
Нейро́нная сеть — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети У. Маккалока и У. Питтса. После разработки алгоритмов обучения получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др.
Рекуррентные нейронные сети — вид нейронных сетей, где связи между элементами образуют направленную последовательность. Благодаря этому появляется возможность обрабатывать серии событий во времени или последовательные пространственные цепочки. В отличие от многослойных перцептронов, рекуррентные сети могут использовать свою внутреннюю память для обработки последовательностей произвольной длины. Поэтому сети RNN применимы в таких задачах, где нечто целостное разбито на части, например: распознавание рукописного текста или распознавание речи. Было предложено много различных архитектурных решений для рекуррентных сетей от простых до сложных. В последнее время наибольшее распространение получили сеть с долговременной и кратковременной памятью (LSTM) и управляемый рекуррентный блок (GRU).

Джеффри Хи́нтон — британский и канадский учёный, внёсший заметный вклад в глубокое обучение.

Свёрточная нейронная сеть — специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном в 1988 году и нацеленная на эффективное распознавание образов, входит в состав технологий глубокого обучения. Использует некоторые особенности зрительной коры, в которой были открыты так называемые простые клетки, реагирующие на прямые линии под разными углами, и сложные клетки, реакция которых связана с активацией определённого набора простых клеток. Таким образом, идея свёрточных нейронных сетей заключается в чередовании свёрточных слоёв и субдискретизирующих слоёв. Структура сети — однонаправленная, принципиально многослойная. Для обучения используются стандартные методы, чаще всего метод обратного распространения ошибки. Функция активации нейронов — любая, по выбору исследователя.
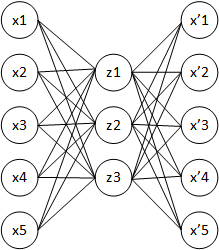
Автокодировщик — специальная архитектура искусственных нейронных сетей, позволяющая применять обучение без учителя при использовании метода обратного распространения ошибки. Простейшая архитектура автокодировщика — сеть прямого распространения, без обратных связей, наиболее схожая с перцептроном и содержащая входной слой, промежуточный слой и выходной слой. В отличие от перцептрона, выходной слой автокодировщика должен содержать столько же нейронов, сколько и входной слой.
Глубокое обучение — совокупность методов машинного обучения, основанных на обучении представлениям, а не специализированных алгоритмах под конкретные задачи. Многие методы глубокого обучения были известны ещё в 1980-е, но результаты не впечатляли, пока продвижения в теории искусственных нейронных сетей и вычислительные мощности середины 2000-х годов не позволили создавать сложные технологические архитектуры нейронных сетей, обладающие достаточной производительностью и позволяющие решать широкий спектр задач, не поддававшихся эффективному решению ранее, например, в компьютерном зрении, машинном переводе, распознавании речи, причём качество решения во многих случаях теперь сопоставимо, а в некоторых превосходит эффективность человека.

Глубокая сеть доверия — это порождающая графическая модель, или, иначе, один из типов глубинных нейронных сетей, состоящая из нескольких скрытых слоев, в которых нейроны внутри одного слоя не связаны друг с другом, но связаны с нейронами соседнего слоя.

Импульсная нейронная сеть или Спайковая нейронная сеть — третье поколение искусственных нейронных сетей (ИНС), которое отличается от бинарных и частотных/скоростных ИНС тем, что в нем нейроны обмениваются короткими импульсами одинаковой амплитуды . Является самой реалистичной, с точки зрения физиологии, моделью ИНС.

