система управления версиями
Примечания
- ↑ David MacKenzie, Paul Eggert, and Richard Stallman. Comparing and Merging Files with GNU Diff and Patch (англ.). — 1997. Архивировано 15 февраля 2007 года.
- ↑ E. Myers. An O(ND) Difference Algorithm and Its Variations (англ.) // Algorithmica[англ.] : journal. — 1986. — Vol. 1, no. 2. — P. 251—266. Архивировано 20 августа 2008 года.
- ↑ Webb Miller and Eugene W. Myers. A File Comparison Program // Software — Practice and Experience. — 1985. — Т. 15, № 11. — С. 1025—1040.
- ↑ E. Ukkonen. Algorithms for Approximate String Matching (англ.) // Information and Computation[англ.] : journal. — 1985. — Vol. 64. — P. 100—118.
- ↑ 2.2.3 Showing Which Sections Differences Are in Архивная копия от 26 мая 2013 на Wayback Machine, GNU diffutils manual (англ.)
- ↑ Unified Diff Format Архивная копия от 5 апреля 2013 на Wayback Machine by Guido van Rossum, Июнь 14, 2006 (англ.)
- ↑ http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap03.html#tag_03_205 Архивная копия от 29 апреля 2013 на Wayback Machine Section 3.205 (англ.)
Ссылки
- Пакет GNU diffutils Архивная копия от 11 июня 2007 на Wayback Machine включает в себя diff. Распространяется под GNU General Public License.
- diffutils для Win32 Архивная копия от 12 июня 2007 на Wayback Machine — часть GnuWin32
- Онлайновый интерфейс к diff Архивная копия от 14 сентября 2017 на Wayback Machine (рус.)
- Алгоритм diff на C# Архивная копия от 15 июня 2007 на Wayback Machine — Исходный код алгоритма diff и его вариантов на C#
| Только локальные | |
|---|---|
| Клиент-серверные | |
| Распределённые | |