Извлечение знаний
Извлечение знаний (англ. knowledge extraction) — создание знаний из структурированных (реляционных баз данных, XML) и неструктурированных источников (тексты, документы, изображения). Полученное знание должно иметь формат, позволяющий компьютерный ввод, и должно представлять знания так, чтобы облегчить логические выводы. Хотя по методике процесс подобен извлечению информации (обработке естественного языка, англ. Natural language processing, NLP) и процессу «Извлечения, Преобразования, Загрузки» (англ. Extract, Transform, Load, ETL, для хранилищ данных), главный критерий результата — создание структурированной информации или преобразование в реляционную схему. Это требует либо преобразования существующего формального знания (повторного использования идентификаторов или онтологий), либо генерацией схемы, основанной на исходных данных.
Группа RDB2RDF W3C[1] занимается стандартизацией языка для извлечения среды описания ресурса (англ. resource description frameworks, RDF) из реляционной базы данных. Другой популярный пример извлечения знаний — преобразование Википедии в структурированные данные и отображение в существующее знание (см. DBpedia и Freebase).
Обзор
После стандартизации языков представления знания, таких как «среда описания ресурса» (англ. Resource Description Framework, RDF) и «язык описания онтологий» (англ. Web Ontology Language, OWL), много исследований проводилось в этой области, особенно относительно преобразования реляционной базы данных в RDF, способности распознавания[англ.], обнаружения знаний и обучения онтологий. Основной процесс использует традиционные методы извлечения информации и методы «извлечения, преобразования и загрузка» (англ. extract, transform, load, ETL), которые преобразуют данные из исходных форматов в структурированные форматы.
Следующие критерии могут быть использованы для попыток категоризации в этой теме (некоторые из них обеспечивают извлечение знаний из реляционных баз данных)[2]:
| Источник | Какие данные могут быть обработаны: Текст, Реляционная база данных, XML, CSV |
|---|---|
| Представление | Как извлечённые данные могут быть представлены для использования (файл онтологии (объектной модели), семантическая база данных)? Как можно запрашивать информацию из полученного представления? |
| Синхронизация | Выполняется ли извлечение знания один раз для получения дампа или результат синхронизируется с источником? Извлечение статическое или динамическое? Записываются ли изменения в результате обратно в источник (двунаправленность)? |
| Повторное использование словаря | Позволяет ли средство извлечения повторное использование существующих словарей при извлечении. Например, столбец таблицы 'firstName' может быть отражён в столбец foaf: firstName. Некоторые автоматические подходы не способны к отображению словаря. |
| Автоматизация | Степень участия/автоматизации извлечения: Ручной режим, есть GUI, полуавтоматический, автоматический. |
| Необходимость объектной модели предметной области | Требуется ли наперёд заданная объектная модель для отображения в неё. Таким образом, либо отображение создаётся, либо схема получается из источника путём (обучения онтологий[англ.]). |
Примеры
Связывание именованных сущностей
- DBpedia Spotlight, OpenCalais[англ.], Dandelion dataTXT, Zemanta API, Extractiv и PoolParty Extractor анализируют произвольный текст с помощью распознавания именованных сущностей[англ.], а затем разрешения неоднозначностей путём разрешения имён[англ.] и связывания найденных сущностей в депозитарий знаний DBpedia[3] (Dandelion dataTXT demo, или DBpedia Spotlight web demo, или PoolParty Extractor Demo).
Президент Обама призвал в среду Конгресс включить расширение налоговых каникул для студентов в пакет экономического стимулирования, утверждая, что эта политика даст более крепкую поддержку.
- Так как Президент Обама связан в DBpedia с ресурсом LinkedData, дальнейшая информация может быть извлечена автоматически и Семантический механизм рассуждений может, например, сделать вывод, что упомянутая сущность является неким типом личности (используя FOAF) и президентом США (используя YAGO[англ.]). Контрпримеры: Методы, которые только распознают сущности и не связывают со статьями в Википедии или другими объектами, не обеспечивают извлечение дальнейших структурированных данных и формального знания.
Преобразование реляционной базы данных в RDF
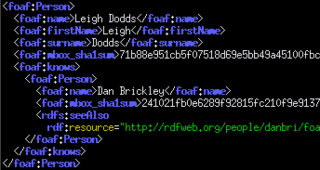
- Triplify, D2R Server, Ultrawrap и Virtuoso[англ.] прредставления RDF являются средствами, которые преобразуют реляционную базу данных в RDF. В течение это процесса эти средства позволяют повторное использование словарей и онтологии в процессе преобразования. Когда преобразуется типичная реляционная таблица с названием users, один столбец (например, name) или группа столбцов (например, first_name и last_name) должны обеспечивать унифицированный идентификатор создаваемой сущности. Обычно используется главный ключ. Любой другой столбец может быть извлечён как связанный с этой сущностью[4]. Затем используются (и повторно используются) свойства с формально определённой семантикой для интерпретации информации. Например, столбец таблицы user, названный marriedTo (женат на/замужем за) может быть определён как семантическое отношение, а столбец homepage (домашняя страница) может быть преобразован в свойство из словаря FOAF с названием foaf: homepage, тем самым квалифицируя его как обратную функциональность. Тогда каждый вход таблицы user может быть сделан экземпляром класса foaf:Person (онтология Население). Кроме того, предметная область (в виде онтологии) может быть создана из status_id путём вручную созданных правил (если status_id равен 2, строка таблицы принадлежит классу Учитель) или (полу-)автоматическими методами (Обучение онтологий[англ.]). Ниже приведён пример преобразования:
| Name | marriedTo | homepage | status_id |
|---|---|---|---|
| Peter | Mary | http://example.org/Peters_page (недоступная ссылка) | 1 |
| Claus | Eva | http://example.org/Claus_page (недоступная ссылка) | 2 |
:Peter :marriedTo :Mary .
