Евкли́дово простра́нство в изначальном смысле — это пространство, свойства которого описываются аксиомами евклидовой геометрии. В этом случае предполагается, что пространство имеет размерность, равную 3, то есть является трёхмерным.

Нейро́нная сеть — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети У. Маккалока и У. Питтса. После разработки алгоритмов обучения получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др.
Нейро́нная сеть Хо́пфилда — полносвязная нейронная сеть с симметричной матрицей связей. В процессе работы динамика таких сетей сходится (конвергирует) к одному из положений равновесия. Эти положения равновесия определяются заранее в процессе обучения, они являются локальными минимумами функционала, называемого энергией сети. Такая сеть может быть использована как автоассоциативная память, как фильтр, а также для решения некоторых задач оптимизации. В отличие от многих нейронных сетей, работающих до получения ответа через определённое количество тактов, сети Хопфилда работают до достижения равновесия, когда следующее состояние сети в точности равно предыдущему: начальное состояние является входным образом, а при равновесии получают выходной образ.
Опера́тор — математическое отображение между множествами, в котором каждое из них наделено какой-либо дополнительной структурой. Понятие оператора используется в различных разделах математики для отличия от другого рода отображений ; точное значение зависит от контекста, например в функциональном анализе под операторами понимают отображения, ставящие в соответствие функции другую функцию.
Метод обратного распространения ошибки — метод вычисления градиента, который используется при обновлении весов многослойного перцептрона. Впервые метод был описан в 1974 году Александром Галушкиным, а также независимо и одновременно Полом Вербосом. Далее существенно развит в 1986 году Дэвидом Румельхартом, Джеффри Хинтоном и Рональдом Уильямсом и независимо и одновременно Барцевым и Охониным. Это итеративный градиентный алгоритм, который используется с целью минимизации ошибки работы многослойного перцептрона и получения желаемого выхода.
Нейронные сети Кохонена — класс нейронных сетей, основным элементом которых является слой Кохонена. Слой Кохонена состоит из адаптивных линейных сумматоров. Как правило, выходные сигналы слоя Кохонена обрабатываются по правилу «Победитель получает всё»: наибольший сигнал превращается в единичный, остальные обращаются в ноль.
Де́льта-пра́вило — метод обучения перцептрона по принципу градиентного спуска по поверхности ошибки. Дельта-правило развилось из первого и второго правил Хебба. Его дальнейшее развитие привело к созданию метода обратного распространения ошибки.
Рекуррентные нейронные сети — вид нейронных сетей, где связи между элементами образуют направленную последовательность. Благодаря этому появляется возможность обрабатывать серии событий во времени или последовательные пространственные цепочки. В отличие от многослойных перцептронов, рекуррентные сети могут использовать свою внутреннюю память для обработки последовательностей произвольной длины. Поэтому сети RNN применимы в таких задачах, где нечто целостное разбито на части, например: распознавание рукописного текста или распознавание речи. Было предложено много различных архитектурных решений для рекуррентных сетей от простых до сложных. В последнее время наибольшее распространение получили сеть с долговременной и кратковременной памятью (LSTM) и управляемый рекуррентный блок (GRU).
VMPC — это потоковый шифр, применяющийся в некоторых системах защиты информации в компьютерных сетях. Шифр разработан криптографом Бартошем Жултаком в качестве усиленного варианта популярного шифра RC4. Алгоритм VMPC строится как и любой потоковый шифр на основе параметризованного ключом генератора псевдослучайных битов. Основные преимущества шифра, как и RC4 — высокая скорость работы, переменный размер ключа и вектора инициализации, простота реализации.
HC-256 — система потокового шифрования, разработанная криптографом У Хунцзюнем из сингапурского Института инфокоммуникационных исследований. Впервые опубликован в 2004 году. 128-битный вариант был представлен на конкурсе eSTREAM, целью которого было создание европейских стандартов для поточных систем шифрования. Алгоритм стал одним из четырёх финалистов конкурса в первом профиле . (англ.)
Моде́ль биологи́ческого нейро́на — математическое описание свойств нейронов, целью которого является точное моделирование процессов, протекающих в таких нервных клетках. В отличие от подобного точного моделирования, при создании сетей из искусственных нейронов обычно преследуются цели повышения эффективности вычислений.
Расширяющийся нейронный газ — «это алгоритм, позволяющий осуществлять адаптивную кластеризацию входных данных, то есть не только разделить пространство на кластеры, но и определить необходимое их количество исходя из особенностей самих данных. Расширяющийся нейронный газ не требует априорной информации о данных, таких как оценка количества кластеров или форма кластеров.» Это новый класс вычислительных механизмов. Количество и расположение искусственных нейронов в пространстве признаков заранее не определено, а является результатом вычисления в процессе обучения моделей на основании данных введенных на входе. В данной модели не фиксировано соседство узлов, а динамически меняется по мере улучшения кластеризации. Переменными являются не только отношения соседства, но и число нейронов-кластеров.

