
Нейро́нная сеть — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети У. Маккалока и У. Питтса. После разработки алгоритмов обучения получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др.

Иску́сственный нейро́н — узел искусственной нейронной сети, являющийся упрощённой моделью естественного нейрона. Математически искусственный нейрон обычно представляют как некоторую нелинейную функцию от единственного аргумента — линейной комбинации всех входных сигналов. Данную функцию называют функцией активации или функцией срабатывания, передаточной функцией. Полученный результат посылается на единственный выход. Такие искусственные нейроны объединяют в сети — соединяют выходы одних нейронов с входами других. Искусственные нейроны и сети являются основными элементами идеального нейрокомпьютера.

Нервная сеть — совокупность нейронов головного и спинного мозга центральной нервной системы (ЦНС) и ганглия периферической нервной системы (ПНС), которые связаны или функционально объединены в нервной системе, выполняют специфические физиологические функции.
Нейро́нная сеть Хо́пфилда — полносвязная нейронная сеть с симметричной матрицей связей. В процессе работы динамика таких сетей сходится (конвергирует) к одному из положений равновесия. Эти положения равновесия определяются заранее в процессе обучения, они являются локальными минимумами функционала, называемого энергией сети. Такая сеть может быть использована как автоассоциативная память, как фильтр, а также для решения некоторых задач оптимизации. В отличие от многих нейронных сетей, работающих до получения ответа через определённое количество тактов, сети Хопфилда работают до достижения равновесия, когда следующее состояние сети в точности равно предыдущему: начальное состояние является входным образом, а при равновесии получают выходной образ.
Метод обратного распространения ошибки — метод вычисления градиента, который используется при обновлении весов многослойного перцептрона. Впервые метод был описан в 1974 году Александром Галушкиным, а также независимо и одновременно Полом Вербосом. Далее существенно развит в 1986 году Дэвидом Румельхартом, Джеффри Хинтоном и Рональдом Уильямсом и независимо и одновременно Барцевым и Охониным. Это итеративный градиентный алгоритм, который используется с целью минимизации ошибки работы многослойного перцептрона и получения желаемого выхода.

Перцептро́н — математическая или компьютерная модель восприятия информации мозгом, предложенная Фрэнком Розенблаттом в 1957 году и впервые воплощённая в виде электронной машины «Марк-1» в 1960 году. Перцептрон стал одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером.
Де́льта-пра́вило — метод обучения перцептрона по принципу градиентного спуска по поверхности ошибки. Дельта-правило развилось из первого и второго правил Хебба. Его дальнейшее развитие привело к созданию метода обратного распространения ошибки.

Сжатие данных — одна из задач, решаемых нейронными сетями. Как и любое сжатие, решение данной задачи основано на устранении избыточности информации во входном сигнале (образе).

Многослойный перцептрон — частный случай перцептрона Розенблатта, в котором один алгоритм обратного распространения ошибки обучает все слои. Название по историческим причинам не отражает особенности данного вида перцептрона, то есть не связано с тем, что в нём имеется несколько слоёв. Особенностью является наличие более чем одного обучаемого слоя. Необходимость в большом количестве обучаемых слоёв отпадает, так как теоретически единственного скрытого слоя достаточно, чтобы перекодировать входное представление таким образом, чтобы получить линейную разделимость для выходного представления. Существует предположение, что, используя большее число слоёв, можно уменьшить число элементов в них, то есть суммарное число элементов в слоях будет меньше, чем если использовать один скрытый слой. Это предположение успешно используется в технологиях глубокого обучения и имеет обоснование.
Рекуррентные нейронные сети — вид нейронных сетей, где связи между элементами образуют направленную последовательность. Благодаря этому появляется возможность обрабатывать серии событий во времени или последовательные пространственные цепочки. В отличие от многослойных перцептронов, рекуррентные сети могут использовать свою внутреннюю память для обработки последовательностей произвольной длины. Поэтому сети RNN применимы в таких задачах, где нечто целостное разбито на части, например: распознавание рукописного текста или распознавание речи. Было предложено много различных архитектурных решений для рекуррентных сетей от простых до сложных. В последнее время наибольшее распространение получили сеть с долговременной и кратковременной памятью (LSTM) и управляемый рекуррентный блок (GRU).

Нейро́нная сеть Ко́ско, Двунапра́вленная ассоциати́вная па́мять (ДАП) — нейронная сеть, разработанная Бартом Коско. Это однослойная нейронная сеть с обратными связями, базируется на двух идеях: адаптивной резонансной теории Стефана Гросберга и автоассоциативной памяти Хопфилда.
Нейрокриптография — раздел криптографии, изучающий применение стохастических алгоритмов, в частности, нейронных сетей, для шифрования и криптоанализа.
Перцептрон является одной из первых моделей искусственной нейронной сети. Несмотря на то, что модель предложена Фрэнком Розенблаттом в 1957 году, о её возможностях и ограничениях до сегодняшнего дня не всё известно. В 1969 году Марвин Минский и Сеймур Паперт посвятили критике перцептрона целую книгу, которая показала некоторые принципиальные ограничения одной из разновидности перцептронов.

