Алгоритм Ше́ннона — Фа́но — один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Клод Шеннон и Роберт Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже и является логическим продолжением алгоритма Шеннона. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся — кодом большей длины. Коды Шеннона — Фано — префиксные, то есть никакое кодовое слово не является префиксом любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Кодирование Шеннона — Фано (англ.Shannon–Fano coding) — алгоритм префиксного неоднородного кодирования. Относится к вероятностным методам сжатия (точнее, методам контекстного моделирования нулевого порядка). Подобно алгоритму Хаффмана, алгоритм Шеннона — Фано использует избыточность сообщения, заключённую в неоднородном распределении частот символов его (первичного) алфавита, то есть заменяет коды более частых символов короткими двоичными последовательностями, а коды более редких символов — более длинными двоичными последовательностями.
Алгоритм был независимо друг от друга разработан Шенноном (публикация «Математическая теория связи», 1948 год) и, позже, Фано (опубликовано как технический отчёт).
Основные этапы
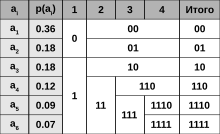
Пример построения кодовой схемы для шести символов a1 - a6 и вероятностей piСимволы первичного алфавита m1 выписывают по убыванию вероятностей.
Символы полученного алфавита делят на две части, суммарные вероятности символов которых максимально близки друг другу.
В префиксном коде для первой части алфавита присваивается двоичная цифра «0», второй части — «1».
Полученные части рекурсивно делятся, и их частям назначаются соответствующие двоичные цифры в префиксном коде.
Когда размер подалфавита становится равен нулю или единице, то дальнейшего удлинения префиксного кода для соответствующих ему символов первичного алфавита не происходит, таким образом, алгоритм присваивает различным символам префиксные коды разной длины. На шаге деления алфавита существует неоднозначность, так как разность суммарных вероятностей может быть одинакова для двух вариантов разделения (учитывая, что все символы первичного алфавита имеют вероятность больше нуля).
Алгоритм вычисления кодов Шеннона — Фано
Код Шеннона — Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем. Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона — Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий. Поэтому код Шеннона — Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона — Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона — Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
Кодовое дерево
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона — Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона — Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Сжа́тие да́нных — алгоритмическое преобразование данных, производимое с целью уменьшения занимаемого ими объёма. Применяется для более рационального использования устройств хранения и передачи данных. Синонимы — упаковка данных, компрессия, сжимающее кодирование, кодирование источника. Обратная процедура называется восстановлением данных.
Теория информации — раздел прикладной математики, радиотехники и информатики, относящийся к измерению количества информации, её свойств и устанавливающий предельные соотношения для систем передачи данных. Как и любая математическая теория, теория оперирует математическими моделями, а не реальными физическими объектами. Использует, главным образом, математический аппарат теории вероятностей и математической статистики.
Энтропийное кодирование — кодирование последовательности значений с возможностью однозначного восстановления с целью уменьшения объёма данных с помощью усреднения вероятностей появления элементов в закодированной последовательности.
Универсальный код для целых чисел в сжатии данных — префиксный код, который преобразует положительные целые числа в двоичные слова, с дополнительным свойством: при любом истинном распределение вероятностей на целых числах, пока распределение — монотонно, ожидаемые длины двоичных слов находятся в пределах постоянного фактора ожидаемых длин, которые оптимальный код назначил бы для этого распределения вероятностей.
Сжатие данных без потерь — класс алгоритмов сжатия данных, при использовании которых закодированные данные однозначно могут быть восстановлены с точностью до бита, пикселя, вокселя и т.д. При этом оригинальные данные полностью восстанавливаются из сжатого состояния. Этот тип сжатия принципиально отличается от сжатия данных с потерями. Для каждого из типов цифровой информации, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
Арифметическое кодирование — один из алгоритмов энтропийного сжатия.
Алгоритм Хаффмана — жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. В настоящее время используется во многих программах сжатия данных.
Код — взаимно однозначное отображение конечного упорядоченного множества символов, принадлежащих некоторому конечному алфавиту, на иное, не обязательно упорядоченное, как правило более обширное множество символов для кодирования передачи, хранения или преобразования информации.
В 1967 году Эндрю Витерби разработал и проанализировал алгоритм декодирования, основанный на принципе максимального правдоподобия. Алгоритм оптимизирован за счёт использования особенностей структуры конкретной решётки кода. Преимущество декодирования Витерби по сравнению с декодированием по методу полного перебора заключается в том, что сложность декодера Витерби не является функцией количества символов в последовательности кодовых слов.
Пре́фиксный код в теории кодирования — код со словом переменной длины, имеющий такое свойство : если в код входит слово a, то для любой непустой строки b слова ab в коде не существует. Хотя префиксный код состоит из слов разной длины, эти слова можно записывать без разделительного символа.
Теоремы Шеннона для источника общего вида описывают возможности кодирования источника общего вида с помощью разделимых кодов. Другими словами, описываются максимально достижимые возможности кодирования без потерь.
Цифрово́й звук — результат преобразования аналогового сигнала звукового диапазона в цифровой аудиоформат.
В теории информации теорема Шеннона об источнике шифрования устанавливает предел максимального сжатия данных и числовое значение энтропии Шеннона.
Хронология событий, связанных с теорией информации, сжатием данных, кодами коррекции ошибок и смежных дисциплин:
1872 — Людвиг Больцман представляет свою H-теорему, а вместе с этим формулу Σpi log pi для энтропии одной частицы газа.
1878 — Джозайя Уиллард Гиббс, определяет энтропию Гиббса: вероятности в формуле энтропии теперь взяты как вероятности состояния целой системы.
1924 — Гарри Найквист рассуждает о квантификации «Интеллекта» и скорости, на которой это может быть передано системой коммуникации.