:marriedTo OWL:SymmetricProperty .
:Peter foaf:homepage <http://example.org/Peters_page> .
:Peter foaf:Person (Физическое лицо).
:Peter :Student (Студент).
:Claus :Teacher (Учитель).
Извлечение из структурированных источников в RDF
Отображение 1:1 из таблиц/представлений реляционной базы данных в RDF сущности/атрибуты/значения
При построении представления реляционной базы данных (РБД, англ. relational database) стартовой точкой часто служит диаграмма сущность-связь (англ. entity-relationship diagram, ERD). Обычно каждая сущность представлена как таблица базы данных, каждое свойство сущности становится столбцом в этой таблице, а связь между сущностями показывается внешними ключами. Каждая таблица обычно определяет конкретный класс сущностей, а каждый столбец определяет одно из свойств этой сущности. Каждая строка в таблице описывает экземпляр сущности, однозначно определённый главным ключом. Строки таблицы вместе описывают набор сущностей. В эквивалентном RDF представлении того же набора сущности:
- Каждый столбец в таблице является свойством (то есть предикатом)
- Каждое значение в столбце является свойством атрибута (то есть является объектом)
- Каждый ключ строки представляет ID сущности (то есть субъектом)
- Каждая строка представляет экземпляр сущности
- Каждая строка (экземпляр сущности) представляется в RDF коллекцией кортежей с общим субъектом (ID сущности).
Таким образом, чтобы выразить эквивалентное представление, основанное на семантике RDF, базовый алгоритм будет выглядеть следующим образом:
- создаём схему RDF (RDFS) класса для каждой таблицы
- преобразуем все главные ключи и внешние ключи в IRI идентификаторы
- назначаем IRI предикат каждому столбцу
- назначаем rdf: type предикат каждой строке, связывая его с IRI идентификатором RDFS класса
- Для каждого столбца, не являющегося ни частью главного ключа, ни частью внешнего ключа, строим тройку, содержащую IRI главного ключа в качестве субъекта (подлежащего), IRI столбца в качестве предиката и значения столбца в качестве объекта.
Раннее упоминание базового или прямого отображения можно найти в сравнении Тимом Бернерсом-Ли ER-модели с RDF моделью[4].
Сложные отображения реляционных баз данных в RDF
1:1 отображение, упомянутое выше представляет старые данные как RDF напрямую, а дополнительная доработка может быть использована для улучшения полноценности вывода RDF соответственно заданному сценарию использования. Как правило, информация теряется в течение преобразования диаграммы сущность-связь (англ. entity-relationship diagram, ERD) в реляционные таблицы (детальное описание можно найти в статье «Объектно-реляционная потеря соответствия[англ.]») и должна быть восстановлена путём обратного проектирования. С концептуальной точки зрения подходы для извлечения могут прийти с двух направлений. Первое направление пытается извлечь или обучить (с помощью машинного обучения) OWL схему из заданной схемы базы данных. Ранние подходы использовали фиксированное количество созданных вручную правил отображения для улучшения 1:1 отображения[5][6][7]. Более тщательно разработанные методы использовали эвристические или обучающие алгоритмы для порождения схематической информации (методы частично совпадают с обучением онтологий[англ.]). В то время как некоторые подходы пытаются извлечь информацию из структуры, присущей SQL схеме[8] (анализируя, например, внешние ключи), другие подходы анализируют содержимое и значения в таблицах для создания концептуальных иерархий[9] (например, столбцы с малым числом значений являются кандидатами стать категориями). Второе направление пытается отобразить схему и её содержимое в существующую онтологию предметной области (см. также «Отображение онтологий»). Часто, однако, подходящая онтология предметной области не существует и её сначала следует создать.
XML
Поскольку XML структурирован в виде дерева, любые данные легко представить в формате RDF, который структурирован в виде графа. XML2 RDF является одним примером подхода, который использует пустые узлы RDF и преобразует элементы и атрибуты XML в свойства RDF. Случай, однако, более сложен, чем в случае реляционных баз данных. В реляционных таблицах главный ключ является идеальным кандидатом для субъекта выделенных троек. XML элемент, однако, может быть преобразован — в зависимости о контекста — как субъект, как предикат или как объект тройки. XSLT может быть использован как стандартный язык преобразования для ручного преобразования XML в RDF.
