METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering (2004)) — метрика для оценки качества машинного перевода. Метрика базируется на использовании n-грамм и ориентирована на использование статистической и точной оценки исходного текста. В отличие от метрики BLEU[англ.], данная метрика использует функции сопоставления синонимов вместе с точным соответствием слов. Метрика была разработана, чтобы решить проблемы, которые были найдены в более популярной метрике BLEU, а также создать хорошую корреляцию с оценкой экспертов на уровне словосочетаний или предложений.

В результате запуска метрики на уровне словосочетаний корреляция с человеческим решением составляла 0.964, тогда как метрика BLEU составляла 0.817 на том же наборе входных данных. На уровне предложения максимальная корреляция с оценкой экспертов была 0.403[1].
Алгоритм
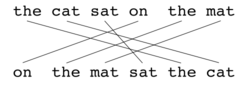
Как и в метрике BLEU, основная единица для оценки — предложение, алгоритм сначала проводит выравнивание текста между двумя предложениями, строкой эталонного перевода и строкой входного текста для оценивания (см. рисунки а и б). Данная метрика использует несколько этапов установления соответствия между словами машинного перевода и эталонного перевода для сопоставления двух строк:
- Точное установление соответствия — определяются строки, которые являются идентичными в эталонном и машинном переводе.
- Установление соответствия основ — проводится стемминг (выделение основы слова), и определяются слова с одинаковым корнем в эталонном и машинном переводе.
- Установление соответствия синонимов — определяются слова, которые являются синонимами в соответствии с WordNet.
Выравнивание — это множество соответствий между n-gram-ами. На соответствие налагается следующее ограничение: каждый n-грамм в предложении-кандидате должен соответствовать одному или ни одному n-gram-у в эталонном предложении. Если есть два выравнивания с тем же количеством совпадений, то выбирается то, которое имеет наименьшее количество пересечений для совпадений. В данном случае будет выбран вариант (а). Этапы сравнения с эталонными переводами выполняются последовательно, и на каждом из них ко множеству соответствий добавляются только те n-gram-ы, которые не имели соответствия на предыдущих этапах. Как только будет пройден последний этап, окончательный n-gram P вычисляется по следующей формуле[2]:
| Пример пары слов, которые будут сопоставлены вместе | |||
| Этап сравнения | Кандидат | Эталонный перевод | Совпадение |
|---|---|---|---|
| Точное совпадение | good | good | Yes |
| Стемминг | goods | good | Yes |
| Синоним | well | good | Yes |

где — количество n-грамм в машинном переводе, которые также были найдены в эталонном переводе, а — количество n-грамм в машинном переводе. N-gram (общий n-gram для эталонных переводов) вычисляется по следующей формуле:




где — количество n-грамм в эталонном переводе. Точность и полнота комбинируются, используя формулу гармонического среднего, в которой вес полноты в 9 раз больше веса точности:


Данная формула используется только для сравнения одиночных слов, которые совпали в эталонном и машинном переводе. Для того чтобы учитывать еще и словосочетания, которые совпадают, используется так называемый штраф . Для этого n-gram объединяют в несколько возможных групп. Штраф вычисляется по следующей формуле:


где c — число групп n-gram, а — количество n-грамм, которые объединили в группы Тогда финальный показатель качества вычисляется по следующей формуле:


Примеры
| Эталонный перевод: | the | cat | sat | on | the | mat |
| Машинный перевод: | on | the | mat | sat | the | cat |
Score: 0.5000 = Fmean: 1.0000 * (1 - Penalty: 0.5000) Fmean: 1.0000 = 10 * Precision: 1.0000 * Recall: 1.0000 / (Recall: 1.0000 + 9 * Precision: 1.0000) Penalty: 0.5000 = 0.5 * (Fragmentation: 1.0000 ^3) Fragmentation: 1.0000 = Chunks: 6.0000 / Matches: 6.0000
| Эталонный перевод: | the | cat | sat | on | the | mat |
| Машинный перевод: | the | cat | sat | on | the | mat |
Score: 0.9977 = Fmean: 1.0000 * (1 — Penalty: 0.0023) Fmean: 1.0000 = 10 * Precision: 1.0000 * Recall: 1.0000 / (Recall: 1.0000 + 9 * Precision: 1.0000) Penalty: 0.0023 = 0.5 * (Fragmentation: 0.1667 ³) Fragmentation: 0.1667 = Chunks: 1.0000 / Matches: 6.0000
| Эталонный перевод: | the | cat | sat | on | the | mat | |
| Машинный перевод: | the | cat | was | sat | on | the | mat |
Score: 0.9654 = Fmean: 0.9836 * (1 - Penalty: 0.0185) Fmean: 0.9836 = 10 * Precision: 0.8571 * Recall: 1.0000 / (Recall: 1.0000 + 9 * Precision: 0.8571) Penalty: 0.0185 = 0.5 * (Fragmentation: 0.3333 ^3) Fragmentation: 0.3333 = Chunks: 2.0000 / Matches: 6.0000
Развитие
Исследователями предлагались различные модификации METEOR, в частности, предназначенные для расширения её оценки с уровня словосочетаний до уровня предложений[2].
См. также
- BLEU[англ.]
- F1 score[англ.]
- NIST (metric)[англ.]
- ROUGE (metric)[англ.]
- Word error rate[англ.]
- Noun-Phrase Chunking[англ.]
Литература
- Banerjee, S. and Lavie, A. (2005) «METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments» in Proceedings of Workshop on Intrinsic and Extrinsic Evaluation Measures for MT and/or Summarization at the 43rd Annual Meeting of the Association of Computational Linguistics (ACL-2005), Ann Arbor, Michigan, June 2005
- Lavie, A., Sagae, K. and Jayaraman, S. (2004) «The Significance of Recall in Automatic Metrics for MT Evaluation» in Proceedings of AMTA 2004, Washington DC. September 2004
- ↑ Banerjee, S. and Lavie, A. (2005)
Ссылки
- The METEOR Automatic Machine Translation Evaluation System (including link for download)
Примечания
- ↑ Alon Lavie and Abhaya Agarwal. Meteor: An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments // Proceedings of the Second Workshop on Statistical Machine Translation. — 2007. — С. 228—231. Архивировано 26 октября 2020 года.
- ↑ Michael Denkowski, Alon Lavie. [https://aclanthology.org/N10-1031.pdf Extending the METEOR Machine Translation Evaluation Metric to the Phrase Level] // Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the ACL. — 2010. — С. 250–253. Архивировано 16 октября 2022 года.