Информа́ция — сведения независимо от формы их представления.
Семанти́ческая паути́на — общедоступная глобальная семантическая сеть, формируемая на базе Всемирной паутины путём стандартизации представления информации в виде, пригодном для машинной обработки.

Семанти́ческая сеть — информационная модель предметной области, имеет вид ориентированного графа. Вершины графа соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Объектами могут быть: понятия, события, свойства, процессы. Таким образом, семантическая сеть — это один из способов представления знаний.

Ю́рий Дерени́кович Апреся́н — советский и российский лингвист, доктор филологических наук, профессор (1991), академик РАН (1992), иностранный член Национальной академии наук Армении. Труды в области лексической семантики, синтаксиса, русской и английской лексикографии, истории лингвистики, машинного перевода и др. Один из разработчиков теории «Смысл ↔ Текст», глава Московской семантической школы. Составитель ряда словарей нового типа русского языка.
Веб-служба, веб-сервис — идентифицируемая уникальным веб-адресом (URL-адресом) программная система со стандартизированными интерфейсами.
MUMPS — язык программирования, созданный в 1966—1967 годах для использования в лечебной индустрии.

Resource Description Framework — это разработанная консорциумом Всемирной паутины модель для представления данных, в особенности — метаданных.

Ду́блинское ядро́ — словарь основных понятий английского языка, предназначенный для унификации метаданных для описания широчайшего диапазона ресурсов. С 2005 года словарь представлен и в формате RDF и является популярной основой для описания ресурсов в Семантической паутине.
Предметно-ориентированный язык — компьютерный язык, специализированный для конкретной области применения. Построение такого языка и/или его структура данных отражают специфику решаемых с его помощью задач. Является ключевым понятием языково-ориентированного программирования.
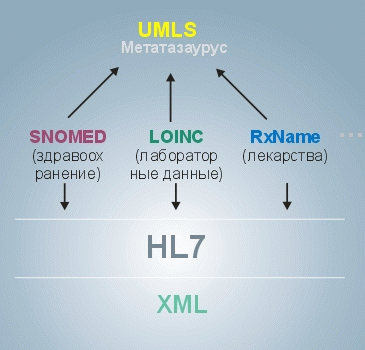
HL7 — стандарт обмена, управления и интеграции электронной медицинской информации.
Представление знаний — вопрос, возникающий в когнитологии и информатике, а также в исследовании вопросов, связанных с искусственным интеллектом. В когнитологии он связан с тем, как люди хранят и обрабатывают информацию. В информатике — с подбором представления конкретных и обобщённых знаний, сведений и фактов для накопления и обработки информации в ЭВМ. Главная задача в искусственном интеллекте (ИИ) — научиться хранить знания таким образом, чтобы программы могли осмысленно обрабатывать их и достигнуть тем подобия человеческого интеллекта.
Дескрипцио́нная логика — язык представления знаний, позволяющий описывать понятия предметной области в недвусмысленном, формализованном виде, организованный по типу языков математической логики. Дескрипционные логики сочетают, с одной стороны, богатые выразительные возможности, а с другой — хорошие вычислительные свойства, такие как разрешимость и относительно невысокая вычислительная сложность основных логических проблем, что делает возможным их применение на практике, обеспечивая компромисс между выразительностью и разрешимостью. Могут быть рассмотрены как разрешимые фрагменты логики предикатов, синтаксически же они близки к модальным логикам.

Protégé — свободный, открытый редактор онтологий и фреймворк для построения баз знаний.
В компьютерных науках програ́ммный аге́нт — это программа, которая вступает в отношение посредничества с пользователем или другой программой. Слово «агент» происходит от латинского agere (делать) и означает соглашение выполнять действия от имени кого-либо. Такие «действия от имени» подразумевают право решать, какие действия являются целесообразными. Идея состоит в том, что агенты не запускаются непосредственно для решения задачи, а активизируются самостоятельно.
SNOMED CT — это систематизированная машинно-обрабатываемая медицинская номенклатура. В состав SNOMED CT входит совокупность элементов: медицинские термины (terms), коды терминов (codes) и определители кодов (definitions). SNOMED CT применяется в медицинской документации и отчётах для повышения эффективности работы с клиническими данными. Систематизация клинической информации способствует общему повышению качества оказываемых услуг по лечению. SNOMED CT является базовой терминологией, используемой для ведения электронных медицинских записей. Термины номенклатуры SNOMED CT отражают понятия следующих категорий медицины и здравоохранения:
- медицинские расстройства,
- симптоматика заболеваний,
- диагнозы,
- медицинские процедуры и вмешательства,
- структуры тела,
- типы живых организмов,
- химические вещества,
- фармацевтические продукты,
- медицинские изделия,
- образцы для проведения анализов.

Тег, либо тэг — ассоциированное ключевое слово, относящееся к какой-либо информации . Такие метаданные помогают полнее описать эти куски информации и быстро находить их через поисковый запрос. Тэги используются без жёстких правил автором или конечным потребителем.
Концептуальное программирование - подход к программированию, описанный Э.Х. Тыугу в одноимённой книге. К. программирование предполагает оперирование понятиями, описанными в терминах предметной области, что позволяет использовать ЭВМ на этапе постановки задачи. Достаточно точное описание задачи позволяет ЭВМ автоматически составлять программы для её решения. Характерными особенностями концептуального программирования являются также использование языка предметной области и использование семантической памяти с целью накопления знаний о решаемых задачах.
Семанти́ческий механи́зм рассужде́ний, семанти́ческая машина формирования рассуждений или движо́к пра́вил — это часть программного обеспечения, способная вывести логические умозаключения из набора адекватно формализованных базовых знаний или аксиом. Понятие семантического механизма рассуждений обобщает понятие машины вывода, предоставляя более богатый набор механизмов для работы. Правила вывода обычно определяются с помощью языка онтологий и часто языков описательной логики. Многие семантические механизмы рассуждений используют логику первого порядка для выполнения рассуждений; вывод обычно происходит путём прямой и обратной цепочек рассуждений. Существуют также примеры вероятностных механизмов рассуждений, включая неаксиоматическую систему рассуждений Пей Ванга и вероятностные логические сети.
Извлечение знаний — создание знаний из структурированных и неструктурированных источников. Полученное знание должно иметь формат, позволяющий компьютерный ввод, и должно представлять знания так, чтобы облегчить логические выводы. Хотя по методике процесс подобен извлечению информации и процессу «Извлечения, Преобразования, Загрузки», главный критерий результата — создание структурированной информации или преобразование в реляционную схему. Это требует либо преобразования существующего формального знания, либо генерацией схемы, основанной на исходных данных.
XGMML - это приложение XML, основанное на GML, которое используется для описания графов. Технически, хоть и GML не связан ни с XML, ни с SGML, но XGMML - это приложение XML, которое разработано таким образом, что существует соотношение 1:1 к GML для тривиального преобразования между двумя форматами.