
Стати́стика — отрасль знаний, наука, в которой излагаются общие вопросы сбора, измерения, мониторинга, анализа массовых статистических данных и их сравнение; изучение количественной стороны массовых общественных явлений в числовой форме.
Сре́днее арифмети́ческое — разновидность среднего значения. Определяется как число, равное сумме всех чисел множества, делённой на их количество. Является одной из наиболее распространённых мер центральной тенденции.
Медиа́на, или серединное значение набора чисел — число, которое находится в середине этого набора, если его упорядочить по возрастанию, то есть такое число, что половина из элементов набора не меньше него, а другая половина не больше. Другое равносильное определение: медиана набора чисел — это число, сумма расстояний от которого до всех чисел из набора минимальна. Это определение естественным образом обобщается на многомерные наборы данных и называется 1-медианой.
Вы́борка или вы́борочная совоку́пность — часть генеральной совокупности элементов, которая охватывается экспериментом.
Среднеквадрати́ческое отклонение — наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания. Обычно означает квадратный корень из дисперсии случайной величины, но иногда может означать тот или иной вариант оценки этого значения.

Распределе́ние Стью́дента в теории вероятностей — это однопараметрическое семейство абсолютно непрерывных распределений. Уильям Сили Госсет первым опубликовал работы, посвящённые этому распределению, под псевдонимом «Стьюдент».
Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности — надёжность как устойчивость и надёжность как внутреннюю согласованность.

Кластерный анализ — многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя.
Оши́бка пе́рвого ро́да — ситуация, когда отвергнута верная нулевая гипотеза.
Задача классифика́ции — задача, в которой множество объектов (ситуаций) необходимо разделить некоторым образом на классы, при этом задано конечное множество объектов, для которых известно, к каким классам они относятся (выборка), но классовая принадлежность остальных объектов неизвестна. Для решения задачи требуется построить алгоритм, способный классифицировать произвольный объект из исходного множества, то есть указать, к какому классу он относится.
Критерий согласия Пирсона или критерий согласия  (хи-квадрат) — непараметрический метод, который позволяет оценить значимость различий между фактическим количеством исходов или качественных характеристик выборки, попадающих в каждую категорию, и теоретическим количеством, которое можно ожидать в изучаемых группах при справедливости нулевой гипотезы. Выражаясь проще, метод позволяет оценить статистическую значимость различий двух или нескольких относительных показателей.
(хи-квадрат) — непараметрический метод, который позволяет оценить значимость различий между фактическим количеством исходов или качественных характеристик выборки, попадающих в каждую категорию, и теоретическим количеством, которое можно ожидать в изучаемых группах при справедливости нулевой гипотезы. Выражаясь проще, метод позволяет оценить статистическую значимость различий двух или нескольких относительных показателей.
U-критерий Манна — Уитни — статистический критерий, используемый для оценки различий между двумя независимыми выборками по уровню какого-либо признака, измеренного количественно. Позволяет выявлять различия в значении параметра между малыми выборками.
Кванти́ль в математической статистике — значение, которое заданная случайная величина не превышает с фиксированной вероятностью. Если вероятность задана в процентах, то квантиль называется процентилем или перцентилем.
Робастность — свойство статистического метода, характеризующее независимость влияния на результат исследования различного рода выбросов, устойчивости к помехам. Робастный метод — метод, направленный на выявление выбросов, снижение их влияния или исключение их из выборки.
Критерий согласия Колмогорова или Критерий согласия Колмогорова-Смирнова — статистический критерий, использующийся для определения того, подчиняются ли два эмпирических распределения одному закону, либо того, подчиняется ли полученное распределение предполагаемой модели. Носит имена математиков Андрея Николаевича Колмогорова и Николая Васильевича Смирнова.
Семплирование — в математической статистике обобщенное название методов управления начальной выборкой при известной цели моделирования, которые позволяют выполнить структурно-параметрическую идентификацию наилучшей статистической модели стационарного эргодического случайного процесса.
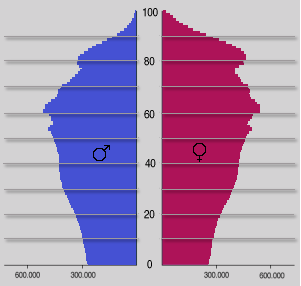
Частотное распределение — метод статистического описания данных. Математически распределение частот является функцией, которая в первую очередь определяет для каждого показателя идеальное значение, так как эта величина обычно уже измерена. Такое распределение можно представить в виде таблицы или графика, моделируя функциональные уравнения. В описательной статистике частота распределения имеет ряд математических функций, которые используются для выравнивания и анализа частотного распределения.
Непараметрическая статистика — раздел статистики, который не основан исключительно на параметризованных семействах вероятностных распределений. Непараметрическая статистика включает в себя описательную статистику и статистический вывод.
Линейный дискриминантный анализ, нормальный дискриминантный анализ или анализ дискриминантных функций является обобщением линейного дискриминанта Фишера, метода, используемого в статистике, распознавании образов и машинном обучении для поиска линейной комбинации признаков, которая описывает или разделяет два или более классов или событий. Получившаяся комбинация может быть использована как линейный классификатор, или, более часто, для снижения размерности перед классификацией.
Критерий Бартлетта — статистический критерий, позволяющий проверять равенство дисперсий нескольких выборок. Нулевая гипотеза предполагает, что рассматриваемые выборки получены из генеральных совокупностей, обладающих одинаковыми дисперсиями.

![{\displaystyle [(x_{25}-1{,}5\cdot (x_{75}-x_{25})),\,\,(x_{75}+1{,}5\cdot (x_{75}-x_{25}))]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/519d4c0c0c2aa2d85348ab8dc46aafb636f781d5)