NoSQL
NoSQL (от англ. not only SQL — не только SQL) — обозначение широкого класса разнородных систем управления базами данных (СУБД), появившихся в конце 2000-х — начале 2010-х годов и существенно отличающихся от традиционных реляционных СУБД с доступом к данным средствами языка SQL. Применяется к системам, в которых делается попытка решить проблемы масштабируемости и доступности за счёт полного или частичного отказа от требований атомарности и согласованности данных[1].
Происхождение
История названия
Изначально слово NoSQL являлось акронимом из двух слов английского языка: No («Не») и SQL (сокращение от англ. Structured Query Language — «структурированный язык запросов»), что даёт термину смысл «отрицающий SQL». Возможно, что первые, кто стал употреблять этот термин, хотели сказать «No RDBMS» («не реляционная СУБД») или «no relational» («не реляционный»), но NoSQL звучало лучше и в итоге прижилось (в качестве альтернативы предлагалось также NonRel). Позднее для NoSQL было придумано объяснение «Not Only SQL» («не только SQL»). NoSQL стал общим термином для различных баз данных и хранилищ, но он не обозначает какую-либо одну конкретную технологию или продукт[2].
Развитие идеи
Нереляционные системы использовались на всём протяжении истории современной вычислительной техники, и даже доминировали во времена первых мейнфреймов, пока не были вытеснены реляционными СУБД, сохранив применение в специализированных системах (например, иерархических службах каталогов). Распространение нереляционных СУБД в 2000-е годы произошло из-за необходимости создания параллельных распределённых систем для высокомасштабируемых интернет-приложений, таких как поисковые системы[2]. В начале 2000-х годов Google построил высокомасштабируемую поисковую систему и приложения: GMail, Google Maps, Google Earth, применив распределённую файловую систему, распределённую систему координации и технику MapReduce. Позднее была создана масштабируемая СУБД категории «семейство столбцов». Публикация компанией Google описаний этих технологий привела к всплеску интереса среди разработчиков открытого программного обеспечения, в результате чего был создан Hadoop и запущены связанные с ним проекты, призванные создать подобные Google технологии. В 2007 году примеру Google последовал Amazon.com, опубликовав статьи о высокодоступной базе данных Amazon DynamoDB[3].
Поддержка гигантов индустрии менее чем за пять лет привела к широкому распространению технологий NoSQL (и подобных) для управления «большими данными», а к направлению присоединились другие участники, в том числе IBM, Facebook, Netflix, eBay, Hulu, Yahoo!, со своими проприетарными и открытыми решениями[3].
Основные черты
Традиционные СУБД ориентируются на требования ACID к транзакционной системе: атомарность (англ. atomicity), согласованность (англ. consistency), изолированность (англ. isolation), долговечность (англ. durability), тогда как в NoSQL вместо ACID может рассматриваться набор свойств BASE[1]:
- базовая доступность (англ. basic availability) — каждый запрос гарантированно завершается (успешно или безуспешно).
- гибкое состояние (англ. soft state) — состояние системы может изменяться со временем, даже без ввода новых данных, для достижения согласования данных.
- согласованность в конечном счёте (англ. eventual consistency) — данные могут быть некоторое время рассогласованы, но приходят к согласованию через некоторое время.
Термин «BASE» был предложен Эриком Брюером, автором теоремы CAP, согласно которой, в распределённых вычислениях можно обеспечить только два из трёх свойств: согласованность данных, доступность или устойчивость к разделению[1].
Разумеется, системы на основе BASE не могут использоваться в любых приложениях: для функционирования биржевых и банковских систем использование транзакций является необходимостью. В то же время свойства ACID, какими бы желанными они ни были, практически невозможно обеспечить в системах с многомиллионной веб-аудиторией, вроде amazon.com[1]. Таким образом, проектировщики NoSQL-систем жертвуют согласованностью данных ради достижения двух других свойств из теоремы CAP[4]. Некоторые СУБД, например, Riak, позволяют настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов путём задания количества узлов, необходимых для подтверждения успеха транзакции.[5]
Решения NoSQL отличаются не только проектированием с учётом масштабирования. Другими характерными чертами NoSQL-решений являются[6][7]:
- Применение различных типов хранилищ[6].
- Возможность разработки базы данных без задания схемы[6][7].
- Линейная масштабируемость (добавление процессоров увеличивает производительность)[6].
Типы систем
Описание схемы данных в случае использования NoSQL-решений может осуществляться через использование различных структур данных: хеш-таблиц, деревьев и других.
В зависимости от модели данных и подходов к распределённости и репликации в NoSQL-движении выделяются четыре основных типа систем: «ключ — значение» (англ. key-value store), «семейство столбцов» (column-family store), документоориентированные (document store), графовые.
Ключ — значение
Модель «ключ — значение» является простейшим вариантом, использующим ключ для доступа к значению. Такие системы используются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в системах, спроектированных с прицелом на масштабируемость. Примеры таких хранилищ — Berkeley DB, MemcacheDB[англ.], Redis, Riak, Amazon DynamoDB[6].
Семейство столбцов
Другой тип систем — «семейство столбцов», прародитель этого типа — система Google BigTable. В таких системах данные хранятся в виде разреженной матрицы, строки и столбцы которой используются как ключи. Типичным применением этого типа СУБД является веб-индексирование, а также задачи, связанные с большими данными, с пониженными требованиями к согласованности. Примерами СУБД данного типа являются: Apache HBase, Apache Cassandra, ScyllaDB[англ.], Apache Accumulo[англ.], Hypertable[англ.][6][8].