Свёрточная нейронная сеть — специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном в 1988 году и нацеленная на эффективное распознавание образов, входит в состав технологий глубокого обучения. Использует некоторые особенности зрительной коры, в которой были открыты так называемые простые клетки, реагирующие на прямые линии под разными углами, и сложные клетки, реакция которых связана с активацией определённого набора простых клеток. Таким образом, идея свёрточных нейронных сетей заключается в чередовании свёрточных слоёв и субдискретизирующих слоёв. Структура сети — однонаправленная, принципиально многослойная. Для обучения используются стандартные методы, чаще всего метод обратного распространения ошибки. Функция активации нейронов — любая, по выбору исследователя.
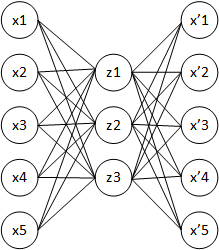
Автокодировщик — специальная архитектура искусственных нейронных сетей, позволяющая применять обучение без учителя при использовании метода обратного распространения ошибки. Простейшая архитектура автокодировщика — сеть прямого распространения, без обратных связей, наиболее схожая с перцептроном и содержащая входной слой, промежуточный слой и выходной слой. В отличие от перцептрона, выходной слой автокодировщика должен содержать столько же нейронов, сколько и входной слой.
Глубокое обучение — совокупность методов машинного обучения, основанных на обучении представлениям, а не специализированных алгоритмах под конкретные задачи. Многие методы глубокого обучения были известны ещё в 1980-е, но результаты не впечатляли, пока продвижения в теории искусственных нейронных сетей и вычислительные мощности середины 2000-х годов не позволили создавать сложные технологические архитектуры нейронных сетей, обладающие достаточной производительностью и позволяющие решать широкий спектр задач, не поддававшихся эффективному решению ранее, например, в компьютерном зрении, машинном переводе, распознавании речи, причём качество решения во многих случаях теперь сопоставимо, а в некоторых превосходит эффективность человека.

Длинная цепь элементов краткосрочной памяти — разновидность архитектуры рекуррентных нейронных сетей, предложенная в 1997 году Зеппом Хохрайтером и Юргеном Шмидхубером. Как и большинство рекуррентных нейронных сетей, LSTM-сеть является универсальной в том смысле, что при достаточном числе элементов сети она может выполнить любое вычисление, на которое способен обычный компьютер, для чего необходима соответствующая матрица весов, которая может рассматриваться как программа. В отличие от традиционных рекуррентных нейронных сетей, LSTM-сеть хорошо приспособлена к обучению на задачах классификации, обработки и прогнозирования временных рядов в случаях, когда важные события разделены временными лагами с неопределённой продолжительностью и границами. Относительная невосприимчивость к длительности временных разрывов даёт LSTM преимущество по отношению к альтернативным рекуррентным нейронным сетям, скрытым марковским моделям и другим методам обучения для последовательностей в различных сферах применения. Из множества достижений LSTM-сетей можно выделить наилучшие результаты в распознавании несегментированного слитного рукописного текста, и победу в 2009 году на соревнованиях по распознаванию рукописного текста (ICDAR). LSTM-сети также используются в задачах распознавания речи, например LSTM-сеть была основным компонентом сети, которая в 2013 году достигла рекордного порога ошибки в 17,7 % в задаче распознавания фонем на классическом корпусе естественной речи TIMIT. По состоянию на 2016 год ведущие технологические компании, включая Google, Apple, Microsoft и Baidu, используют LSTM-сети в качестве фундаментального компонента новых продуктов.

Ограниченная машина Больцмана, сокращённо RBM — вид генеративной стохастической нейронной сети, которая определяет распределение вероятности на входных образцах данных.
Обучение признакам или обучение представлениям — это набор техник, которые позволяют системе автоматически обнаружить представления, необходимые для выявления признаков или классификации исходных (сырых) данных. Это заменяет ручное конструирование признаков и позволяет машине как изучать признаки, так и использовать их для решения специфичных задач.
Нейронная сеть с прямой связью — искусственная нейронная сеть, в которой соединения между узлами не образуют цикл. Такая сеть отличается от рекуррентной нейронной сети. Нейронная сеть с прямой связью была первым и самым простым типом искусственной нейронной сети. В этой сети информация перемещается только в одном направлении вперед от входных узлов, через скрытые узлы и к выходным узлам. В сети нет циклов или петель обратных связей.