Обзор методов / средств
| Название | Источник данных | Представление результата | Синхронизация данных | Язык отображения | Повторное исполь- зование словаря | Автома- тизация отобра- жения | Требуется онтология области | Исполь- зование GUI |
|---|---|---|---|---|---|---|---|---|
| Прямое отображение реляционных данных в RDF | Реляционные данные | SPARQL/ETL | динамическая | нет | автомати- ческая | нет | нет | |
| CSV2RDF4LOD | CSV | ETL | статическая | RDF | да | ручная | нет | нет |
| Convert2RDF | Текстовый файл с разделителями | ETL | статическая | RDF/DAML | да | ручная | нет | да |
| D2R Server Архивная копия от 26 февраля 2012 на Wayback Machine | РБД | SPARQL | двунаправленная | D2R Map | да | ручная | нет | нет |
| DartGrid | РБД | Язык запросов OWL | динамическая | Визуальные средства | да | ручная | нет | да |
| DataMaster | РБД | ETL | статическая | собственный | да | ручной | да | да |
| Расширение Google Refine’s RDF | CSV, XML | ETL | статическая | отсутствует | полуавто- матическая | нет | да | |
| Krextor | XML | ETL | статическая | XSLT | да | ручная | да | нет |
| MAPONTO | РБД | ETL | статическая | собственный | да | ручная | да | нет |
| METAmorphoses | РБД | ETL | статическая | собственный язык, базирующийся на xml отображении | да | ручная | нет | да |
| MappingMaster | CSV | ETL | статическая | MappingMaster | да | GUI | нет | да |
| ODEMapster | РБД | ETL | статическая | собственная | да | ручная | да | да |
| OntoWiki CSV Importer Plug-in — DataCube & Tabular | CSV | ETL | статическая | RDF Data Cube Vocaublary | да | полуавто- матическая | нет | да |
| Poolparty Extraktor (PPX) | XML, Text | LinkedData | динамическая | RDF (SKOS) | да | полуавто- матическая | да | нет |
| RDBToOnto | РБД | ETL | статическая | отсутствует | нет | автомати- ческая, пользователь имеет шанс тонкой настройки результата | нет | да |
| RDF 123 | CSV | ETL | статическая | нет | нет | ручная | нет | да |
| RDOTE | РБД | ETL | статическая | SQL | да | ручная | да | да |
| Relational.OWL | РБД | ETL | статическая | отсутствует | нет | автомати- ческая | нет | нет |
| T2LD | CSV | ETL | статическая | нет | нет | автомати- ческая | нет | нет |
| RDF-словарь куба данных[англ.] (англ. RDF Data Cube Vocabulary) | Многомерные статистические данные в электронных таблицах | словарь Куба данных | да | ручная | нет | |||
| TopBraid Composer | CSV | ETL | статическая | SKOS | нет | полуавто- матическая | нет | да |
| Triplify | РБД | LinkedData | динамическая | SQL | да | ручная | нет | нет |
| Ultrawrap | РБД | SPARQL/ ETL | динамическая | R2RML | да | полуавто- матическая | нет | да |
| Virtuoso RDF Views | РБД | SPARQL | динамическая | Meta Schema Language | да | полуавто- матическая | нет | да |
| Virtuoso Sponger | структури- рованные и полуструкту- рированные источники данных | SPARQL | динамическая | Virtuoso PL & XSLT | да | полуавто- матическая | нет | нет |
| VisAVis | РБД | RDQL[10] | ручная | SQL | да | ручная | да | да |
| XLWrap: Spreadsheet to RDF | CSV | ETL | статическая | TriG Syntax | да | ручная | нет | нет |
| XML в RDF | XML | ETL | статическая | нет | нет | автомати- ческая | нет | нет |
Извлечение из естественного языкового источника
Наибольшая порция информации, содержащаяся в бизнес-документе (около 80 %[11]), закодирована в естественном языке и потому не структурирована. Поскольку неструктурированные данные является, скорее, сложной задачей для извлечения знания, требуются более изощрённые методы, которые обычно дают худшие результаты по сравнению со структурированными данными. Однако возможность приобрести огромное количество извлечённых знаний компенсирует увеличивающуюся сложность и ухудшающееся качество извлечения. Далее источники на естественном языке понимаются как источники информации, в которых данные приведены как неструктурированные текстовые данные. Если данный текст вставлен в документ с разметкой (например, HTML-документ), упомянутые системы обычно удаляют элементы разметки автоматически.
Традиционное извлечение информации
Традиционное извлечение информации (англ. information extraction, IE[12])[13] — это технология обработки естественного языка, которая извлекает информацию из текстов на естественном языке и структурирует их подходящим образом. Виды информации, которые следует извлечь, должны быть указаны в модели перед началом процесса обработки, вот почему весь процесс традиционного извлечения информации зависим от рассматриваемой предметной области. ИЗ (англ. IE) распадается на следующие пять подзадач.