Свёрточная нейронная сеть — специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном в 1988 году и нацеленная на эффективное распознавание образов, входит в состав технологий глубокого обучения. Использует некоторые особенности зрительной коры, в которой были открыты так называемые простые клетки, реагирующие на прямые линии под разными углами, и сложные клетки, реакция которых связана с активацией определённого набора простых клеток. Таким образом, идея свёрточных нейронных сетей заключается в чередовании свёрточных слоёв и субдискретизирующих слоёв. Структура сети — однонаправленная, принципиально многослойная. Для обучения используются стандартные методы, чаще всего метод обратного распространения ошибки. Функция активации нейронов — любая, по выбору исследователя.
Нейро́нная сеть Хэ́мминга (Хемминга) — вид нейронной сети, использующийся для классификации бинарных векторов, основным критерием в которой является расстояние Хэмминга. Является развитием нейронной сети Хопфилда.

Длинная цепь элементов краткосрочной памяти — разновидность архитектуры рекуррентных нейронных сетей, предложенная в 1997 году Зеппом Хохрайтером и Юргеном Шмидхубером. Как и большинство рекуррентных нейронных сетей, LSTM-сеть является универсальной в том смысле, что при достаточном числе элементов сети она может выполнить любое вычисление, на которое способен обычный компьютер, для чего необходима соответствующая матрица весов, которая может рассматриваться как программа. В отличие от традиционных рекуррентных нейронных сетей, LSTM-сеть хорошо приспособлена к обучению на задачах классификации, обработки и прогнозирования временных рядов в случаях, когда важные события разделены временными лагами с неопределённой продолжительностью и границами. Относительная невосприимчивость к длительности временных разрывов даёт LSTM преимущество по отношению к альтернативным рекуррентным нейронным сетям, скрытым марковским моделям и другим методам обучения для последовательностей в различных сферах применения. Из множества достижений LSTM-сетей можно выделить наилучшие результаты в распознавании несегментированного слитного рукописного текста, и победу в 2009 году на соревнованиях по распознаванию рукописного текста (ICDAR). LSTM-сети также используются в задачах распознавания речи, например LSTM-сеть была основным компонентом сети, которая в 2013 году достигла рекордного порога ошибки в 17,7 % в задаче распознавания фонем на классическом корпусе естественной речи TIMIT. По состоянию на 2016 год ведущие технологические компании, включая Google, Apple, Microsoft и Baidu, используют LSTM-сети в качестве фундаментального компонента новых продуктов.

Ограниченная машина Больцмана, сокращённо RBM — вид генеративной стохастической нейронной сети, которая определяет распределение вероятности на входных образцах данных.
Обучение признакам или обучение представлениям — это набор техник, которые позволяют системе автоматически обнаружить представления, необходимые для выявления признаков или классификации исходных (сырых) данных. Это заменяет ручное конструирование признаков и позволяет машине как изучать признаки, так и использовать их для решения специфичных задач.
Структурное прогнозирование, или структурное обучение — собирательный термин для техник машинного обучения с учителем, вовлекающих предвидение структурных объектов, а не скалярных дискретных или вещественных значений.
Языкова́я модель — это распределение вероятностей по последовательностям слов. Для любой последовательности слов длины m языковая модель присваивает вероятность  всей последовательности. Языковые модели генерируют вероятности путём обучения на корпусе текстов на одном или нескольких языках. Учитывая, что языки могут использоваться для выражения огромного множества верных предложений, языковое моделирование сталкивается с проблемой задания ненулевых вероятностей лингвистически верным последовательностям, которые могут никогда не встретиться в обучающих данных. Для преодоления этой проблемы было разработано несколько подходов к моделированию, таких как применение марковских цепей или использование нейронных архитектур, таких как рекуррентные нейронные сети или трансформеры.
всей последовательности. Языковые модели генерируют вероятности путём обучения на корпусе текстов на одном или нескольких языках. Учитывая, что языки могут использоваться для выражения огромного множества верных предложений, языковое моделирование сталкивается с проблемой задания ненулевых вероятностей лингвистически верным последовательностям, которые могут никогда не встретиться в обучающих данных. Для преодоления этой проблемы было разработано несколько подходов к моделированию, таких как применение марковских цепей или использование нейронных архитектур, таких как рекуррентные нейронные сети или трансформеры.
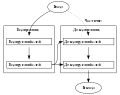 Трансформер
Трансформер Кодирующий слой
Кодирующий слой Декодирующий слой
Декодирующий слой











