
Юнико́д — стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. В настоящее время стандарт является преобладающим в Интернете.

ASCII — стандарт кодирования знаков латинского алфавита, цифр, некоторых специальных знаков и управляющих последовательностей, принятый в 1963 году Американской ассоциацией стандартов как основной способ представления текстовых данных в ЭВМ.
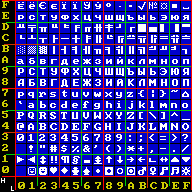
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для русских версий Microsoft Windows до 10-й версии. В прошлом пользовалась довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице.
«Альтернати́вная кодиро́вка» — основанная на CP437 кодовая страница, где все специфические европейские символы во второй половине заменены на кириллицу, а псевдографические символы оставлены нетронутыми. Это не портит вида программ, использующих эти символы для отрисовки рамок, а также обеспечивает использование в них символов кириллицы. Недостатком данной кодировки является разрыв в порядке малых кириллических букв. Разработана в 1984 году в ИВНД Академии наук СССР, была названа и описана в статье и пользовалась большой популярностью.

UTF-8 — распространённый стандарт кодирования символов, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт, и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII. Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
КОИ-7 — семибитная кодировка для русского языка и обмена информацией, основанная на ASCII. КОИ-7 описана в ГОСТ 13052-67, 13052-74 и 27463-87. КОИ-7 включает в себя 3 «набора» — Н0, Н1, Н2. Н0 — это просто US-ASCII ; в Н1 все латинские буквы заменены на русские; в Н2 заглавные латинские буквы оставлены, а строчные заменены на заглавные русские.
UTF-16 в информатике — один из способов кодирования символов из Юникода в виде последовательности 16-битных слов. Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF . При этом каждый символ записывается одним или двумя словами.
UTF-32 или UCS-4 в информатике — один из способов кодирования символов Юникода, использующий для кодирования любого символа ровно 32 бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байтов. Символ UTF-32 является прямым представлением его кодовой позиции.
Те́кстовый файл — компьютерный файл, содержащий текстовые данные. Текстовым файлам противопоставляются двоичные (бинарные) файлы, в которых содержатся данные, не рассчитанные на интерпретацию в качестве текстовых.
Основна́я кодиро́вка, как и альтернативная, разработана в 1986 году в ВЦ Академии Наук СССР; использовалась мало. Её поддерживало только оборудование и программное обеспечение, производившееся в СССР, а также некоторые принтеры Epson.
SMPP — короткие сообщения одноранговой Сети. Является открытым стандартом в телекоммуникационной отрасли, который разработан специально, чтобы обеспечить гибкий интерфейс для передачи коротких сообщений между внешними сущностями коротких сообщений (ESME), маршрутизаторами (RE) и центрами сообщений (SMSC).
Base64 — стандарт кодирования двоичных данных при помощи только 64 символов ASCII. Алфавит кодирования содержит латинские символы A-Z, a-z, цифры 0-9 и 2 дополнительных символа, зависящих от системы реализации. Каждые 3 исходных байта кодируются четырьмя символами.
Кандзи (яп., от кан «Хань» и дзи «знаки, иероглифы»; букв. «ханьские знаки») — китайские иероглифы, используемые в современной японской письменности, наряду с хираганой, катаканой, арабскими цифрами и ромадзи. Это японское прочтение китайского слова ханьцзы.
Набор символов — таблица, задающая кодировку конечного множества символов алфавита. Такая таблица сопоставляет каждому символу последовательность длиной в один или несколько символов другого алфавита.
X-SAMPA (X-SAMPA; /ˌɛksˈsæmpə/, /%Eks"s{mp@/)? — система записи знаков МФА с помощью набора символов ASCII.
ДКОИ — 8-битная кириллическая кодовая страница, использовавшаяся на компьютерах серии ЕС ЭВМ. Основой для ДКОИ послужила кодировка телеграфа.

JIS — набор требований, используемых в промышленности Японии. Процесс стандартизации координируется Комитетом по промышленным стандартам Японии. Комплекс стандартов JIS предложен Японской ассоциацией стандартов.

QR-код — тип матричных штриховых кодов, изначально разработанных для автомобильной промышленности Японии. Его создателем считается Масахиро Хара. Сам термин является зарегистрированным товарным знаком японской компании Denso. Штрихкод — считываемая машиной оптическая метка, содержащая информацию об объекте, к которому она привязана. QR-код использует четыре стандартизированных режима кодирования для эффективного хранения данных; могут также использоваться расширения.
Основная латиница или Управляющие символы C0 и основная латиница — первый блок стандарта Юникод и единственный блок, кодируемый одним байтом в системе UTF-8. Блок содержит все буквы и управляющие коды из кодировки ASCII.