- Распознавание именованных сущностей[англ.] (англ. Named entity recognition, NER)
- Разрешение кореференции(англ. Coreference resolution, CO)
- Построение элементов шаблона (ПЭ, англ. Template element construction, TE) (или Добавление атрибутов к сущностям)
- Выявление связей между сущностями (ВС, англ. Template relation construction, TR)
- Построение полного описания события (ППО, англ. Template scenario production, ST)
Задача распознавания именованных сущностей заключается в узнавании и категоризации всех именованных сущностей, содержащихся в тексте (назначение именованным сущностям предопределённые категории). Это работает путём применения методов, основанных на грамматике, или на статистических моделях.
Разрешение кореференции устанавливает эквивалентные сущности, которые были распознаны в тексте алгоритмом NER. Есть два связанных вида отношения эквавалентности. Первое отношение относится к связи между двумя различными сущностями (например, IBM Europe и IBM), а второе относится к связи между сущностью и её анафорической ссылкой (например, it и IBM). Оба вида могут быть распознаны разрешением кореференции.
Во время построения элементов шаблона система IE устанавливает описательные свойства сущностей, распознанные системами NER и CO. Эти свойства соответствуют обычным качествам, как «красный» или «большой».
Выявление связей между отдельными сущностями устанавливает отношения, которые существуют между элементами шаблона. Эти отношения могут быть нескольких видов, такие как работает-для или расположено-в, с ограничением, что как область, так и диапазон соответствуют сущностям.
Полные описания событий, которые проводятся в тексте, распознаются и структурируются согласно сущностям, распознанных системами NER и CO, а отношения распознаются системой ВС.
Извлечение информации на основе онтологий
Извлечение информации на основе онтологий (англ. Ontology-based information extraction, OBIE)[11] является подобластью извлечения информации, в которой используется по меньшей мере одна онтология для управления процессом извлечения информации из текста на естественном языке. Система OBIE использует методы традиционного извлечения информации для распознавания понятий, сущностей и отношений использованных онтологий в тексте, которые будут структурированы в онтологию после процесса. Таким образом, вводимые онтологии формируют модель извлекаемой информации.
Обучение онтологий
Обучение онтологий (англ. Ontology learning, OL) это автоматическое или полуавтоматическое создание онтологий, включая извлечение соответствующих терминов объектной области из текста естественного языка. Так как построение онтологий вручную требует крайне интенсивной работы и затрат времени, существует большой стимул для автоматизации процесса.
Семантическое аннотирование
Во время семантического аннотирования (англ. semantic annotation, SA)[14] текст на естественном языке сопровождается метаданными (часто представимы в атрибутах RDF[англ.], англ. Resource Description Framework in Attributes), которые должны сделать семантику содержащихся элементов понимаемыми машинами. В этом процессе, который обычно является полуавтоматическим, знания извлекаются в том смысле, что устанавливается связь между лексическими элементами и, например, понятиями из онтологий. Таким образом получаем знания, которые открывают значение сущности в обрабатываемом контексте, а потому определяет значение текста в воспринимаемой машиной информации[англ.] с возможностью делать логические выводы. Семантическая аннотация обычно расщепляется на следующие две подзадачи.
- Извлечение терминологии
- Связывание именованных сущностей
На уровне извлечения терминологии из текста извлекаются лексические термины. С этой целью лексический анализатор сначала определяет границы слов и выделяет аббревиатуры. Затем из текста извлекаются термины, которые соответствуют понятиям, с помощью словаря специфичных области исследования для связывания сущностей.
При связывании сущностей[15] устанавливается связь между извлечёнными лексическими членами из текста-источника и понятиями из онтологии или базы знаний, такой как DBpedia. Для этого кандидаты в понятия выявляются согласно определённым значениям элемента с помощью словаря. Наконец, анализируется контекст терминов для определения наиболее подходящего разрешения многозначности и термину назначается правильное понятие.
Средства
Следующие критерии могут быть использованы для категоризации средств, которые извлекают знание из текстов на естественном языке.
| Источник | Какие входные форматы могут быть обработаны (простой текст, HTML или PDF, например)? |
| Парадигма доступа | Может ли средство запросить часть данных из источника или необходим полный дамп для процесса извлечения? |
| Синхронизация данных | Синхронизирован ли результат извлечения с источником? |
| Использование объектной модели | Связывает ли средство результат с объектной моделью? |
| Автоматизация отображения | Насколько автоматизирован процесс извлечения (ручной, полуавтоматический или автоматический)? |
| Требование объектной модели | Требует ли средство наличия объектной модели для извлечения? |
| Использование GUI | Имеет ли средство графический пользовательский интерфейс (англ. Graphical User Interface, GUI)? |
| Подход | Какой подход (IE, OBIE, OL или SA) средство использует? |
| Извлекаемые сущности | Какие типы сущностей (например, именованные сущности, концепции или отношения) могут быть извлечены средством? |
| Применяемые техники | Какие техники применяются (например, NLP, статистические методы, кластеризация или машинное обучение)? |
| Выходная модель | Какая модель используется для представления результата средства (например, RDF или OWL)? |
| Поддерживаемые предметные области | Какие предметные области поддерживаются (например, экономика или биология)? |
| Поддерживаемые языки | Какие языки могут быть обработаны (например, английский, немецкий или русский)? |
Следующая таблица описывает некоторые средства для извлечения знаний из источников естественного языка.
