
Быстрая сортировка, сортировка Хоара, часто называемая qsort — алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром во время его работы в МГУ в 1960 году.
Алгоритм Кнута — Морриса — Пратта (КМП-алгоритм) — эффективный алгоритм, осуществляющий поиск подстроки в строке, используя то, что при возникновении несоответствия само слово содержит достаточно информации, чтобы определить, где может начаться следующее совпадение, минуя лишние проверки. Время работы алгоритма линейно зависит от объёма входных данных, то есть разработать асимптотически более эффективный алгоритм невозможно.
Сортировка подсчётом — алгоритм сортировки, в котором используется диапазон чисел сортируемого массива (списка) для подсчёта совпадающих элементов. Применение сортировки подсчётом целесообразно лишь тогда, когда сортируемые числа имеют диапазон возможных значений, который достаточно мал по сравнению с сортируемым множеством, например, миллион натуральных чисел меньших 1000.
Вычисли́тельная сло́жность — понятие в информатике и теории алгоритмов, обозначающее функцию зависимости объёма работы, которая выполняется некоторым алгоритмом, от размера входных данных. Раздел, изучающий вычислительную сложность, называется теорией сложности вычислений. Объём работы обычно измеряется абстрактными понятиями времени и пространства, называемыми вычислительными ресурсами. Время определяется количеством элементарных шагов, необходимых для решения задачи, тогда как пространство определяется объёмом памяти или места на носителе данных. Таким образом, в этой области предпринимается попытка ответить на центральный вопрос разработки алгоритмов: «как изменится время исполнения и объём занятой памяти в зависимости от размера входа?». Здесь под размером входа понимается длина описания данных задачи в битах, а под размером выхода — длина описания решения задачи.
Ме́тод максима́льного правдоподо́бия или метод наибольшего правдоподобия в математической статистике — это метод оценивания неизвестного параметра путём максимизации функции правдоподобия. Основан на предположении о том, что вся информация о статистической выборке содержится в функции правдоподобия. Метод максимального правдоподобия был проанализирован, рекомендован и значительно популяризирован Р. Фишером между 1912 и 1922 годами.
Нелинейная динамика — междисциплинарная наука, в которой изучаются свойства нелинейных динамических систем. Нелинейная динамика использует для описания систем нелинейные модели, обычно описываемые дифференциальными уравнениями и дискретными отображениями. Нелинейная динамика включает в себя теорию устойчивости, теорию динамического хаоса, эргодическую теорию, теорию интегрируемых систем.
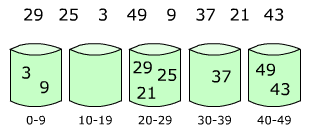
Блочная сортировка — алгоритм сортировки, в котором сортируемые элементы распределяются между конечным числом отдельных блоков так, чтобы все элементы в каждом следующем по порядку блоке были всегда больше, чем в предыдущем. Каждый блок затем сортируется отдельно, либо рекурсивно тем же методом, либо другим. Затем элементы помещаются обратно в массив. Этот тип сортировки может обладать линейным временем исполнения.

Алгоритм Флойда — Уоршелла — динамический алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного ориентированного графа. Разработан в 1962 году Робертом Флойдом и Стивеном Уоршеллом. При этом алгоритм впервые разработал и опубликовал Бернард Рой в 1959 году.

Ку́ча в программировании — специализированная структура данных типа дерева, которая удовлетворяет свойству кучи: если  является узлом-потомком узла
является узлом-потомком узла  , то
, то  , где
, где  — ключ (идентификатор) узла. Из этого следует, что элемент с наибольшим значением ключа всегда является корневым узлом кучи, поэтому иногда такие кучи называют max-кучами. Не существует никаких ограничений относительно того, сколько узлов-потомков имеет каждый узел кучи, хотя на практике их число обычно не более двух. Куча является максимально эффективной реализацией абстрактного типа данных, который называется очередью с приоритетом. Кучи имеют решающее значение в некоторых эффективных алгоритмах на графах, таких, как алгоритм Дейкстры на d-кучах и сортировка методом пирамиды.
— ключ (идентификатор) узла. Из этого следует, что элемент с наибольшим значением ключа всегда является корневым узлом кучи, поэтому иногда такие кучи называют max-кучами. Не существует никаких ограничений относительно того, сколько узлов-потомков имеет каждый узел кучи, хотя на практике их число обычно не более двух. Куча является максимально эффективной реализацией абстрактного типа данных, который называется очередью с приоритетом. Кучи имеют решающее значение в некоторых эффективных алгоритмах на графах, таких, как алгоритм Дейкстры на d-кучах и сортировка методом пирамиды.