Системы типа «семейство столбцов» и документно-ориентированные системы имеют близкие сценарии использования: системы управления содержимым, блоги, регистрация событий. Использование временных меток позволяет использовать этот вид систем для организации счётчиков, а также регистрации и обработки различных данных, связанных со временем[8].
В отличие от столбцового хранения, применяемого в некоторых реляционных СУБД, хранящих данные по столбцам в сжатом виде для эффективности в OLAP-сценариях, модель «семейство столбцов» хранит данные построчно, и обеспечивает высокую производительность, прежде всего, в оперативных сценариях, тогда как для запросов, требующих обхода большого объёма данных с агрегацией результатов, как правило, неэффективна[8][9].
Документоориентированная СУБД
Документоориентированные СУБД служат для хранения иерархических структур данных. Находят своё применение в системах управления содержимым, издательском деле, документальном поиске. Примеры СУБД данного типа — CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML[6].
Графовая СУБД
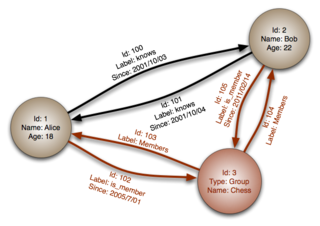
Графовые СУБД применяются для задач, в которых данные имеют большое количество связей, например, социальные сети, выявление мошенничества. Примеры: Neo4j, OrientDB, AllegroGraph[англ.], Blazegraph[10], InfiniteGraph, FlockDB, Titan[6][8].
Так как рёбра графа материализованы (англ. materialized), то есть, являются хранимыми, обход графа не требует дополнительных вычислений (как соединение в SQL), но для нахождения начальной вершины обхода требуется наличие индексов. Графовые СУБД как правило поддерживают ACID, а также поддерживают специализированные языки запросов, такие как Gremlin, Cypher, SPARQL, GraphQL.
UnQL
В июле 2011 компания Couchbase, разработчик CouchDB, Memcached и Membase, анонсировала создание нового SQL-подобного языка запросов — UnQL (Unstructured Data Query Language). Работы по созданию нового языка выполнили создатель SQLite Ричард Гипп (англ. Richard Hipp) и основатель проекта CouchDB Дэмиен Кац (англ. Damien Katz). Разработка передана сообществу на правах общественного достояния[11][12][13]. Последний раз UnQL обновлялся в августе 2011 года[14], фактически проект не получил никакой поддержки.
Примечания
- ↑ 1 2 3 4 Vaish, 2013, What NoSQL is and what it is not.
- ↑ 1 2 Tiwari, 2011, Chapter 1: NoSQL: What It Is and Why You Need it > Definition and Introduction.
- ↑ 1 2 Tiwari, 2011, pp. 4—6.
- ↑ Brewer, Eric A. A Certain Freedom: Thoughts on the CAP Theorem (англ.) // Proceeding of the IXXX ACM SIGACT-SIGOPS symposium on Principles of distributed computing. — N. Y.: ACM, 2010. — Iss. 29, no. 1. — P. 335—336. — ISBN 978-1-60558-888-9. — doi:10.1145/1835698.1835701.
- ↑ Zachary Kessin. Building Web Applications with Erlang. — O’Reilly Media, Inc., 2012. — P. 13. — 156 p. — ISBN 978-1-4493-0996-1.
- ↑ 1 2 3 4 5 6 7 8 McCreary, Kelly, 2013, 1.1. What is NoSQL?.
- ↑ 1 2 Vaish, 2013, Why NoSQL?.
- ↑ 1 2 3 4 Curé, Blin, 2014.
- ↑ McCreary, Kelly, 2013, 4.3. Column family (Bigtable) stores.
- ↑ Blazegraph (Formerly Bigdata) Архивная копия от 13 июня 2015 на Wayback Machine, w3c
- ↑ UnQL Query Language Unveiled by Couchbase and SQLite. Дата обращения: 7 августа 2011. Архивировано 25 сентября 2011 года.
- ↑ Welcome to the UnQL Specification home. Дата обращения: 7 августа 2011. Архивировано 25 сентября 2011 года.
- ↑ Создатели CouchDB и SQLite представили UnQL, аналог SQL для систем NoSQL Архивная копия от 14 сентября 2011 на Wayback Machine, новость на OpenNet
- ↑ UnQL: Timeline. unql.sqlite.org. Дата обращения: 18 октября 2021. Архивировано 18 октября 2021 года.
Литература
- Мартин Фаулер, Прамодкумар Дж. Садаладж. NoSQL: новая методология разработки нереляционных баз данных = NoSQL Distilled. — М.: «Вильямс», 2013. — 192 с. — ISBN 978-5-8459-1829-1.
- Леонид Черняк. Смутное время СУБД // Открытые системы. — 2012. — № 2.
- Dan McCreary, Ann Kelly. Making Sense of NoSQL: A guide for managers and the rest of us. — Manning Publications, 2013. — 312 p. — ISBN 978-1-61729-107-4.
- Olivier Curé, Guillaume Blin. Chapter 2. Database Management Systems // RDF Database Systems: Triples Storage and SPARQL Query Processing. — Elsevier Science, 2014. — 256 p. — ISBN 978-0-12-800470-8.
- Shashank Tiwari. Professional NoSQL. — John Wiley & Sons Inc, 2011. — 384 p. — ISBN 9780470942246.
Ссылки
- Matthew Aslett, Updated database landscape graphic Архивная копия от 1 июня 2013 на Wayback Machine, November 2nd, 2012 (диаграмма)