| Название | Источник | Парадигма доступа | Синхронизация данных | Использование объектной модели | Автоматизация отображения | Требование объектной модели | Использование GUI | Подход | Извлекаемые сущности | Применяемые техники | Выходная модель | Поддерживаемые области | Поддерживаемые языки |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AeroText[16] | текстовые данные, HTML, XML, SGML | дамп | нет | да | автоматическое | да | да | IE | именованные сущности, связи, события | лингвинистические правила | собственная | не зависит от области | английский, испанский, арабский, китайский, индонезийский |
| AlchemyAPI[17] | текстовые данные, HTML | автоматическое | да | SA | многоязычный | ||||||||
| ANNIE | текстовые данные | дамп | да | да | IE | алгоритмы конечного автомата | многоязычный | ||||||
| ASIUM (LRI) | текстовые данные | дамп | полуавтомат | да | OL | понятия, иерархия понятий | NLP, кластеризация | ||||||
| Exhaustive Extraction компании Attensity[англ.] | автоматическое | IE | именованные сущности, связи, события | NLP | |||||||||
| Dandelion API | текстовые данные, HTML, URL | REST | нет | нет | автоматически | нет | да | SA | именованные сущности, понятия | статистические методы | JSON | не зависит от области | многоязычный |
| DBpedia Spotlight[19] | текстовые данные, HTML | дамп, SPARQL | да | да | автоматическое | нет | да | SA | annotation to each word, annotation to non-stopwords | NLP, statistical methods, машинное обучение | RDFa | не зависит от области | английский |
| EntityClassifier.eu | текстовые данные, HTML | дамп | да | да | автоматическое | нет | да | IE, OL, SA | annotation to each word, annotation to non-stopwords | rule-based grammar | XML | не зависит от области | английский, немецкий, голландский |
| FRED[20] | текстовые данные | дамп, REST API | да | да | автоматическое | нет | да | IE, OL, SA, онтологические шаблоны проектирования, семантика фреймов | слова NIF или EarMark аннотация, предикаты, экземпляры, композиционная семантика, понятия таксономий, семантические роли, описательные отношения, события, наклонение, грамматическое время, связывание именованных сущностей, связывание событий, эмоции | NLP, машинное обучение, heuristic rules | RDF / OWL | не зависит от области | английский, другие языки после перевода |
| iDocument[21] | HTML, PDF, DOC | SPARQL | да | да | OBIE | instances, property values | NLP | personal, business | |||||
| NetOwl Extractor[22] | текстовые данные, HTML, XML, SGML, PDF, MS Office | дамп | нет | да | автоматически | да | да | IE | именованные сущности, связи, события | NLP | XML, JSON, RDF — OWL, others | множественные области | английский, арабский, китайский (упрощённый и традийионный), французский, корейский, персидский (фарси и дари), русский, испанский |
| OntoGen Архивная копия от 30 марта 2010 на Wayback Machine[23] | полуавтомат | да | OL | понятия, иерархия понятий, non-taxonomic отношения, instances | NLP, машинное обучение, кластеризация | ||||||||
| OntoLearn Архивная копия от 9 августа 2017 на Wayback Machine[24] | текстовые данные, HTML | дамп | нет | да | автоматически | да | нет | OL | понятия, иерархия понятий, instances | NLP, statistical methods | собственная | не зависит от области | английский |
| OntoLearn Reloaded | текстовые данные, HTML | дамп | нет | да | автоматически | да | нет | OL | понятия, иерархия понятий, instances | NLP, statistical methods | собственная | не зависит от области | английский |
| OntoSyphon[25] | HTML, PDF, DOC | дамп, search engine queries | нет | да | автоматически | да | нет | OBIE | понятия, отношения, instances | NLP, statistical methods | RDF | не зависит от области | английский |
| ontoX[26] | текстовые данные | дамп | нет | да | полуавтоматически | да | нет | OBIE | instances, datatype property values | heuristic-based methods | собственная | не зависит от области | не зависит от языка |
| OpenCalais | текстовые данные, HTML, XML | дамп | нет | да | автоматически | да | нет | SA | annotation to entities, annotation to события, annotation to facts | NLP, машинное обучение | RDF | не зависит от области | английский, французский, испанский |
| PoolParty Extractor (2011) | текстовые данные, HTML, DOC, ODT | дамп | нет | да | автоматически | да | да | OBIE | именованные сущности, понятия, отношения, понятия, that categorize the text, enrichments | NLP, машинное обучение, статистические методы | RDF, OWL | не зависит от области | английский, немецкий, испанский, французский |
| Rosoka | текстовые данные, HTML, XML, SGML, PDF, MS Office | дамп | да | да | автоматически | нет | да | IE | извлечение именованных сущностей, разрешение сущностей, извлечение связей, атрибутов, понятий, мультивекторный анализ тональности высказывания, геопривязка, идентификация языка, машинное обучение | NLP | XML, JSON, POJO | множественные области | многоязычный (200+ язык) |