KHAZAD — в криптографии симметричный блочный шифр, разработанный двумя криптографами: бельгийцем Винсентом Рэйменом и бразильцем Пауло Баррето. В алгоритме используются блоки данных размером 64 бита и ключи размером 128 бит. KHAZAD был представлен на европейском конкурсе криптографических примитивов NESSIE в 2000 году, где в модифицированной (tweaked) форме стал одним из алгоритмов-финалистов.
SQUARE — в криптографии симметричный блочный криптоалгоритм, разработанный в 1997 году Винсентом Рэйменом, Йоаном Дайменом и Ларсом Кнудсеном.
Тео́рия алгори́тмов — раздел математики, изучающий общие свойства и закономерности алгоритмов и разнообразные формальные модели их представления. К задачам теории алгоритмов относятся формальное доказательство алгоритмической неразрешимости задач, асимптотический анализ сложности алгоритмов, классификация алгоритмов в соответствии с классами сложности, разработка критериев сравнительной оценки качества алгоритмов и т. п. Вместе с математической логикой теория алгоритмов образует теоретическую основу вычислительных наук, теории передачи информации, информатики, телекоммуникационных систем и других областей науки и техники.
Алгори́тм Левита — алгоритм на графах, находит кратчайшее расстояние от одной из вершин графа до всех остальных. Алгоритм также работает для графов с рёбрами отрицательного веса. Алгоритм широко применяется в программировании и технологиях.
Основная теорема о рекуррентных соотношениях используется в анализе алгоритмов для получения асимптотической оценки рекурсивных соотношений, часто возникающих при анализе алгоритмов типа «разделяй и властвуй», например, при оценке времени их выполнения. Теорема была введена и доказана Джоном Бентли, Доротеном Хакеном и Джеймсом Хакеном в 1980 году. Теорема была популяризована в книге Алгоритмы: построение и анализ, в которой она была приведена.
Онлайновое машинное обучение — это метод машинного обучения, в котором данные становятся доступными в последовательном порядке и используются для обновления лучшего предсказания для последующих данных, выполняемого на каждом шаге обучения. Метод противоположен пакетной технике обучения, в которой лучшее предсказание генерируется за один раз, исходя из полного тренировочного набора данных. Онлайновое обучение является общей техникой, используемой в областях машинного обучения, когда невозможна тренировка по всему набору данных, например, когда возникает необходимость в алгоритмах, работающих с внешней памятью. Метод используется также в ситуациях, когда алгоритму приходится динамически приспосабливать новые схемы в данных или когда сами данные образуются как функция от времени, например, при предсказании цен на фондовом рынке. Алгоритмы онлайнового обучения могут быть склонны к катастрофическим помехам, проблеме, которая может быть решена с помощью подхода пошагового обучения.
Анализ независимых компонент, называемый также Метод независимых компонент (МНК) — это вычислительный метод в обработке сигналов для разделения многомерного сигнала на аддитивные подкомпоненты. Этот метод применяется при предположении, что подкомпоненты являются негауссовыми сигналами и что они статистически независимы друг от друга. АНК является специальным случаем слепого разделения сигнала. Типичным примером приложения является задача вечеринки с коктейлем — когда люди на шумной вечеринке выделяют голос собеседника, несмотря на громкую музыку и шум людей в помещении: мозг способен фильтровать звуки и сосредотачиваться на одном источнике в реальном времени.
Выпуклое программирование — это подобласть математической оптимизации, которая изучает задачу минимизации выпуклых функций на выпуклых множествах. В то время как многие классы задач выпуклого программирования допускают алгоритмы полиномиального времени, математическая оптимизация в общем случае NP-трудна.
Метод потенциалов — один из методов амортизационного анализа, позволяющий «сгладить» влияние дорогих, но редких операций на суммарную вычислительную сложность алгоритма.
Быстрое преобразование Хафа — модификация преобразования Хафа, позволяющая параметрически идентифицировать прямые с меньшей вычислительной сложностью за счет использования факта самопересечения рассматриваемых дискретных прямых.
Экономи́ческий ана́лиз языковы́х пра́в — совокупность методов изучения и исследования языковых прав, рассматриваемых в первую очередь в качестве экономических явлений, действий и результатов. Данный тип анализа может применяться в экономике языка для определения возможных закономерностей и тенденций развития языковых прав. Благодаря этому, результаты экономического анализа языковых прав могут быть использованы для улучшения показателей эффективности реализации языковой политики на макро- и микроуровне.






