XML — «расширяемый язык разметки». Рекомендован Консорциумом Всемирной паутины (W3C). Спецификация XML описывает XML-документы и частично описывает поведение XML-процессоров. XML разрабатывался как язык с простым формальным синтаксисом, удобный для создания и обработки документов как программами, так и человеком, с акцентом на использование в Интернете. Язык называется расширяемым, поскольку он не фиксирует разметку, используемую в документах: разработчик волен создать разметку в соответствии с потребностями к конкретной области, будучи ограниченным лишь синтаксическими правилами языка. Расширение XML — это конкретная грамматика, созданная на базе XML и представленная словарём тегов и их атрибутов, а также набором правил, определяющих, какие атрибуты и элементы могут входить в состав других элементов. Сочетание простого формального синтаксиса, удобства для человека, расширяемости, а также базирование на кодировках Юникод для представления содержания документов привело к широкому использованию как, собственно, XML, так и множества производных специализированных языков на базе XML в самых разнообразных программных средствах.
Наследование — концепция объектно-ориентированного программирования, согласно которой абстрактный тип данных может наследовать данные и функциональность некоторого существующего типа, способствуя повторному использованию компонентов программного обеспечения.
Шабло́ны — средство языка C++, предназначенное для кодирования обобщённых алгоритмов, без привязки к некоторым параметрам.

Префиксное дерево — структура данных, позволяющая хранить ассоциативный массив, ключами которого чаще всего являются строки. Представляет собой корневое дерево, каждое ребро которого помечено каким-то символом так, что для любого узла все рёбра, соединяющие этот узел с его сыновьями, помечены разными символами. Некоторые узлы префиксного дерева выделены и считается, что префиксное дерево содержит данную строку-ключ тогда и только тогда, когда эту строку можно прочитать на пути из корня до некоторого выделенного узла. В некоторых приложениях удобно считать все узлы дерева выделенными.

Филогенетическое дерево — дерево, отражающее эволюционные взаимосвязи между различными видами или другими сущностями, имеющими общего предка.

Дека́ртово де́рево, дуча, дерамида — это структура данных, сочетающая в себе двоичное дерево и двоичную кучу. Хранит пары (x, y), где для ключа x служит бинарным деревом поиска, а для приоритета y — двоичной кучей.

Красно-чёрное дерево — один из видов из самобалансирующихся двоичных деревьев поиска, гарантирующих логарифмический рост высоты дерева от числа узлов и позволяющее быстро выполнять основные операции дерева поиска: добавление, удаление и поиск узла. Сбалансированность достигается за счёт введения дополнительного атрибута узла дерева — «цвета». Этот атрибут может принимать одно из двух возможных значений — «чёрный» или «красный».
Компоновщик — структурный шаблон проектирования, объединяющий объекты в древовидную структуру для представления иерархии от частного к целому. Компоновщик позволяет клиентам обращаться к отдельным объектам и к группам объектов одинаково.

Дерево хешей — полное двоичное дерево, в листовые вершины которого помещены хеши от блоков данных, а внутренние вершины содержат хеши от сложения значений в дочерних вершинах. Корневой узел дерева содержит хеш от всего набора данных, то есть хеш-дерево является однонаправленной хеш-функцией. Применяется для эффективного хранения транзакций в блокчейне криптовалют. Оно позволяет получить «отпечаток» всех транзакций в блоке, а также эффективно верифицировать транзакции. Названо по имени Ральфа Меркла, предложившего в 1979 году соответствующую технику хеширования криптографических функций.
Дерево Фенвика — структура данных, позволяющая быстро изменять значения в массиве и находить некоторые функции от элементов массива. Впервые описано Питером Фенвиком в 1994 году. Дерево Фенвика напоминает дерево отрезков, однако проще в реализации.
POSIX Threads — стандарт POSIX-реализации потоков (нитей) выполнения. Стандарт POSIX.1c, Threads extensions определяет API для управления потоками, их синхронизации и планирования.
Система непересекающихся множеств — структура данных, которая позволяет администрировать множество элементов, разбитое на непересекающиеся подмножества. При этом каждому подмножеству назначается его представитель — элемент этого подмножества. Абстрактная структура данных определяется множеством трёх операций:  .
.
Расширяющееся или косое дерево является двоичным деревом поиска, в котором поддерживается свойство сбалансированности. Это дерево принадлежит классу «саморегулирующихся деревьев», которые поддерживают необходимый баланс ветвления дерева, чтобы обеспечить выполнение операций поиска, добавления и удаления за логарифмическое время от числа хранимых элементов. Это реализуется без использования каких-либо дополнительных полей в узлах дерева. Вместо этого «расширяющие операции», частью которых являются вращения, выполняются при каждом обращении к дереву.

Сортировка с помощью двоичного дерева — универсальный алгоритм сортировки, заключающийся в построении двоичного дерева поиска по ключам массива (списка), с последующей сборкой результирующего массива путём обхода узлов построенного дерева в необходимом порядке следования ключей. Данная сортировка является оптимальной при получении данных путём непосредственного чтения из потока.
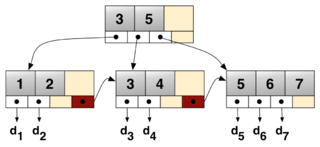
B⁺-дерево — структура данных на основе B-дерева, сбалансированное  -арное дерево поиска с переменным, но зачастую большим количеством потомков в узле. B⁺-дерево состоит из корня, внутренних узлов и листьев, корень может быть либо листом, либо узлом с двумя и более потомками.
-арное дерево поиска с переменным, но зачастую большим количеством потомков в узле. B⁺-дерево состоит из корня, внутренних узлов и листьев, корень может быть либо листом, либо узлом с двумя и более потомками.
Пустоты, космические пустоты, также войды — обширные области между галактическими нитями, в которых отсутствуют или почти отсутствуют галактики и скопления. Войды обычно имеют размеры порядка 10—100 Мпк. Средняя плотность материи в них менее десятой доли от типичной для наблюдаемой Вселенной.
Обход дерева — вид обхода графа, обусловливающий процесс посещения каждого узла структуры дерева данных ровно один раз. Такие обходы классифицируются по порядку, в котором узлы посещаются. Алгоритмы в статье относятся к двоичным деревьям, но могут быть обобщены и для других деревьев.
Сбалансированное итеративное сокращение и кластеризация с помощью иерархий — это алгоритм интеллектуального анализа данных без учителя, используемый для осуществления иерархической кластеризации на наборах данных большого размера. Преимуществом BIRCH является возможность метода динамически кластеризовать по мере поступления многомерных метрических точек данных в попытке получить кластеризацию лучшего качества для имеющегося набора ресурсов. В большинстве случаев алгоритм BIRCH требует одного прохода по базе данных.
TREE(3) — большое число, которое является верхней границей решения в теоретико-графовой теоремы Краскала. TREE(3) в невообразимое число раз больше числа Грэма. Число TREE(3) столь велико, что стрелочные нотации Кнута и Конвея не способны его записать.
Модель вложенного множества — это способ представления вложенных множеств в реляционных базах данных.