Метаболомика — это «систематическое изучение уникальных химических „отпечатков пальцев“ специфичных для процессов, протекающих в живых клетках» — конкретнее, изучение их низкомолекулярных метаболических профилей. Метаболом представляет собой совокупность всех метаболитов, являющихся конечным продуктом обмена веществ в клетке, ткани, органе или организме. В то время как данные об экспрессии мРНК генов и данные протеомного анализа не раскрывают полностью всего того, что может происходить в клетке, метаболические профили могут дать мгновенный снимок физиологических процессов в клетке. Одна из задач системной биологии и функциональной геномики — интегрирование данных протеомики, транскриптомики и метаболической информации для получения более целостного представления о живых организмах.

Ми́кроРНК — малые некодирующие молекулы РНК длиной 18—25 нуклеотидов, обнаруженные у растений, животных и некоторых вирусов, принимающие участие в транскрипционной и посттранскрипционной регуляции экспрессии генов путём РНК-интерференции. Помимо внутриклеточной обнаружена внеклеточная (циркулирующая) микроРНК.
DrugBank — база данных лекарственных веществ с химической, фармакологической и фармацевтической информацией, созданной при University of Alberta. База версии 5.1.5, выпущенной 3 января 2020 года, содержит информацию о 13 562 лекарственных веществах, включая:
- 2630 соединений, одобренных FDA;
- 1372 биологических препаратов;
- 131 нутрицевтиков;
- 6369 экспериментальных соединений.
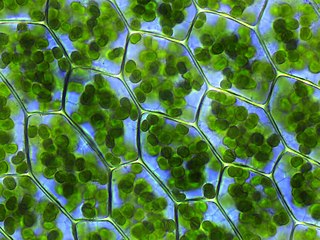
Зелёные растения — подцарство эукариот из царства растений.

G-квадру́плексы (англ. G-quadruplex, а также G-tetrads или G4) — последовательности нуклеиновых кислот, обогащенные гуанином и способные образовывать структуры из четырёх цепей. Цепи нуклеиновых кислот из гуанозиновых олиго- и полинуклеотидов способны связываться друг с другом при наличии моновалентного катиона небольшого размера, чаще всего — калия. С помощью дифракционного анализа было показано, что такие поли(G)-нити представляют собой новый тип укладки ДНК, четырёхцепочечную спираль, где четыре гуаниновых основания из разных цепей образуют плоскую структуру, удерживаемую парными взаимодействиями G-G (рис. 1). Такие структуры отличаются высокой стабильностью в растворе и называются гуаниновыми (G)-квартетами, или G-тетрадами. Каждый G-квартет скреплен в сумме восемью водородными связями, образованными взаимодействием Уотсон-Криковской стороны одного гуанинового основания с Хугстиновской стороной другого. G-квадруплексы могут быть также образованы короткими олигонуклеотидами с соответствующей последовательностью, которую можно схематически записать как GmXnGmXoGmXpGm, где m — количество гуанинов в G-блоке. Эти гуанины обычно непосредственно задействованы в образовании G-тетрад. Xn, Xo и Xp могут быть комбинацией любых остатков, включая G; такие участки формируют петли между G-тетрадами.

UniProt — открытая база данных последовательностей белков. Консорциум UniProt действует с 2003 года. Единая база данных UniProt была создана путём объединения нескольких баз. UniProt состоит из четырёх крупных баз данных и охватывает различные аспекты анализа белковых последовательностей. Многие из последовательностей стали известны в результате реализации проектов секвенирования геномов последних лет. Кроме того, база данных UniProt содержит большое количество информации о биологических функциях белков, полученной из научной литературы.
KEGG — веб-ресурс, предоставляющий доступ к ряду биологических баз данных и инструментам для анализа биологических и медицинских данных, созданный в 1995 году в рамках проекта «Геном человека». С момента создания интегрированная база данных KEGG значительно расширилась и на данный момент (2017) насчитывает шестнадцать баз данных, для удобства поиска разделенных на четыре категории: системная информация, геномная информация, химическая информация и информация, связанная непосредственно со здоровьем человека. Также KEGG предоставляет ряд инструментов для удобной работы с базами данных и анализа хранящейся в них информации.
SMART — база данных, используемая при идентификации и анализе белковых доменов в белковых последовательностях. SMART использует для обнаружения доменов в белковых последовательностях алгоритм, основанный на применении скрытых марковских моделей ко множественным выравниваниям. По данным на январь 2012 года SMART содержала модели 1009 доменов. Данные SMART использовались при создании Базы Консервативных Доменов и также представляются как часть базы данных InterPro.