1927 — Джон фон Нейман определяет фон Неймановскую энтропию, расширяя Гиббсовскую энтропию в квантовой механике.
1928 — Ральф Хартли представляет формулу Хартли как логарифм числа возможных сообщений, с информацией, передаваемой, когда приёмник может отличить одну последовательность символов от любой другой.
1929 — Лео Силард анализирует демона Максвелла, показывают, как двигатель Szilard может иногда преобразовывать информацию в извлечение полезной работы.
1940 — Алан Тьюринг представляет deciban как единицу измерения информации в немецкой машине Энигма с настройками, зашифрованными процессом Banburismus.
1944 — теория информации Клода Шеннона в основном завершена.
1947 — Ричард Хемминг изобретает Код Хемминга для обнаружения ошибок и их исправления, но не публикует их до 1950 года.
1948 — Клод Шеннон публикует Математическую теорию связи
1949 — Клод Шеннон публикует Передачу Информации в виде шумов, в которой описаны Теорема отсчётов и Теорема Шеннона — Хартли.
1949 — Рассекречена Теория связи в секретных системах Клода Шеннона.
1949 — Роберт Фано опубликовал отчет, в котором независимо от Клода Шеннона описан Алгоритм Шеннона — Фано.
1949 — Марсель Голей вводит коды Голея для исправления ошибок методом упреждения.
1950 — Ричард Хемминг публикует коды Хемминга для исправления ошибок методом упреждения.
1951 — Соломон Кульбак и Ричард Лейблер вводят понятие расстояния Кульбака-Лейблера.
1951 — Дэвид Хаффман изобретает кодирование Хаффмана, метод нахождения оптимальных префиксных кодов для сжатия данных без потерь.
1953 — опубликован Sardinas–Patterson algorithm.
1954 — Ирвинг Рид и Дэвид E. Мюллер вводит коды Рида-Мюллера.
1955 — Питер Элиас вводит свёрточные коды.
1957 — Юджин Прандж первый обсуждает циклический избыточный код.
1959 — Алексис Хоквингем, и самостоятельно в следующем году Радж Чандра Боуз и Двайджендра Камар Рей-Чоудхури, представляют коды Боуза-Чоудхури-Хоквингема (БЧХ-коды).
1960 — Ирвинг Рид и Густав Соломон вводят коды Рида-Соломона.
1962 — Роберт Галлагер предлагает код с малой плотностью проверок на чётность; их не использовали в течение 30 лет из-за технических ограничений.
1966 — опубликована статья Дэвида Форнея Concatenated error correction code.
1968 — Элвин Берлекэмп изобретает алгоритм Берлекэмпа — Мэсси; его применение к расшифровке БЧХ-кодов и кода Рида-Соломона, указанный Джеймсом Мэсси в последующем году.
1968 — Крис Уоллис и Дэвид М. Бутон издают первый из многих докладов о Сообщениях минимальной длины (СМД) — их статистический и индуктивный вывод.
1972 — опубликована статья о Justesen code.
1973 — Дэвид Слепиан и Джек Волф открывают и доказывают Код Слепиана-Вольфа, кодирующего пределы распределённого источника кодирования.
1976 — Готфрид Унгербоэк публикует первую статью о Треллис-модуляции.
1976 — Йорма Риссанен разрабатывает и позднее патентует арифметическое кодирование для IBM.
1982 — Готфрид Унгербоэк публикует более подробное описание Треллис-модуляции, что приводит к увеличению скорости аналогового модема старой обычной телефонной службы от 9.6 кбит/сек до 36 кбит/сек.
1989 — Фил Кац создаёт .zip формат, включая формат сжатия DEFLATE ; позже это становится наиболее широко используемым алгоритмом сжатия без потерь.
1993 — Клод Берроу, Алэйн Главиукс и Punya Thitimajshima вводят понятие Турбо-кодов.
1994 — Майкл Барроуз и Дэвид Уилер публикуют теорию преобразования Барроуза-Уилера, которая далее найдет своё применение в bzip2.
1995 — Benjamin Schumacher предложил термин Кубит.
1998 — предложен Fountain code.
2001 — описан алгоритм Statistical Lempel–Ziv.
2008 — Erdal Arıkan предложил Полярные коды.
В теории кодирования, неравенство Крафта — Макмиллана даёт необходимое и достаточное условие существования разделимых и префиксных кодов, обладающих заданным набором длин кодовых слов.
Сжатие (компрессия) аудиоданных представляет собой процесс уменьшения скорости цифрового потока за счет сокращения статистической и психоакустической избыточности цифрового звукового сигнала.
В области сжатия данных, код Шеннона, названный в честь его создателя, Клода Шеннона, — это алгоритм сжатия данных без потерь с помощью построения префиксных кодов на основе набора символов и их вероятностей. Он является субоптимальным в том смысле, что не позволяет достичь минимально возможных кодовых длин как в кодировании Хаффмана, и никогда не будет лучше, но иногда равным с кодом Шеннона-Фано.
Адаптивное кодирование Хаффмана — адаптивный метод, основанный на кодировании Хаффмана. Он позволяет строить кодовую схему в поточном режиме, не имея никаких начальных знаний из исходного распределения, что позволяет за один проход сжать данные. Преимуществом этого способа является возможность кодировать на лету.
Интервальное кодирование — энтропийный метод кодирования, предложенный Г. Найджелом и Н. Мартином в 1979 году. Это разновидность арифметического кодирования.
Кодирование по Танстеллу — форма энтропийного кодирования, используемая для сжатия данных без потерь.
Эта страница основана на статье Википедии. Текст доступен на условиях лицензии CC BY-SA 4.0; могут применяться дополнительные условия. Изображения, видео и звуки доступны по их собственным лицензиям.