| SCOOBIE | текстовые данные, HTML | дамп | нет | да | автоматически | нет | нет | OBIE | instances, property values, RDFS types | NLP, машинное обучение | RDF, RDFa | не зависит от области | английский, немецкий |
| SemTag[27][28] | HTML | дамп | нет | да | автоматически | да | нет | SA | машинное обучение | database record | не зависит от области | не зависит от языка | |
| smart FIX | текстовые данные, HTML, PDF, DOC, e-Mail | дамп | да | нет | автоматически | нет | да | OBIE | именованные сущности | NLP, машинное обучение | собственная | не зависит от области | английский, немецкий, французский, голландский, польский |
| Text2Onto[29] | текстовые данные, HTML, PDF | дамп | да | нет | полуавтоматически | да | да | OL | понятия, концепция понятий, non-taxonomic отношения, instances, axioms | NLP, статистические методы, машинное обучение, rule-based methods | OWL | не зависит от области | английский, немецкий, испанский |
| Text-To-Onto[30] | текстовые данные, HTML, PDF, PostScript | дамп | полуавтоматически | да | да | OL | понятия, иерархия понятий, non-taxonomic отношения, lexical entities referring понятиям, lexical entities referring to отношения | NLP, машинное обучение, кластеризация, статистические методы | немецкий | ||||
| ThatNeedle | Текстовые данные | дамп | автоматически | нет | понятия, отношения, hierarchy | NLP, собственная | JSON | множественные области | английский | ||||
| The Wiki Machine[31] | текстовые данные, HTML, PDF, DOC | дамп | нет | да | автоматически | да | да | SA | маркировка имен собственных, маркировка имён нарицательных | машинное обучение | RDFa | независимый от области | английский, немецкий, испанский, французский, португальский, итальянский, русский |
| ThingFinder[32] | IE | именованные сущности, связи, события | многоязычный |
Обнаружение знаний
Обнаружение знаний описывает процесс автоматического поиска больших объёмов данных для моделей, которые могут считаться знанием о данных[33]. Это часто описывается как извлечение знания из входных данных. Обнаружение знаний разрабатывается для анализа данных и тесно связано как с методологией, так и терминологией[34].
Наиболее известная ветвь интеллектуального анализа данных — обнаружение знаний, известное также как обнаружение знаний в базах данных. Как и многие другие формы обнаружения знаний, этот анализ создаёт абстракции входных данных. Знание, приобретённое в результате этого процесса, может стать дополнительными данными, которые могут быть использованы для дальнейшего использования и поисков. Часто выходные данные процесса обнаружения знаний не имеет практической ценности, так что обнаружение активного знания[англ.], известное также как «Анализ данных по предметной области[англ.]»[35], предназначено для обнаружения и извлечения (имеющего практическое значение) активного знания и выводов из этого знания.
Другое перспективное приложение обнаружения знаний находится в области модернизации программного обеспечения[англ.], обнаружения слабых мест и соответствия стандартам, которое вовлекает понимание существующего программного обеспечения. Этот процесс связан с понятием обратной разработки. Обычно знание, получаемое из существующего программного обеспечения, представляется в виде моделей, к которым могут быть сделаны конкретные запросы, если необходимо. Модель сущность — связь является частым форматом, представляющим знание и получаемым из существующего программного обеспечения. Консорциум Object Management Group разработал спецификацию метамодели обнаружения знаний[англ.] (англ. Knowledge Discovery Metamodel, KDM), которая определяет онтологию для программных ресурсов и их связей, предназначенную для обнаружения знаний в существующем коде. Обнаружение знаний из известных программных систем, известное также как интеллектуальный анализ программного обеспечения[англ.], тесно связано с интеллектуальным анализом данных, поскольку существующие программные находки имеют огромное значение для управления рисками и коммерческую ценность[англ.], которые служат ключевыми элементами для анализа и развития программных систем. Вместо анализа индивидуальных наборов данных интеллектуальный анализ программного обеспечения[англ.] фокусируется на метаданных, таких как производственный поток (например, поток данных, поток управления, схема вызовов), архитектуре, схемах баз данных и деловых правилах/терминах/процессах.
Ввод данных
- Базы данных
- Реляционные данные[англ.]
- База данных
- Хранилище документов[англ.]
- Хранилище данных
- Программное обеспечение[англ.]
