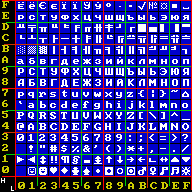
Windows-1253
Перейти к навигацииПерейти к поиску
Кодировка Windows-1253 используется в Microsoft Windows для представления современного греческого языка (но не древнегреческого). Расположение букв совпадает с ISO 8859-7, за исключением Ά; также отличается расположение многих небуквенных символов.
Эта кодировка включает одновременно букву мю (μ, 0xEC, в Юникоде 0x3BC) и значок микро (µ, 0xB5), хотя стандарт Юникода рекомендует при наличии возможности использовать только букву мю.[1]
Таблицы
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают 16-ричный код подходящего символа в Юникоде.
Кодировка Windows-1253
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | € 20AC | ‚ 201A | ƒ 192 | „ 201E | … 2026 | † 2020 | ‡ 2021 | ‰ 2030 | ‹ 2039 | |||||||
| 9. | ‘ 2018 | ’ 2019 | “ 201C | ” 201D | • 2022 | – 2013 | — 2014 | ™ 2122 | › 203A | |||||||
| A. | A0 | ΅ 385 | Ά 386 | £ A3 | ¤ A4 | ¥ A5 | ¦ A6 | § A7 | ¨ A8 | © A9 | « AB | ¬ AC | AD | ® AE | ― 2015 | |
| B. | ° B0 | ± B1 | ² B2 | ³ B3 | ΄ 384 | µ B5 | ¶ B6 | · B7 | Έ 388 | Ή 389 | Ί 38A | » BB | Ό 38C | ½ BD | Ύ 38E | Ώ 38F |
| C. | ΐ 390 | Α 391 | Β 392 | Γ 393 | Δ 394 | Ε 395 | Ζ 396 | Η 397 | Θ 398 | Ι 399 | Κ 39A | Λ 39B | Μ 39C | Ν 39D | Ξ 39E | Ο 39F |
| D. | Π 3A0 | Ρ 3A1 | Σ 3A3 | Τ 3A4 | Υ 3A5 | Φ 3A6 | Χ 3A7 | Ψ 3A8 | Ω 3A9 | Ϊ 3AA | Ϋ 3AB | ά 3AC | έ 3AD | ή 3AE | ί 3AF | |
| E. | ΰ 3B0 | α 3B1 | β 3B2 | γ 3B3 | δ 3B4 | ε 3B5 | ζ 3B6 | η 3B7 | θ 3B8 | ι 3B9 | κ 3BA | λ 3BB | μ 3BC | ν 3BD | ξ 3BE | ο 3BF |
| F. | π 3C0 | ρ 3C1 | ς 3C2 | σ 3C3 | τ 3C4 | υ 3C5 | φ 3C6 | χ 3C7 | ψ 3C8 | ω 3C9 | ϊ 3CA | ϋ 3CB | ό 3CC | ύ 3CD | ώ 3CE |
Ссылки
Примечания
- ↑ Unicode Technical Report #25. Дата обращения: 27 июня 2010. Архивировано 21 июля 2017 года.
| Исторические кодировки | |
|---|---|
| современное 8-битное представление | |
| Многобайтные | |