
Вычислительная математика — раздел математики, включающий круг вопросов, связанных с производством разнообразных вычислений. В более узком понимании вычислительная математика — теория численных методов решения типовых математических задач. Современная вычислительная математика включает в круг своих проблем изучение особенностей вычисления с применением компьютеров.
Математи́ческий ана́лиз — совокупность разделов математики, соответствующих историческому разделу под наименованием «анализ бесконечно малых», объединяет дифференциальное и интегральное исчисления.
Сплайн — функция в математике, область определения которой разбита на конечное число отрезков, на каждом из которых она совпадает с некоторым алгебраическим многочленом (полиномом). Максимальная из степеней использованных полиномов называется степенью сплайна. Разность между степенью сплайна и получившейся гладкостью называется дефектом сплайна. Например, непрерывная ломаная есть сплайн степени 1 и дефекта 1. В современном понимании сплайны — это решения многоточечных краевых задач сеточными методами.
Аппроксима́ция или приближе́ние — научный метод, состоящий в замене одних объектов другими, в каком-то смысле близкими к исходным, но более простыми.
Интерполя́ция, интерполи́рование — в вычислительной математике нахождение неизвестных промежуточных значений некоторой функции, по имеющемуся дискретному набору её известных значений, определенным способом. Термин «интерполяция» впервые употребил Джон Валлис в своём трактате «Арифметика бесконечных» (1656).
Га́уссовский проце́сс в теории случайных процессов — это вещественный процесс, чьи конечномерные распределения гауссовские.
Дифференциа́льный опера́тор — оператор, определённый некоторым дифференциальным выражением и действующий в пространствах функций на дифференцируемых многообразиях или в пространствах, сопряжённых к пространствам этого типа.
Регрессио́нный анализ — набор статистических методов исследования влияния одной или нескольких независимых переменных  на зависимую переменную
на зависимую переменную  . Независимые переменные иначе называют регрессорами или предикторами, а зависимые переменные — критериальными или регрессантами. Терминология зависимых и независимых переменных отражает лишь математическую зависимость переменных, а не причинно-следственные отношения. Наиболее распространённый вид регрессионного анализа — линейная регрессия, когда находят линейную функцию, которая, согласно определённым математическим критериям, наиболее соответствует данным. Например, в методе наименьших квадратов вычисляется прямая, сумма квадратов между которой и данными минимальна.
. Независимые переменные иначе называют регрессорами или предикторами, а зависимые переменные — критериальными или регрессантами. Терминология зависимых и независимых переменных отражает лишь математическую зависимость переменных, а не причинно-следственные отношения. Наиболее распространённый вид регрессионного анализа — линейная регрессия, когда находят линейную функцию, которая, согласно определённым математическим критериям, наиболее соответствует данным. Например, в методе наименьших квадратов вычисляется прямая, сумма квадратов между которой и данными минимальна.
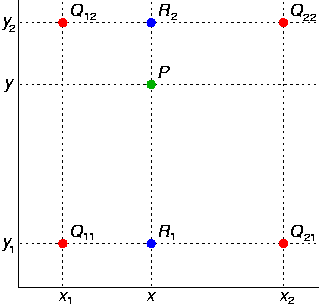
Билине́йная интерполя́ция — в вычислительной математике — обобщение линейной интерполяции одной переменной для функций двух переменных.
Задача целочисленного программирования — это задача математической оптимизации или выполнимости, в которой некоторые или все переменные должны быть целыми числами. Часто термин адресуется к целочисленному линейному программированию (ЦЛП), в котором целевая функция и ограничения линейны.
Численные (вычислительные) методы — методы решения математических задач в численном виде.

Приближение с помощью кривых — это процесс построения кривой или математической функции, которая наилучшим образом приближается к заданным точкам с возможными ограничениями на кривую. Для построения такого приближения может использоваться либо интерполяция, где требуется точное прохождение кривой через точки, либо сглаживание, когда «сглаживающая» функция проходит через точки приближённо. Связанный раздел — регрессионный анализ, который фокусируется, главным образом, на вопросах статистического вывода, таких как, какая неопределённость заключена в кривой, которая приближает данные с некоторыми случайными ошибками. Построенные кривые могут быть использованы для визуализации данных, для вычисления значений функции в точках, в которых значение не задано и для определения связи между двумя и более переменными. Экстраполяция означает использование полученной кривой за пределами данных, полученных из наблюдения, и порождает некоторую неопределённость, поскольку может зависеть от метода построения кривой.

Нелинейная регрессия — это вид регрессионного анализа, в котором экспериментальные данные моделируются функцией, являющейся нелинейной комбинацией параметров модели и зависящей от одной и более независимых переменных. Данные аппроксимируются методом последовательных приближений.
Линейный дискриминантный анализ, нормальный дискриминантный анализ или анализ дискриминантных функций является обобщением линейного дискриминанта Фишера, метода, используемого в статистике, распознавании образов и машинном обучении для поиска линейной комбинации признаков, которая описывает или разделяет два или более классов или событий. Получившаяся комбинация может быть использована как линейный классификатор, или, более часто, для снижения размерности перед классификацией.
Статистическая теория обучения — это модель для машинного обучения на основе статистики и функционального анализа. Статистическая теория обучения имеет дело с задачами нахождения функции предсказывания, основанной на данных. Статистическая теория обучения привела к успешным приложениям в таких областях, как компьютерное зрение, распознавание речи и биоинформатика.

Компромисс отклонение-дисперсия в статистике и в машинном обучении — это свойство набора моделей предсказания, когда модели с меньшим отклонением от имеющихся данных имеют более высокую дисперсию на новых данных, и наоборот. Компромисс отклонение-дисперсия — конфликт при попытке одновременно минимизировать эти два источника ошибки, которые мешают алгоритмам обучения с учителем делать обобщение за пределами тренировочного набора.
- Смещение — это погрешность оценки, возникающая в результате ошибочного предположения в алгоритме обучения. В результате большого смещения алгоритм может пропустить связь между признаками и выводом (недообучение).
- Дисперсия — это ошибка чувствительности к малым отклонениям в тренировочном наборе. При высокой дисперсии алгоритм может как-то трактовать случайный шум в тренировочном наборе, а не желаемый результат (переобучение).
Онлайновое машинное обучение — это метод машинного обучения, в котором данные становятся доступными в последовательном порядке и используются для обновления лучшего предсказания для последующих данных, выполняемого на каждом шаге обучения. Метод противоположен пакетной технике обучения, в которой лучшее предсказание генерируется за один раз, исходя из полного тренировочного набора данных. Онлайновое обучение является общей техникой, используемой в областях машинного обучения, когда невозможна тренировка по всему набору данных, например, когда возникает необходимость в алгоритмах, работающих с внешней памятью. Метод используется также в ситуациях, когда алгоритму приходится динамически приспосабливать новые схемы в данных или когда сами данные образуются как функция от времени, например, при предсказании цен на фондовом рынке. Алгоритмы онлайнового обучения могут быть склонны к катастрофическим помехам, проблеме, которая может быть решена с помощью подхода пошагового обучения.


