- Исходный код
- Конфигурационные файлы
- Скрипты сборки
- Текст
- Извлечения понятий[англ.]
- Графы[англ.]
- Интеллектуальный анализ молекул[англ.]
- Последовательности[англ.]
- Web
Форматы вывода
- Модель данных
- Метаданные
- Метамодели
- Онтология
- Представление знаний
- Тег (метаданные)
- Деловые правила[англ.]
- Метамодель обнаружения знаний[англ.]
- Нотация и модель бизнес-процессов
- Промежуточное представление
- Среда описания ресурса
- Метрики программного обеспечения
См. также
Примечания
- ↑ RDB2RDF Working Group, Website: http://www.w3.org/2001/sw/rdb2rdf/ Архивная копия от 11 мая 2016 на Wayback Machine, charter: http://www.w3.org/2009/08/rdb2rdf-charter Архивная копия от 20 марта 2016 на Wayback Machine, R2RML: RDB в RDF Mapping Language: http://www.w3.org/TR/r2rml/ Архивная копия от 10 октября 2021 на Wayback Machine
- ↑ LOD2 EU (недоступная ссылка) Deliverable 3.1.1 Knowledge Extraction from Structured Sources
- ↑ Calais Release 4, 2009.
- ↑ 1 2 Berners-Lee, 1998.
- ↑ Hu, Qu, 2007, с. 225‐238.
- ↑ Ghawi, Cullot, 2007.
- ↑ Li, Du, Wang, 2005, с. 209—220.
- ↑ Tirmizi, Miranker, Sequeda, 2008.
- ↑ Cerbah, 2008.
- ↑ RDQL = RDF Query Language
- ↑ 1 2 Wimalasuriya, Dou, 2010, с. 306 – 323.
- ↑ Не путать с MS IE = Интернет эксплорер компании Микрософт!
- ↑ Cunningham, 2005, с. 665–677.
- ↑ Erdmann, Maedche, Schnurr, Staab, 2000.
- ↑ Rao, McNamee, Dredze, 2011, с. 93—115.
- ↑ Rocket Software, Inc. (2012). «technology for extracting intelligence from text»
- ↑ Orchestr8 (2012): «AlchemyAPI Overview»
- ↑ The University of Sheffield (2011). «ANNIE: a Nearly-New Information Extraction System»
- ↑ Mendes, Jakob, Garcia-Sílva, Bizer, 2011, с. 1 – 8.
- ↑ Gangemi, Presutti, Recupero и др., 2016.
- ↑ Adrian, Maus, Dengel, 2009.
- ↑ SRA International, Inc. (2012). «NetOwl Extractor»
- ↑ Fortuna, Grobelnik, Mladenic, 2007, с. 309–318.
- ↑ Missikoff, Navigli, Velardi, 2002, с. 60 – 63.
- ↑ McDowell, Cafarella, 2006, с. 428 – 444.
- ↑ Yildiz, Miksch, 2007, с. 660 – 673.
- ↑ Dill, Eiron, Gibson и др., 2003, с. 178 – 186.
- ↑ Uren, Cimiano, Iria и др., 2006, с. 14 – 28.
- ↑ Cimiano, Völker, 2005.
- ↑ Maedche, Volz, 2001.
- ↑ Machine Linking. «We connect to the Linked Open Data cloud»
- ↑ Inxight ThingFinder and ThingFinder Professional. Inxight Federal Systems (2008). Дата обращения: 18 июня 2012. Архивировано из оригинала 29 июня 2012 года.
- ↑ Frawley, Piatetsky-Shapiro, Matheus, 1992, с. 57—70.
- ↑ Fayyad, Piatetsky-Shapiro, Smyth, 1996, с. 37—54.
- ↑ Cao, 2010, с. 755–769.
Литература
- Cao L. Domain driven data mining: challenges and prospects // IEEE Trans. on Knowledge and Data Engineering. — 2010. — Т. 22, вып. 6. — doi:10.1109/tkde.2010.32.
- Life in the Linked Data Cloud // www.opencalais.com. — 2009. Архивировано 24 ноября 2009 года. Выдержка: Википедия имеет двойника с именем DBpedia. DBpedia имеет ту же структурированную информацию, что и Википедия, но преобразованную в понимаемый машинами формат.
- Benjamin Adrian, Heiko Maus, Andreas Dengel. iDocument: Using Ontologies for Extracting Information from Text. — 2009.
- William J. Frawley, Gregory Piatetsky-Shapiro, Christopher J. Matheus. Knowledge Discovery in Databases: An Overview // AI Magazine. — 1992. — Т. 13, № 3. — С. 57—70. Архивировано 4 марта 2016 года.
- Usama M. Fayyad, Gregory Piatetsky-Shapiro, Padhraic Smyth. From Data Mining to Knowledge Discovery in Databases // AI Magazine. — 1996. — Т. 17, № 3. — С. 37—54. Архивировано 4 мая 2016 года.