Связанный со сперматогенезом белок 7 — белок, что у человека кодируется геном SPATA7.
В этом списке собрано программное обеспечение и интернет ресурсы, предназначенные для визуализации филогенетических деревьев.

ДНК (цитозин-5)-метилтрансфераза 3-подобный фермент англ. DNA (cytosine-5)-methyltransferase 3-like, DNMT3L — фермент, кодируемый у человека геном DNMT3L.

Гистондеацетилаза 11 — фермент массой 39 кДа, кодируеммый у человека геном HDAC11, расположен на хромосоме 3 у человека и на хромосоме 6 у мышей.
Ма́лые РНК бакте́рий — небольшие некодирующие РНК длиной 50—250 нуклеотидов, содержащиеся в клетках бактерий. Как правило, малые РНК бактерий имеют сложную структуру и содержат несколько шпилек. Многочисленные малые РНК были определены в клетках кишечной палочки, модельном патогене Salmonella, азотфиксирующей альфа-протеобактерии Sinorhizobium meliloti, морских цианобактериях, возбудителе туляремии Francisella tularensis, патогене растений Xanthomonas oryzae pathovar oryzae и других бактериях. Для поиска малых РНК в геноме бактерий использовали компьютерный анализ и различные лабораторные методы.
Предсказа́ние фу́нкции белка́ — определение биологической роли белка и значения в контексте клетки. Предсказание функций проводится для плохо изученных белков или для гипотетических белков, предсказанных на основе данных геномных последовательностей. Источником информации для предсказания могут служить гомология нуклеотидных последовательностей, профили экспрессии генов, доменная структура белков, интеллектуальный анализ текстов публикаций, филогенетические и фенотипические профили, белок-белковые взаимодействия.

REBASE — база данных, содержащая информацию об эндонуклеазах рестрикции и ДНК-метилтрансферазах. REBASE содержит обширный набор ссылок, сайтов узнавания и расщепления, последовательностей и структур, а также информацию о коммерческой доступности каждого фермента. REBASE является одной из старейших биологических баз данных, она ведёт свои корни из коллекции рестриктаз собранной Ричардом Робертсом ещё до 1980 года. C того времени в журнале Nucleic Acids Research регулярно публикуются описания этой баз данных.

SLAMF7 (CD319) — мембранный белок, продукт гена человека SLAMF7. Белок входит в семейство сигнальных лимфоцитарных молекул активации.

IFITM3 — мембранный белок из семейства интерферон-индуцируемых мембранных белков, продукт гена человека IFITM3.

Рибонуклеаза T — фермент рибонуклеаза, действующая при созревании транспортных и рибосомных РНК у бактерий, а также в процессах репарации ДНК.

SUMO это аббревиатура названия для семейства малых убиквитин-подобных белков-модификаторов, которые ковалентно присоединяются к остатку лизина на белках-мишенях посредством серии ферментативных реакций, что ведет к изменению функции этих белков. Структурно белки SUMO напоминают убиквитин и обладают консервативной структурой, состоящей из пятицепочечного β-листа, который обертывается вокруг центральной α-спирали
CRISPR-Cas13 это РНК-нуклеаза которую можно использовать для целенаправленной деградации РНК. Ферменты Cas13 имеют два эндоРНКазных домена HEPN. Для нацеливания этот фермент использует направляющую РНК (gRNA). После активации путем спаривания между последовательностью CRISPR РНК (crРНК) и комплементарной одноцепочечной РНК (ssРНК)-мишенью эффектор Cas13 вызывает расщепление РНК-мишени, При этом для активации рибонуклеазы Cas13 требуется почти идеальная комплементарность между целевой РНК и Cas13-ассоциированной направляющей РНК. Поскольку программируемая последовательность направляющей РНК Cas13 примерно в три раза больше, чем исходная последовательность кшРНК, опосредованный CRISPR-Cas13 сайленсинг транскрипции дает исследователям большую избирательность цели. Еще одним преимуществом является то, что Cas13 не требует последовательности PAM, что теоретически позволяет ему нацеливаться практически на любую область РНК.

