
DNS — компьютерная распределённая система для получения информации о доменах. Чаще всего используется для получения IP-адреса по имени хоста, получения информации о маршрутизации почты и/или обслуживающих узлах для протоколов в домене (SRV-запись).
Индекс — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск — например, сбалансированного дерева.

R-дерево — древовидная структура данных (дерево), предложенная в 1984 году Антонином Гуттманом. Она подобна B-дереву, но используется для организации доступа к пространственным данным, то есть для индексации многомерной информации, такой, например, как географические данные с двумерными координатами. Типичным запросом с использованием R-деревьев мог бы быть такой: «Найти все музеи в пределах 2 километров от моего текущего местоположения».
Информацио́нный по́иск — процесс поиска неструктурированной документальной информации, удовлетворяющей информационные потребности, и наука об этом поиске.

Префиксное дерево — структура данных, позволяющая хранить ассоциативный массив, ключами которого чаще всего являются строки. Представляет собой корневое дерево, каждое ребро которого помечено каким-то символом так, что для любого узла все рёбра, соединяющие этот узел с его сыновьями, помечены разными символами. Некоторые узлы префиксного дерева выделены и считается, что префиксное дерево содержит данную строку-ключ тогда и только тогда, когда эту строку можно прочитать на пути из корня до некоторого выделенного узла. В некоторых приложениях удобно считать все узлы дерева выделенными.

Двоичное дерево поиска — двоичное дерево, для которого выполняются следующие дополнительные условия :
- оба поддерева — левое и правое — являются двоичными деревьями поиска;
- у всех узлов левого поддерева произвольного узла X значения ключей данных меньше, нежели значение ключа данных самого узла X;
- у всех узлов правого поддерева произвольного узла X значения ключей данных больше либо равны, нежели значение ключа данных самого узла X.

АВЛ-дерево — сбалансированное по высоте двоичное дерево поиска: для каждой его вершины высота её двух поддеревьев различается не более чем на 1.

B-дерево — структура данных, дерево поиска. С точки зрения внешнего логического представления, сбалансированное, сильно ветвистое дерево во внешней памяти.
Дерево — одна из наиболее широко распространённых структур данных в информатике, эмулирующая древовидную структуру в виде набора связанных узлов. Является связным графом, не содержащим циклы. Большинство источников также добавляет условие на то, что рёбра графа не должны быть ориентированными. В дополнение к этим трём ограничениям, в некоторых источниках указывается, что рёбра графа не должны быть взвешенными.
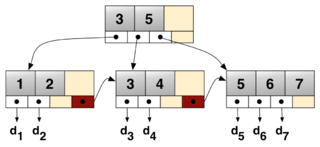
B⁺-дерево — структура данных на основе B-дерева, сбалансированное  -арное дерево поиска с переменным, но зачастую большим количеством потомков в узле. B⁺-дерево состоит из корня, внутренних узлов и листьев, корень может быть либо листом, либо узлом с двумя и более потомками.
-арное дерево поиска с переменным, но зачастую большим количеством потомков в узле. B⁺-дерево состоит из корня, внутренних узлов и листьев, корень может быть либо листом, либо узлом с двумя и более потомками.

DuckDuckGo — американская компания-разработчик программного обеспечения, предлагающая ряд продуктов, призванных помочь людям защитить свою приватность в Интернете.

k-d-дерево — это структура данных с разбиением пространства для упорядочивания точек в k-мерном пространстве. k-d-деревья используются для некоторых приложений, таких как поиск в многомерном пространстве ключей. k-d-деревья — особый вид двоичных деревьев поиска.

Кривая Гильберта — это непрерывная фрактальная заполняющая пространство кривая, впервые описанная немецким математиком Давидом Гильбертом в 1891 году, как вариант заполняющих пространство кривых Пеано, открытых итальянским математиком Джузеппе Пеано в 1890 году.
Криптография на решётках — подход к построению алгоритмов асимметричного шифрования с использованием задач теории решёток, то есть задач оптимизации на дискретных аддитивных подгруппах, заданных на множестве  .
.
R-дерево Гильберта, вариант R-дерева — это индексация многомерных объектов, таких как прямые, двумерные области, трёхмерные объекты или снабжённые параметрами объекты более высоких размерностей. Их можно понимать как расширение B+-деревьев на многомерные объекты.
В информатике Bx дерево — это эффективная для запросов и обновления структура индексирования для движущихся объектов, основанная на B+-деревьях.

В математическом анализе и информатике кривая Мортона, Z-последовательность, Z-порядок, кривая Лебега, порядок Мортона или код Мортона — это функция, которая отображает многомерные данные в одномерные, сохраняя локальность точек данных. Функция была введена в 1966 году Гаем Макдональдом Мортоном. Z-значение точки в многомерном пространстве легко вычисляется чередованием двоичных цифр его координатных значений. Когда данные запоминаются в этом порядке, могут быть использованы любые одномерные структуры, такие как двоичные деревья поиска, B-деревья, списки с пропусками или хеш-таблицы. Созданный таким образом порядок можно эквивалентно описать как порядок, который можно получить обходом в глубину дерева квадрантов.
Сбалансированное итеративное сокращение и кластеризация с помощью иерархий — это алгоритм интеллектуального анализа данных без учителя, используемый для осуществления иерархической кластеризации на наборах данных большого размера. Преимуществом BIRCH является возможность метода динамически кластеризовать по мере поступления многомерных метрических точек данных в попытке получить кластеризацию лучшего качества для имеющегося набора ресурсов. В большинстве случаев алгоритм BIRCH требует одного прохода по базе данных.
R*-деревья — это вариант R-деревьев, используемый для индексирования пространственной информации. R*-деревья имеют слегка более высокие затраты на создание, чем стандартные R-деревья, так как данные могут требовать переустановки, но получающееся дерево обычно имеет лучшую производительность запросов. Подобно стандартному R-дереву, оно может запоминать как точки, так и пространственные данные. Дерево предложили Норберт Бекман, Ганс-Петер Кригель, Ральф Шнайдер и Бернхард Сигер в 1990.
Datalog — язык декларативного логического программирования. Хотя синтаксически он выглядит как подмножество Prolog, Datalog обычно использует восходящую, а не нисходящую модель разрешения выражений. Это отличие приводит к значительному отличию поведения и свойств от Пролога. Он часто используется в качестве языка запросов для дедуктивных баз данных. В последние годы Datalog нашел новое применение в интеграции данных, извлечении информации, создании сетей, анализе программ, безопасности, облачных вычислениях и машинном обучении.