- Tim Berners-Lee. Relational Databases on the Semantic Web. — 1998.
- Farid Cerbah. Learning Highly Structured Semantic Repositories from Relational Databases // The Semantic Web: Research and Applications. — Berlin / Heidelberg: Springer, 2008. — Т. 5021. — (Lecture Notes in Computer Science). Архивная копия от 20 июля 2011 на Wayback Machine
- Syed Hamid Tirmizi, Daniel P. Miranker, Juan Sequeda. Translating SQL Applications to the Semantic Web // Database and Expert Systems Applications. — 2008. — Т. 5181/2008. — (Lecture Notes in Computer Science).
- Wei Hu, Yuzhong Qu. Discovering Simple Mappings Between Relational Database Schemas and Ontologies // Proc. of 6th International Semantic Web Conference (ISWC 2007), 2nd Asian Semantic Web Conference (ASWC 2007). — Busan, Korea, 11‐15 November 2007, 2007. — Т. 4825. — С. 225‐238. — (Lecture Notes in Computer Science).
- Ghawi R., Cullot N. Database-to-Ontology Mapping Generation for Semantic Interoperability // Third International Workshop on Database Interoperability (InterDB 2007).. — 2007.
- Man Li, Xiaoyong Du, Shan Wang. A Semi-automatic Ontology Acquisition Method for the Semantic Web // WAIM. — Springer, 2005. — Т. 3739. — С. 209—220. — (Lecture Notes in Computer Science). — doi:10.1007/11563952_19.
- Aldo Gangemi, Valentina Presutti, Diego Reforgiato Recupero, Andrea Giovanni Nuzzolese, Francesco Draicchio, Misael Mongiovì. Semantic Web Machine Reading with FRED // Semantic Web Journal. — 2016. — doi:10.3233/SW-160240.
- Philipp Cimiano, Johanna Völker. Text2Onto - A Framework for Ontology Learning and Data-Driven Change Discovery // Proceedings of the 10th International Conference of Applications of Natural Language to Information Systems. — 2005. — Т. 3513. — С. 227 – 238.
- Hamish Cunningham. Information Extraction, Automatic // Encyclopedia of Language and Linguistics. — 2005. — С. 665 – 677.
- Stephen Dill, Nadav Eiron, David Gibson, Daniel Gruhl, R. Guha, Anant Jhingran, Tapas Kanungo, Sridhar Rajagopalan, Andrew Tomkins, John A. Tomlin, Jason Y. Zien. SemTag and Seeker: Bootstraping the Semantic Web via Automated Semantic Annotation // Proceedings of the 12th international conference on World Wide Web. — 2003. — С. 178 – 186.
- Erdmann M., Maedche A., Schnurr H.-P., Staab S. From Manual to Semi-automatic Semantic Annotation: About Ontology-based Text Annotation Tools // Proceedings of the COLING. — 2000.
- Blaz Fortuna, Marko Grobelnik, Dunja Mladenic. OntoGen: Semi-automatic Ontology Editor // Proceedings of the 2007 conference on Human interface, Part 2. — 2007. — С. 309 – 318.
- Alexander Maedche, Raphael Volz. The Ontology Extraction & Maintenance Framework Text-To-Onto // Proceedings of the IEEE International Conference on Data Mining. — 2001.
- Luke K. McDowell, Michael Cafarella. Ontology-driven Information Extraction with OntoSyphon // Proceedings of the 5th international conference on The Semantic Web. — 2006. — С. 428 – 444.
- Pablo N. Mendes, Max Jakob, Andrés Garcia-Sílva, Christian Bizer. DBpedia Spotlight: Shedding Light on the Web of Documents // Proceedings of the 7th International Conference on Semantic Systems. — 2011. — С. 1 – 8. Архивная копия от 5 апреля 2012 на Wayback Machine
- Delip Rao, Paul McNamee, Mark Dredze. Entity Linking: Finding Extracted Entities in a Knowledge Base // Multi-source, Multi-lingual Information Extraction and Summarization. — 2011. (недоступная ссылка)
- Victoria Uren, Philipp Cimiano, José Iria, Siegfried Handschuh, Maria Vargas-Vera, Enrico Motta, Fabio Ciravegna. Semantic annotation for knowledge management: Requirements and a survey of the state of the art // Web Semantics: Science, Services and Agents on the World Wide Web. — 2006. — Т. 4, вып. 1. — С. 14 – 28. (недоступная ссылка)
- Daya C. Wimalasuriya, Dejing Dou. Ontology-based information extraction: An introduction and a survey of current approaches // Journal of Information Science. — 2010. — Т. 36, вып. 3. — С. 306 – 323.
- Burcu Yildiz, Silvia Miksch. ontoX - A Method for Ontology-Driven Information Extraction // Proceedings of the 2007 international conference on Computational science and its applications. — 2007. — Т. 3. — С. 660 – 673.
| Основы | |
|---|---|
| Подразделы |
|
| Приложения |
|
| Связанные темы | |
| Стандарты |
|