
MIDI — стандарт цифровой звукозаписи на формат обмена данными (интерфейс) между электронными музыкальными инструментами.
Файл — именованная область данных на носителе информации, используемая как базовый объект взаимодействия с данными в операционных системах.
Формат файла, формат данных — спецификация структуры данных, записанных в компьютерном файле. Идентификатор формата файла, как правило, указывается в конце имени файла в виде «расширения». Расширение имени файла помогает идентифицировать формат данных, содержащихся в файле, программам, которые могут с ним работать. Иногда формат данных дополнительно указывается в начале содержимого файла.

Биоинформа́тика — междисциплинарная область, объединяющая общую биологию, молекулярную биологию, кибернетику, генетику, химию, компьютерные науки, математику и статистику. Крупномасштабные биологические проблемы, требующие анализа больших объёмов данных, решаются биоинформатикой с вычислительной точки зрения. Биоинформатика главным образом включает в себя изучение и разработку компьютерных методов и направлена на получение, анализ, хранение, организацию и визуализацию биологических данных.

Total Commander — файловый менеджер с закрытым исходным кодом, работающий на платформах Microsoft Windows и Android.
Windows Installer — подсистема Microsoft Windows, обеспечивающая установку программ (инсталлятор). Является компонентом Windows, начиная с Windows 2000; может доустанавливаться и на более ранние версии Windows. Вся необходимая для установки информация содержится в установочных пакетах, имеющих расширение .msi.
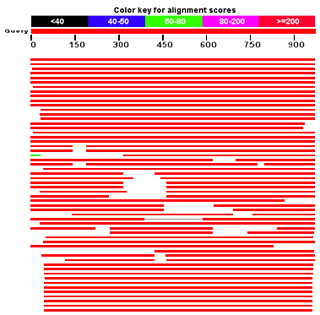
BLAST — семейство компьютерных программ, служащих для поиска гомологов белков или нуклеиновых кислот, для которых известна первичная структура (последовательность) или её фрагмент. Используя BLAST, исследователь может сравнить имеющуюся у него последовательность с последовательностями из базы данных и найти последовательности предполагаемых гомологов. Является важнейшим инструментом для молекулярных биологов, биоинформатиков и систематиков. Программа BLAST была разработана группой учёных: Стивен Альтшуль, Уоррен Гиш, Вебб Миллер, Юджин Майерс и Дэвид Липман в системе Национальных институтов здравоохранения США. Первая публикация с описанием программы вышла в Журнале молекулярной биологии в 1990 году.
sha1sum — программа, позволяющая вычислять значения хеш-сумм файлов по алгоритму SHA-1. В обычном случае вычисленные хеши выводятся. В других случаях программа сверяет вычисленные значения со значениями, сохраненными в файле.
Autorun.inf — файл, используемый для автоматического запуска или установки приложений и программ на носителях информации в среде операционной системы Microsoft Windows. Этот файл должен находиться в корневом каталоге файловой системы устройства, для которого осуществляется автозапуск. Файл делится на структурные элементы — блоки. Название блоков пишется в квадратных скобках. Описание блоков содержит пары параметр→значение.
Перенаправление ввода-вывода — возможность командной оболочки ряда операционных систем перенаправлять стандартные потоки в определённое пользователем место, например, в файл. Характерна для Unix-подобных операционных систем, но в разной степени реализована и в операционных системах других семейств.
Те́кстовые да́нные — представление информации строкового типа в вычислительной системе. В MIME закодированным таким образом данным соответствует тип text/plain.
Препроцессор C/C++ — программа, подготавливающая код программы на языке C/C++ к компиляции.
«Генная онтология» — биоинформатический проект, посвященный созданию унифицированной терминологии для аннотации генов и генных продуктов всех биологических видов.
FASTA — текстовый формат для нуклеотидных или полипептидных последовательностей, в котором нуклеотиды или аминокислоты обозначаются при помощи однобуквенных кодов. Из-за своей простоты и практичности в настоящее время используется большинством программ работы с биологическими последовательностями. Файлы данного формата могут содержать названия последовательностей, их идентификаторы в базах данных и комментарии. В зависимости от природы содержащихся в нем биологических последовательностей файл формата FASTA может иметь различные расширения.
Выра́внивание после́довательностей — биоинформатический метод, основанный на размещении двух или более последовательностей мономеров ДНК, РНК или белков друг под другом таким образом, чтобы легко увидеть сходные участки в этих последовательностях. Сходство первичных структур двух молекул может отражать их функциональные, структурные или эволюционные взаимосвязи. Выровненные последовательности оснований нуклеотидов или аминокислот обычно представляются в виде строк матрицы. Добавляются разрывы между основаниями таким образом, чтобы одинаковые или похожие элементы были расположены в следующих друг за другом столбцах матрицы.

YaCy — свободно распространяемая децентрализованная поисковая система, построенная по принципу одноранговой сети (P2P). Есть версии для Windows, Linux, MacOSX. Основной программный модуль, написанный на Java, функционирует на нескольких тысячах компьютеров участников сети YaCy. Каждый участник проекта независимо исследует Интернет, анализируя и индексируя найденные страницы и складывает результаты индексирования в общую базу данных, который совместно используется всеми пользователями YaCy по принципу P2P.

UniProt — открытая база данных последовательностей белков. Консорциум UniProt действует с 2003 года. Единая база данных UniProt была создана путём объединения нескольких баз. UniProt состоит из четырёх крупных баз данных и охватывает различные аспекты анализа белковых последовательностей. Многие из последовательностей стали известны в результате реализации проектов секвенирования геномов последних лет. Кроме того, база данных UniProt содержит большое количество информации о биологических функциях белков, полученной из научной литературы.

Семейство белков — это группа эволюционно связанных белков, обладающих гомологичной аминокислотной последовательностью. Этот термин почти синонимичен термину «семейство генов», поскольку, если белки имеют гомологичные аминокислотные последовательности, то и кодирующие их гены также должны проявлять значительную степень гомологии в нуклеотидных последовательностях ДНК. Этот термин не следует путать с термином «семейство» в таксономии видов живых организмов.

Pfam — база данных семейств белковых доменов. Каждое семейство в ней представлено множественным выравниванием фрагментов белковых последовательностей и скрытой марковской моделью (HMM). На март 2021 года в Pfam содержалось 19 179 записей (семейств), объединённых в 645 кланов.

STRING — база данных и веб-ресурс для поиска информации об известных и предсказанных белок-белковых взаимодействиях.