Длинная цепь элементов краткосрочной памяти — разновидность архитектуры рекуррентных нейронных сетей, предложенная в 1997 году Зеппом Хохрайтером и Юргеном Шмидхубером. Как и большинство рекуррентных нейронных сетей, LSTM-сеть является универсальной в том смысле, что при достаточном числе элементов сети она может выполнить любое вычисление, на которое способен обычный компьютер, для чего необходима соответствующая матрица весов, которая может рассматриваться как программа. В отличие от традиционных рекуррентных нейронных сетей, LSTM-сеть хорошо приспособлена к обучению на задачах классификации, обработки и прогнозирования временных рядов в случаях, когда важные события разделены временными лагами с неопределённой продолжительностью и границами. Относительная невосприимчивость к длительности временных разрывов даёт LSTM преимущество по отношению к альтернативным рекуррентным нейронным сетям, скрытым марковским моделям и другим методам обучения для последовательностей в различных сферах применения. Из множества достижений LSTM-сетей можно выделить наилучшие результаты в распознавании несегментированного слитного рукописного текста, и победу в 2009 году на соревнованиях по распознаванию рукописного текста (ICDAR). LSTM-сети также используются в задачах распознавания речи, например LSTM-сеть была основным компонентом сети, которая в 2013 году достигла рекордного порога ошибки в 17,7 % в задаче распознавания фонем на классическом корпусе естественной речи TIMIT. По состоянию на 2016 год ведущие технологические компании, включая Google, Apple, Microsoft и Baidu, используют LSTM-сети в качестве фундаментального компонента новых продуктов.
Нейронный машинный перевод — это подход к машинному переводу, в котором используется большая искусственная нейронная сеть. Он отличается от методов машинного перевода, основанных на статистике фраз, которые используют отдельно разработанные подкомпоненты.
Генеративно-состязательная сеть — алгоритм машинного обучения без учителя, построенный на комбинации из двух нейронных сетей, одна из которых генерирует образцы, а другая старается отличить правильные («подлинные») образцы от неправильных. Так как сети G и D имеют противоположные цели — создать образцы и отбраковать образцы — между ними возникает антагонистическая игра. Генеративно-состязательную сеть описал Ян Гудфеллоу из компании Google в 2014 году.

Ограниченная машина Больцмана, сокращённо RBM — вид генеративной стохастической нейронной сети, которая определяет распределение вероятности на входных образцах данных.
Капсульная нейронная сеть — архитектура искусственных нейронных сетей, которая предназначена для распознавания изображений.
Рекурсивные нейронные сети — вид нейронных сетей, работающих с данными переменной длины. Модели рекурсивных сетей используют иерархические структуры образцов при обучении. Например, изображения, составленные из сцен, объединяющих подсцены, включающие много объектов. Выявление структуры сцены и её деконструкция- нетривиальная задача. При этом необходимо как идентифицировать отдельные объекты, так и всю структуру сцены.

В искусственных нейронных сетях функция активации нейрона определяет выходной сигнал, который определяется входным сигналом или набором входных сигналов. Стандартная компьютерная микросхема может рассматриваться как цифровая сеть функций активации, которые могут принимать значения «ON» (1) или «OFF» (0) в зависимости от входа. Это похоже на поведение линейного перцептрона в нейронных сетях. Однако только нелинейные функции активации позволяют таким сетям решать нетривиальные задачи с использованием малого числа узлов. В искусственных нейронных сетях эта функция также называется передаточной функцией.
Обучение признакам или обучение представлениям — это набор техник, которые позволяют системе автоматически обнаружить представления, необходимые для выявления признаков или классификации исходных (сырых) данных. Это заменяет ручное конструирование признаков и позволяет машине как изучать признаки, так и использовать их для решения специфичных задач.
Нейронная сеть с прямой связью — искусственная нейронная сеть, в которой соединения между узлами не образуют цикл. Такая сеть отличается от рекуррентной нейронной сети. Нейронная сеть с прямой связью была первым и самым простым типом искусственной нейронной сети. В этой сети информация перемещается только в одном направлении вперед от входных узлов, через скрытые узлы и к выходным узлам. В сети нет циклов или петель обратных связей.
Процессор глубокого обучения или ускоритель глубокого обучения — это электронная схема, разработанная для алгоритмов глубокого обучения, обычно с отдельной памятью данных и специализированной архитектурой набора команд. Процессоры глубокого обучения варьируются от мобильных устройств, таких как блоки нейронной обработки (NPU) в мобильных телефонах Huawei, до серверов облачных вычислений, таких какТензорный процессор Google (TPU) в Google Cloud Platform.

Илья́ Суцке́вер — канадский и американский учёный в области информатики, искусственного интеллекта и машинного обучения. Сооснователь компании OpenAI.

Generative pre-trained transformer или GPT — это тип нейронных языковых моделей, впервые представленных компанией OpenAI, которые обучаются на больших наборах текстовых данных, чтобы генерировать текст, схожий с человеческим. Предобучение относится к начальному процессу обучения на корпусе, в результате которого модель учится предсказывать следующее слово в тексте и получает основу для успешного выполнения дальнейших задач, не имея больших объёмов данных. GPT являются «трансформерами», которые представляют собой тип нейросетей, использующих механизм самосвязываемости для обработки последовательных данных. Они могут быть дообучены для различных задач обработки естественного языка (NLP), таких как генерация текста, машинный перевод и классификация текста.